






22
Apr
Transformer升级之路:3、从Performer到线性Attention
By 苏剑林 | 2021-04-22 | 58269位读者 | 引用看过笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Performer:用随机投影将Attention的复杂度线性化》的读者,可能会觉得本文的标题有点不自然,因为是先有线性Attention然后才有Performer的,它们的关系为“Performer是线性Attention的一种实现,在保证线性复杂度的同时保持了对标准Attention的近似”,所以正常来说是“从线性Attention到Performer”才对。
然而,本文并不是打算梳理线性Attention的发展史,而是打算反过来思考Performer给线性Attention所带来的启示,所以是“从Performer到线性Attention”。
激活函数
线性Attention的常见形式是
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
20
Nov
Transformer升级之路:15、Key归一化助力长度外推
By 苏剑林 | 2023-11-20 | 56755位读者 | 引用大体上,我们可以将目前Transformer的长度外推技术分为两类:一类是事后修改,比如NTK-RoPE、YaRN、ReRoPE等,这类方法的特点是直接修改推理模型,无需微调就能达到一定的长度外推效果,但缺点是它们都无法保持模型在训练长度内的恒等性;另一类自然是事前修改,如ALIBI、KERPLE、XPOS以及HWFA等,它们可以不加改动地实现一定的长度外推,但相应的改动需要在训练之前就引入,因此无法不微调地用于现成模型,并且这类方法是否能够Scale Up还没得到广泛认可。
在这篇文章中,笔者将介绍一种意外发现的长度外推方案——“KeyNorm”——对Attention的Key序列做L2 Normalization,很明显它属于事前修改一类,但对Attention机制的修改非常小,因此看上去非常有希望能够Scale Up。
最初动机
之所以说“意外发现”,是因为该改动的原始动机并不是长度外推,而是尝试替换Scaled Dot-Product Attention中的Scale方式。我们知道,Attention的标准定义是(本文主要考虑Causal场景)
\begin{equation}\boldsymbol{o}_i = \frac{\sum_{j = 1}^i\exp\left(\frac{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}{\sqrt{d}}\right)\boldsymbol{v}_j}{\sum_{j = 1}^i\exp\left(\frac{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}{\sqrt{d}}\right)},\quad \boldsymbol{q}_i,\boldsymbol{k}_j\in\mathbb{R}^d\label{eq:sdpa}\end{equation}
14
Jun
通向概率分布之路:盘点Softmax及其替代品
By 苏剑林 | 2024-06-14 | 30075位读者 | 引用不论是在基础的分类任务中,还是如今无处不在的注意力机制中,概率分布的构建都是一个关键步骤。具体来说,就是将一个$n$维的任意向量,转换为一个$n$元的离散型概率分布。众所周知,这个问题的标准答案是Softmax,它是指数归一化的形式,相对来说比较简单直观,同时也伴有很多优良性质,从而成为大部分场景下的“标配”。
尽管如此,Softmax在某些场景下也有一些不如人意之处,比如不够稀疏、无法绝对等于零等,因此很多替代品也应运而生。在这篇文章中,我们将简单总结一下Softmax的相关性质,并盘点和对比一下它的部分替代方案。
Softmax回顾
首先引入一些通用记号:$\boldsymbol{x} = (x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$是需要转为概率分布的$n$维向量,它的分量可正可负,也没有限定的上下界。$\Delta^{n-1}$定义为全体$n$元离散概率分布的集合,即
\begin{equation}\Delta^{n-1} = \left\{\boldsymbol{p}=(p_1,p_2,\cdots,p_n)\left|\, p_1,p_2,\cdots,p_n\geq 0,\sum_{i=1}^n p_i = 1\right.\right\}\end{equation}
之所以标注$n-1$而不是$n$,是因为约束$\sum\limits_{i=1}^n p_i = 1$定义了$n$维空间中的一个$n-1$维子平面,再加上$p_i\geq 0$的约束,$(p_1,p_2,\cdots,p_n)$的集合就只是该平面的一个子集,即实际维度只有$n-1$。
9
Aug
线性Transformer应该不是你要等的那个模型
By 苏剑林 | 2021-08-09 | 105212位读者 | 引用在本博客中,我们已经多次讨论过线性Attention的相关内容。介绍线性Attention的逻辑大体上都是:标准Attention具有$\mathcal{O}(n^2)$的平方复杂度,是其主要的“硬伤”之一,于是我们$\mathcal{O}(n)$复杂度的改进模型,也就是线性Attention。有些读者看到线性Attention的介绍后,就一直很期待我们发布基于线性Attention的预训练模型,以缓解他们被BERT的算力消耗所折腾的“死去活来”之苦。
然而,本文要说的是:抱有这种念头的读者可能要失望了,标准Attention到线性Attention的转换应该远远达不到你的预期,而BERT那么慢的原因也并不是因为标准Attention的平方复杂度。
BERT之反思
按照直观理解,平方复杂度换成线性复杂度不应该要“突飞猛进”才对嘛?怎么反而“远远达不到预期”?出现这个疑惑的主要原因,是我们一直以来都没有仔细评估一下常规的Transformer模型(如BERT)的整体计算量。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 185805位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
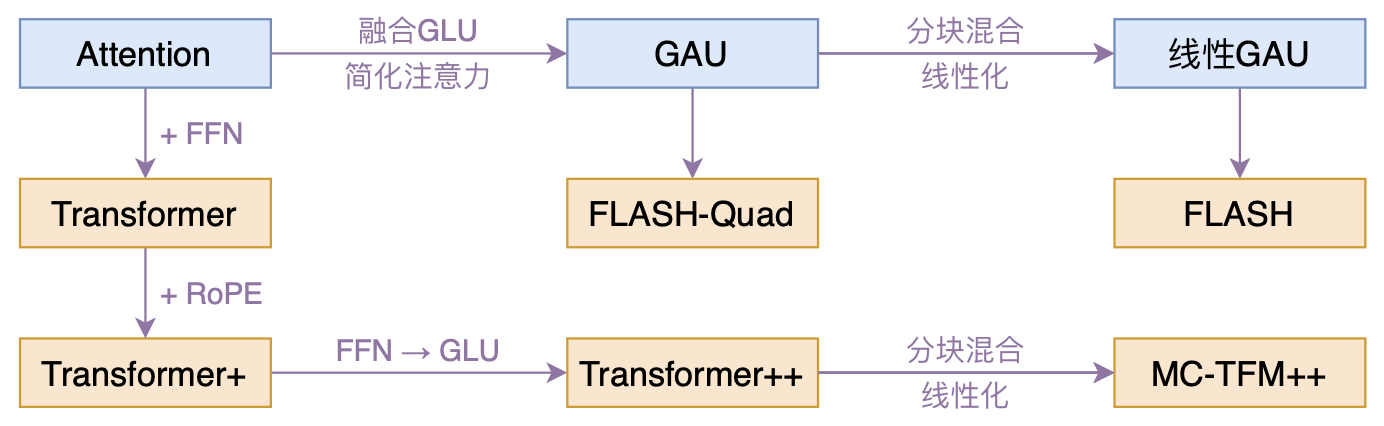
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
29
Nov
我在Performer中发现了Transformer-VQ的踪迹
By 苏剑林 | 2023-11-29 | 47282位读者 | 引用前些天我们在《VQ一下Key,Transformer的复杂度就变成线性了》介绍了“Transformer-VQ”,这是通过将Key序列做VQ(Vector Quantize)变换来实现Attention复杂度线性化的方案。诚然,Transformer-VQ提供了标准Attention到线性Attentino的一个非常漂亮的过渡,给人一种“大道至简”的美感,但熟悉VQ的读者应该能感觉到,当编码表大小或者模型参数量进一步增加时,VQ很可能会成为效果提升的瓶颈,因为它通过STE(Straight-Through Estimator)估计的梯度大概率是次优的(FSQ的实验结果也算是提供了一些佐证)。此外,Transformer-VQ为了使训练效率也线性化所做的梯度截断,也可能成为将来的效果瓶颈之一。
为此,笔者花了一些时间思考可以替代掉VQ的线性化思路。从Transformer-VQ的$\exp\left(QC^{\top}\right)$形式中,笔者联想到了Performer,继而“顺藤摸瓜”地发现原来Performer可以视为Soft版的Transformer-VQ。进一步地,笔者尝试类比Performer的推导方法来重新导出Transformer-VQ,为其后的优化提供一些参考结果。
9
Nov
VQ一下Key,Transformer的复杂度就变成线性了
By 苏剑林 | 2023-11-09 | 69180位读者 | 引用Efficient Transformer,泛指一切致力于降低Transformer的二次复杂度的工作,开始特指针对Attention的改进,后来更一般的思路,如傅里叶变换、线性RNN等,也被归入这个范畴。不得不说,为了降低Transformer的二次复杂度,各路大牛可谓是“八仙过海,各显神通”,各种神奇的思路“百花齐放”,笔者也从中学习到了不少理论知识。然而,尽管Efficient Transformer在理论上是精彩的,但实际上该领域一直都是不愠不火的状态,并没有实际表现十分出色的模型,在LLM火爆的今天,甚至已经逐渐淡出了大家的视野,也淡出了笔者的兴趣范围。
不过,最近有一篇论文《Transformer-VQ: Linear-Time Transformers via Vector Quantization》,却让笔者为之拍案叫绝。作者非常高明地洞察到,只需要对标准Attention的Key做一下VQ(Vector Quantize),复杂度就会自动降低为线性!这种线性化思路保留了标准Attention的形式,是标准Attention到线性Attention的一个完美过渡,同时最大程度上保留了标准Attention的能力。
高效难题
说起来,本站也算是比较早关注Efficient Transformer相关工作了,最早可以追溯到2019年解读Sparse Transformer的一篇博客《为节约而生:从标准Attention到稀疏Attention》。此后,陆续写的关于Efficient Transformer的其他博文还有
6
Sep
“闭门造车”之多模态思路浅谈(三):位置编码
By 苏剑林 | 2024-09-06 | 47076位读者 | 引用在前面的文章中,我们曾表达过这样的观点:多模态LLM相比纯文本LLM的主要差异在于,前者甚至还没有形成一个公认为标准的方法论。这里的方法论,不仅包括之前讨论的生成和训练策略,还包括一些基础架构的设计,比如本文要谈的“多模态位置编码”。
对于这个主题,我们之前在《Transformer升级之路:17、多模态位置编码的简单思考》就已经讨论过一遍,并且提出了一个方案(RoPE-Tie)。然而,当时笔者对这个问题的思考仅处于起步阶段,存在细节考虑不周全、认识不够到位等问题,所以站在现在的角度回看,当时所提的方案与完美答案还有明显的距离。
因此,本文我们将自上而下地再次梳理这个问题,并且给出一个自认为更加理想的结果。
多模位置
多模态模型居然连位置编码都没有形成共识,这一点可能会让很多读者意外,但事实上确实如此。对于文本LLM,目前主流的位置编码是RoPE(RoPE就不展开介绍了,假设读者已经熟知),更准确来说是RoPE-1D,因为原始设计只适用于1D序列。后来我们推导了RoPE-2D,这可以用于图像等2D序列,按照RoPE-2D的思路我们可以平行地推广到RoPE-3D,用于视频等3D序列。

最近评论