






28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 62296位读者 |这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球 #
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
在《鬼斧神工:求n维球的体积》中,我们推导过$n$维球的体积公式,从中可知$n$维单位球的体积为
\begin{equation}V_n = \frac{\pi^{n/2}}{\Gamma\left(\frac{n}{2}+1\right)}\end{equation}
对应的外切正方体边长为$2$,体积自然为$2^n$,所以对应的体积比为$V_n / 2^n$,其图像如下图:
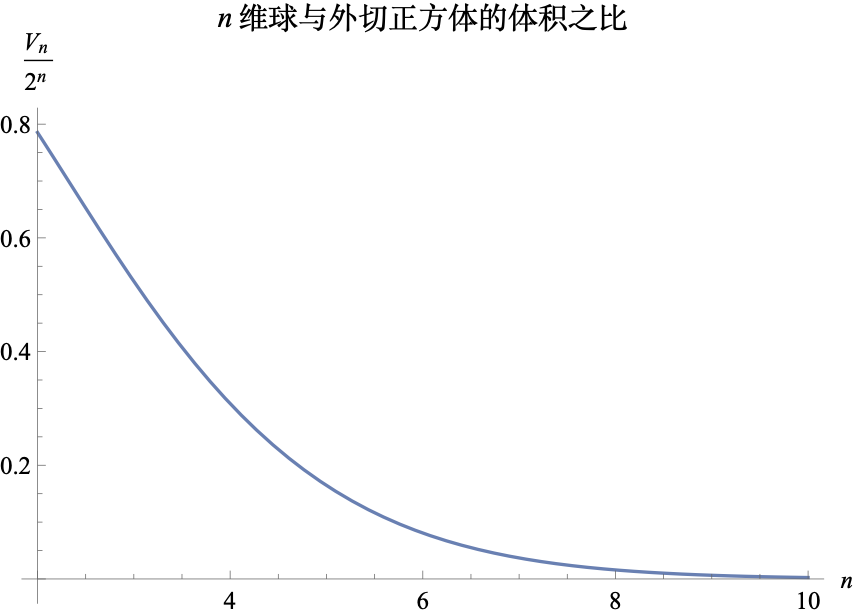
n 维球与外切正方体的体积之比
可以看到,随着维度的增大,这个比例很快就趋于0了。这个结论的一个形象说法是“随着维度增加,球变得越来越微不足道”,它告诉我们,如果通过“均匀分布 + 拒绝采样”的方式去实现球内的均匀采样,那么在高维空间中效率将会非常低(拒绝率接近100%)。还有一种理解方式是“高维球内的点大部分都集中在球表面附近”,球中心到球表面附近的区域占比越来越小。
Hubness现象 #
现在我们转到Hubness现象,它说的是在高维空间中随机选一批点,那么“总有一些点经常出现在其他点的$k$邻近中”。
具体怎么理解这句话呢?假设我们有$N$个点$x_1,x_2,\cdots,x_N$,对于每个$x_i$,我们都可以找出与之最相近的$k$个点,这$k$个点都称为“$x_i$的$k$邻近”。有了$k$邻近的概念后,我们可以统计每个点出现在其他点的$k$邻近的次数,这个次数称为“Hub值”,也就是说Hub值越大,它就越容易出现在其他点的$k$邻近中。
所以,Hubness现象说的是:总有那么几个点,它的Hub值显然特别大。如果Hub值代表着“财富”,那么一个形象的比喻就是“80%的财富集中在20%的人手中”,并且随着维度增大,这个“贫富差距”就越来越大;如果Hub值代表着“人脉”,那么也可以形象地比喻为“社群中总有那么几个人拥有非常广泛的人脉资源”。
Hubness现象是怎么出现的呢?其实也跟前一节说的$n$维球的坍缩有关。我们知道,与所有点距离平方和最小的点,正好是均值点:
\begin{equation}\frac{1}{N} \sum_{i=1}^N x_i = c^* = \mathop{\text{argmin}}_c \sum_{i=1}^N \Vert x_i - c\Vert^2\end{equation}
这也就意味着,在均值向量附近的点,与所有点的平均距离较小,有更大的机会成为更多点的$k$邻近。而$n$维球的坍缩现象则告诉我们,“均值向量附近的点”,即以均值向量为球心的一个球邻域,其占比是非常小的。于是就出现了“非常少的点出现在很多点的$k$邻近中”这一现象了。当然,这里的均值向量是比较直观的理解,在一般的数据点中,应该是越靠近密度中心的点,其Hub值会变得越大。
提升采样 #
那么本文开头说的提升GAN模型生成质量的方案,跟Hubness现象又有什么关系呢?论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》提出了一个先验假设:Hub值越大,对应点的生成质量就越好。
具体来说,一般GAN的采样生成流程是$z\sim \mathcal{N}(0,1), x=G(z)$,我们可以从$\mathcal{N}(0,1)$中先采样$N$个样本点$z_1,z_2,\cdots,z_N$,然后就可以算出每个样本点的Hub值,原论文发现Hub值跟生成质量是正相关的,所以只保留Hub值大于等于阈值$t$的样本点用来做生成。这是一种“事前”的筛选思路,参考代码如下:
def get_z_samples(size, t=50):
"""通过Hub值对采样结果进行筛选
"""
Z = np.empty((0, z_dim))
while len(Z) < size:
z = np.random.randn(10000, z_dim)
s = np.zeros(10000)
for i in range(10):
zi = z[i * 1000:(i + 1) * 1000]
d = (z**2).sum(1)[:, None] + (zi**2).sum(1)[None] - 2 * z.dot(zi.T)
for j in d.argsort(0)[1:1 + 5].T:
s[j] += 1
z = z[s > t]
Z = np.concatenate([Z, z], 0)[:size]
print('%s / %s' % (len(Z), size))
return Z为什么通过Hub值来筛选呢?由前面的讨论可以知道,Hub值越大,那么就越接近样本中心,其实更准确率来说是接近密度中心,意味着周围有很多临近点,那么它就不大可能是没有被充分训练的离群点,因此采样质量相对高一些。论文的多个实验结果肯定了这一结论。

基于Hub值进行筛选的生成质量对比
文章小结 #
本文主要简介了“维度灾难”中的Hubness现象,并介绍了它在提升GAN生成质量方面的应用。
转载到请包括本文地址:https://spaces.ac.cn/archives/9147
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 28, 2022). 《“维度灾难”之Hubness现象浅析 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/9147
@online{kexuefm-9147,
title={“维度灾难”之Hubness现象浅析},
author={苏剑林},
year={2022},
month={Jun},
url={\url{https://spaces.ac.cn/archives/9147}},
}

June 28th, 2022
苏神,这个拒绝采样的结果相当于改变了采样的先验分布($\mathcal{N}(0, 1)$)对吧?那结合“靠近密度中心”这个观点来看的话,是不是就相当于在某种“截断正态”或“聚拢正态”上面采样呢?例如训练的时候根据标准正态采样,生成的时候我就把方差缩小再采样(\摊手.jpg)
June 29th, 2022
苏神,利用Hubness现象来筛选采样点,和直接选取采样点均值附近的若干点来生成图片,有什么区别吗?
很多截断技巧的思想都是相似的,所以你问我“有什么区别”,我只能说它们就是不同的方法和流程,而思想上没有本质区别,哪个更好我也不清楚。我只是介绍Hubness现象,顺带介绍它这个应用。
June 30th, 2022
很可能使用小很多的初始变量维度就能大幅提升性能。参加论文 https://arxiv.org/abs/2110.04627
我想到降低维度的想法的时候也是考虑的类似的问题。一试,这个反直觉的方法竟然效果非常之好!
在有些setting中降低隐空间维度确实是一个简单有限的提点方法。
你是说隐变量的维度降低吗?那确实有可能可行,减少了冗余维度。感谢推荐。
还要加上l2 normalization.具体可以见论文
July 27th, 2022
想到了一个直观的理解n维球坍缩的方式,不知是否合理:假设某一点在一个维度上落入球体的概率为0.99,那么,在n维上,这个点落入球体的概率就是0.99^n, 当n越大,这个概率就趋近于0。(应该不够严谨,感觉比较直观)
今天刚接触ZSL,第一次听到Hubness问题,没想到在苏神这边看到了分享,真巧~
简单理解尚可,但事实上降低的速度远远快于指数下降。
November 17th, 2022
> 任何两个向量机几乎”
向量?
嗯嗯,谢谢,已修正。