






26
Sep
脑洞大开:非线性RNN居然也可以并行计算?
By 苏剑林 | 2023-09-26 | 57336位读者 | 引用近年来,线性RNN由于其可并行训练以及常数推理成本等特性,吸引了一定研究人员的关注(例如笔者之前写的《Google新作试图“复活”RNN:RNN能否再次辉煌?》),这让RNN在Transformer遍地开花的潮流中仍有“一席之地”。然而,目前看来这“一席之地”只属于线性RNN,因为非线性RNN无法高效地并行训练,所以在架构之争中是“心有余而力不足”。
不过,一篇名为《Parallelizing Non-Linear Sequential Models over the Sequence Length》的论文有不同的看法,它提出了一种迭代算法,宣传可以实现非线性RNN的并行训练!真有如此神奇?接下来我们一探究竟。
求不动点
原论文对其方法做了非常一般的介绍,而且其侧重点是PDE和ODE,这里我们直接从RNN入手。考虑常见的简单非线性RNN:
\begin{equation}x_t = \tanh(Ax_{t-1} + u_t)\label{eq:rnn}\end{equation}
11
Oct
低秩近似之路(三):CR
By 苏剑林 | 2024-10-11 | 17583位读者 | 引用在《低秩近似之路(二):SVD》中,我们证明了SVD可以给出任意矩阵的最优低秩近似。那里的最优近似是无约束的,也就是说SVD给出的结果只管误差上的最小,不在乎矩阵的具体结构,而在很多应用场景中,出于可解释性或者非线性处理等需求,我们往往希望得到具有某些特殊结构的近似分解。
因此,从这篇文章开始,我们将探究一些具有特定结构的低秩近似,而本文将聚焦于其中的CR近似(Column-Row Approximation),它提供了加速矩阵乘法运算的一种简单方案。
问题背景
矩阵的最优$r$秩近似的一般提法是
\begin{equation}\mathop{\text{argmin}}_{\text{rank}(\tilde{\boldsymbol{M}})\leq r}\Vert \tilde{\boldsymbol{M}} - \boldsymbol{M}\Vert_F^2\label{eq:loss-m2}\end{equation}
11
Jun
用PyPy提高Python脚本执行效率
By 苏剑林 | 2014-06-11 | 23806位读者 | 引用在《两百万前素数之和与前两百万素数之和》中,我们用Python求了前两百万的素数和以及两百万前的素数和,并且得到了在Python 3.3中的执行时间如下:
两百万前的素数之和:
142913828922
time: 2.4048174478605646前两百万的素数之和:
31381137530481
time: 46.75734807838953
于是想办法提高python脚本的执行效率,我觉得在算法方面,优化空间已经比较小了,于是考虑执行器上的优化。在搜索的无意间我看到了一个名词——Psyco!这是python的一个外部模块,导入后可以加快.py脚本的执行。网上也有《用 Psyco 让 Python 运行得像 C一样快》、《利用 psyco 让 Python 程序执行更快》之类的文章,说明Psyco确实是一个可行的选择,于是就跃跃欲试了,后来了解到Psyco在2012年已经停止开发,只支持到Python 2.4版本,目前它由 PyPy所接替。于是我就下载了PyPy。
10
Jun
两百万前素数之和与前两百万素数之和
By 苏剑林 | 2014-06-10 | 71549位读者 | 引用
2
Jul
[追溯]封装界传奇人物
By 苏剑林 | 2014-07-02 | 19501位读者 | 引用转载理由:现在的deepin和ylmf(已经改为StartOs)都已经在制作自己的Linux,而当初它们都是制作GhostXp的大家。我的初中,即2009年以前,是GhostXP流行的时代,而我当时也加入了这一行列中,发表过一些GhostXP的作品。后来随着时代的发展,XP也就慢慢退出了舞台。我也就随之退出了这个舞台,也因此得以专注科学。但是,几乎所有我的电脑知识,都积累于那个时期,因为为了完成一个系统的制作和推广,需要懂得的电脑技术很多很多,我也得到了充分的锻炼。下面列举的一些人,都是当年GhostXP界的神话人物,有些我并不认识,但其名在当时就如雷贯耳;有些人在当时还十分幸运地加上了他们的QQ。这篇文章实际上已经是很久已经的了,但还是值得回味过去的时间,以此为我的初中时代留下一些回忆。
13
Feb
Designing GANs:又一个GAN生产车间
By 苏剑林 | 2020-02-13 | 34366位读者 | 引用在2018年的文章里《f-GAN简介:GAN模型的生产车间》笔者介绍了f-GAN,并评价其为GAN模型的“生产车间”,顾名思义,这是指它能按照固定的流程构造出很多不同形式的GAN模型来。前几天在arxiv上看到了新出的一篇论文《Designing GANs: A Likelihood Ratio Approach》(后面简称Designing GANs或原论文),发现它在做跟f-GAN同样的事情,但走的是一条截然不同的路(不过最后其实是殊途同归),整篇论文颇有意思,遂在此分享一番。
f-GAN回顾
从《f-GAN简介:GAN模型的生产车间》中我们可以知道,f-GAN的首要步骤是找到满足如下条件的函数$f$:
1、$f$是非负实数到实数的映射($\mathbb{R}^* \to \mathbb{R}$);
2、$f(1)=0$;
3、$f$是凸函数。
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 70666位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 229725位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
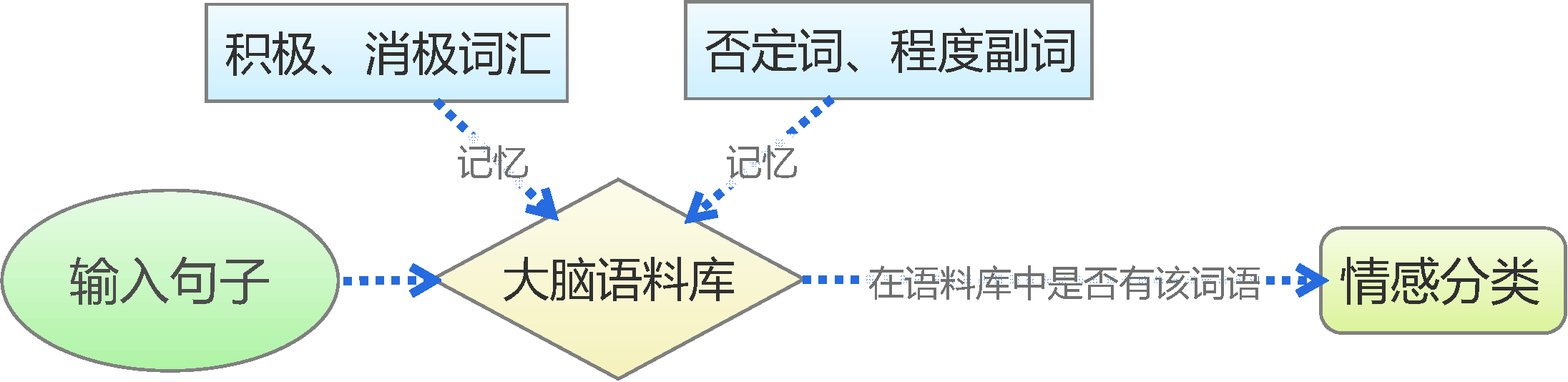
人的最简单的判断思维

最近评论