






28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 19655位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。
7
Feb
你的CRF层的学习率可能不够大
By 苏剑林 | 2020-02-07 | 81918位读者 | 引用CRF是做序列标注的经典方法,它理论优雅,实际也很有效,如果还不了解CRF的读者欢迎阅读旧作《简明条件随机场CRF介绍(附带纯Keras实现)》。在BERT模型出来之后,也有不少工作探索了BERT+CRF用于序列标注任务的做法。然而,很多实验结果显示(比如论文《BERT Meets Chinese Word Segmentation》)不管是中文分词还是实体识别任务,相比于简单的BERT+Softmax,BERT+CRF似乎并没有带来什么提升,这跟传统的BiLSTM+CRF或CNN+CRF的模型表现并不一样。

基于CRF的4标签分词模型示意图
这两天给bert4keras增加了用CRF做中文分词的例子(task_sequence_labeling_cws_crf.py),在调试过程中发现了CRF层可能存在学习不充分的问题,进一步做了几个对比实验,结果显示这可能是CRF在BERT中没什么提升的主要原因,遂在此记录一下分析过程,与大家分享。
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 152854位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
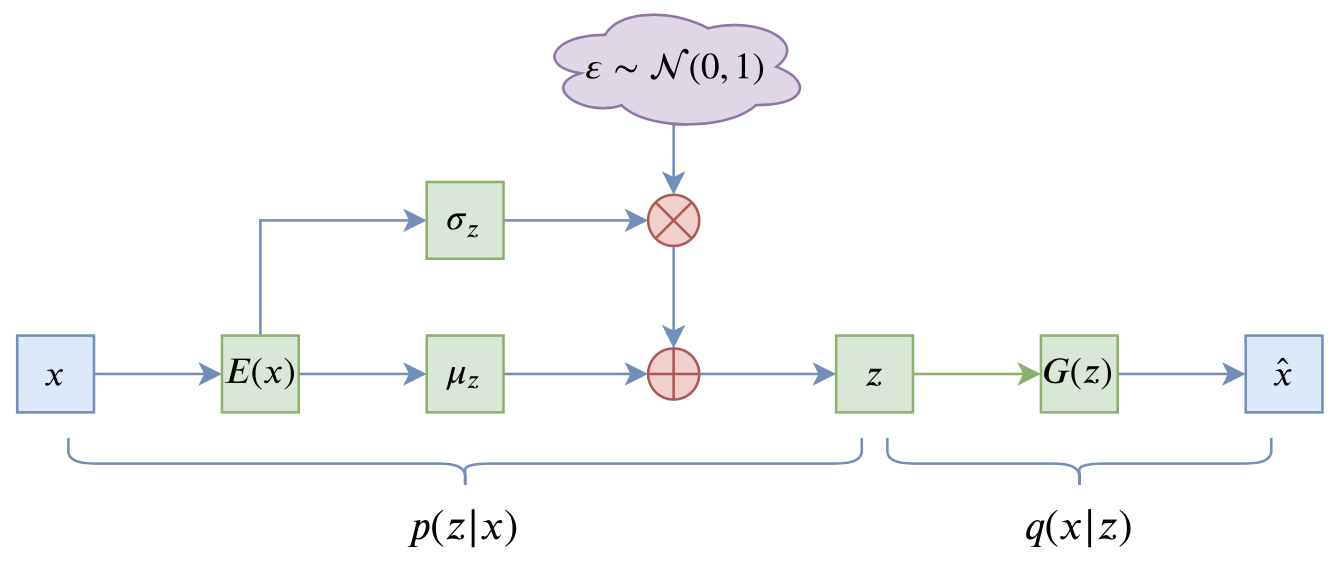
VAE训练流程图示
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 546396位读者 | 引用
25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 61418位读者 | 引用经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.
17
Jun
OCR技术浅探:2. 背景与假设
By 苏剑林 | 2016-06-17 | 32624位读者 | 引用研究背景
关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件.
然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进.
综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 我们队伍将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究假设
在本文中,我们假设图像的文字部分有以下的特征:
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 357335位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
26
Jun

最近评论