






27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 100556位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
20
Jan
从Wasserstein距离、对偶理论到WGAN
By 苏剑林 | 2019-01-20 | 205883位读者 | 引用
推土机哪家强?成本最低找Wasserstein
2017年的时候笔者曾写过博文《互怼的艺术:从零直达WGAN-GP》,从一个相对通俗的角度来介绍了WGAN,在那篇文章中,WGAN更像是一个天马行空的结果,而实际上跟Wasserstein距离没有多大关系。
在本篇文章中,我们再从更数学化的视角来讨论一下WGAN。当然,本文并不是纯粹地讨论GAN,而主要侧重于Wasserstein距离及其对偶理论的理解。本文受启发于著名的国外博文《Wasserstein GAN and the Kantorovich-Rubinstein Duality》,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。不管怎样,在此先对前辈及前辈的文章表示致敬。
(注:完整理解本文,应该需要多元微积分、概率论以及线性代数等基础知识。还有,本文确实长,数学公式确实多,但是,真的不复杂、不难懂,大家不要看到公式就吓怕了~)
6
Mar
O-GAN:简单修改,让GAN的判别器变成一个编码器!
By 苏剑林 | 2019-03-06 | 242067位读者 | 引用本文来给大家分享一下笔者最近的一个工作:通过简单地修改原来的GAN模型,就可以让判别器变成一个编码器,从而让GAN同时具备生成能力和编码能力,并且几乎不会增加训练成本。这个新模型被称为O-GAN(正交GAN,即Orthogonal Generative Adversarial Network),因为它是基于对判别器的正交分解操作来完成的,是对判别器自由度的最充分利用。

FFHQ线性插值效果图
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 98136位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 83141位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 86183位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 111763位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
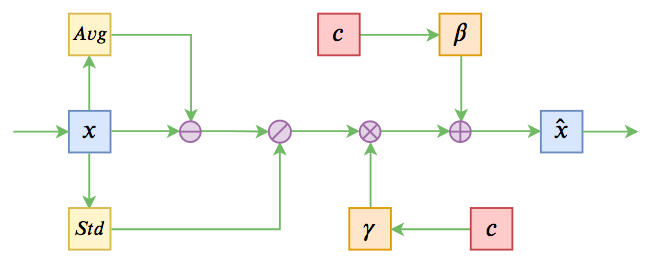
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
3
May
从动力学角度看优化算法(四):GAN的第三个阶段
By 苏剑林 | 2019-05-03 | 93632位读者 | 引用在对GAN的学习和思考过程中,我发现我不仅学习到了一种有效的生成模型,而且它全面地促进了我对各种模型各方面的理解,比如模型的优化和理解视角、正则项的意义、损失函数与概率分布的联系、概率推断等等。GAN不单单是一个“造假的玩具”,而是具有深刻意义的概率模型和推断方法。
作为事后的总结,我觉得对GAN的理解可以粗糙地分为三个阶段:
1、样本阶段:在这个阶段中,我们了解了GAN的“鉴别者-造假者”诠释,懂得从这个原理出发来写出基本的GAN公式(如原始GAN、LSGAN),比如判别器和生成器的loss,并且完成简单GAN的训练;同时,我们知道GAN有能力让图片更“真”,利用这个特性可以把GAN嵌入到一些综合模型中。
2、分布阶段:在这个阶段中,我们会从概率分布及其散度的视角来分析GAN,典型的例子是WGAN和f-GAN,同时能基本理解GAN的训练困难问题,比如梯度消失和mode collapse等,甚至能基本地了解变分推断,懂得自己写出一些概率散度,继而构造一些新的GAN形式。
3、动力学阶段:在这个阶段中,我们开始结合优化器来分析GAN的收敛过程,试图了解GAN是否能真的达到理论的均衡点,进而理解GAN的loss和正则项等因素如何影响的收敛过程,由此可以针对性地提出一些训练策略,引导GAN模型到达理论均衡点,从而提高GAN的效果。

最近评论