






29
Oct
用ALBERT和ELECTRA之前,请确认你真的了解它们
By 苏剑林 | 2020-10-29 | 71490位读者 | 引用在预训练语言模型中,ALBERT和ELECTRA算是继BERT之后的两个“后起之秀”。它们从不同的角度入手对BERT进行了改进,最终提升了效果(至少在不少公开评测数据集上是这样),因此也赢得了一定的口碑。但在平时的交流学习中,笔者发现不少朋友对这两个模型存在一些误解,以至于在使用过程中浪费了不必要的时间。在此,笔者试图对这两个模型的一些关键之处做下总结,供大家参考,希望大家能在使用这两个模型的时候少走一些弯路。

ALBERT与ELECTRA
(注:本文中的“BERT”一词既指开始发布的BERT模型,也指后来的改进版RoBERTa,我们可以将BERT理解为没充分训练的RoBERTa,将RoBERTa理解为更充分训练的BERT。本文主要指的是它跟ALBERT和ELECTRA的对比,因此不区分BERT和RoBERTa。)
22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 86997位读者 | 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 66122位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
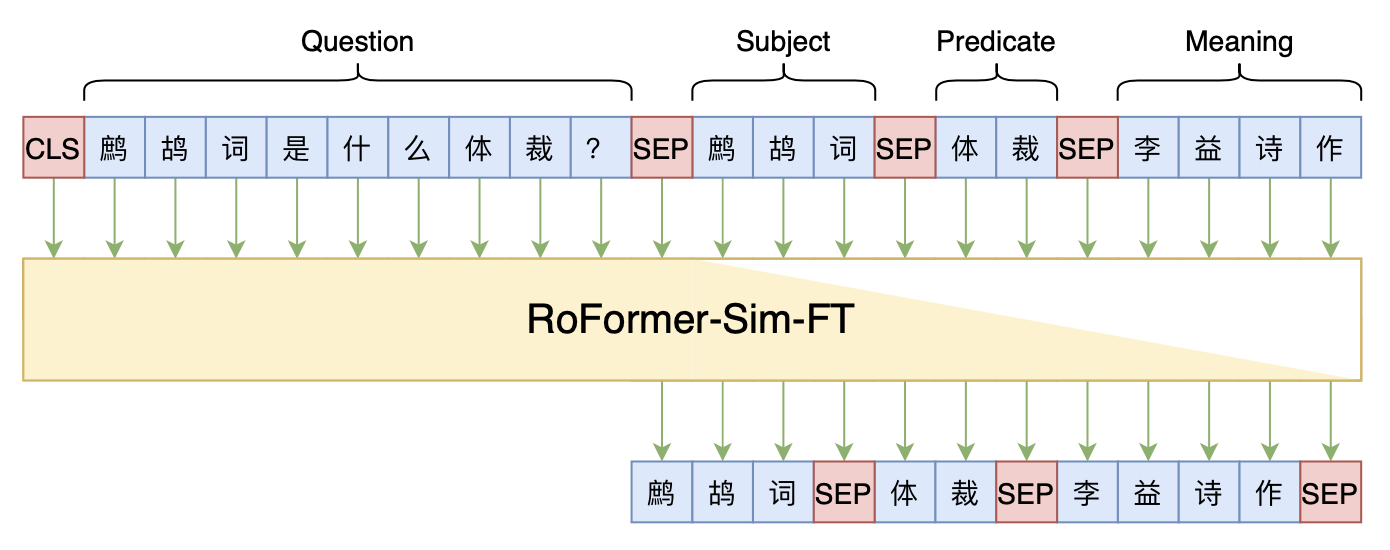
本文baseline模型示意图
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 77742位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
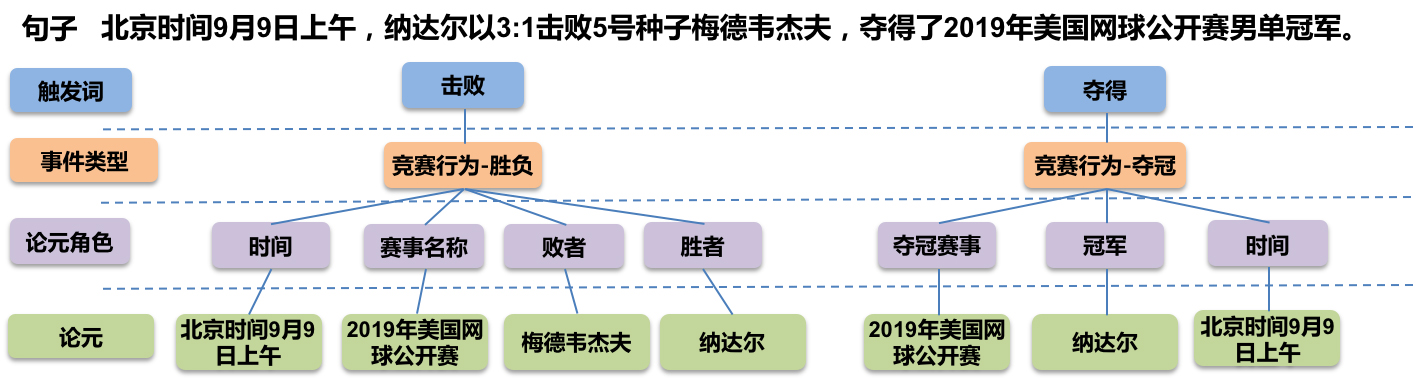
标准的事件抽取样本(图片来自百度DuEE的GitHub)
7
Jun
相对位置编码Transformer的一个理论缺陷与对策
By 苏剑林 | 2022-06-07 | 94748位读者 | 引用位置编码是Transformer中很重要的一环,在《让研究人员绞尽脑汁的Transformer位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将Transformer的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多NLP/CV的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在Softmax之前的Attention矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得Transformer无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。
简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射 \begin{equation}\begin{array}{lc} \text{输入:} & [0, 0, \cdots, 0, 0] \\ & \downarrow\\ \text{输出:} & [1, 2, \cdots, n-1, n] \end{array}\end{equation}
28
Aug
Lion/Tiger优化器训练下的Embedding异常和对策
By 苏剑林 | 2023-08-28 | 30178位读者 | 引用打从在《Tiger:一个“抠”到极致的优化器》提出了Tiger优化器之后,Tiger就一直成为了我训练模型的“标配”优化器。最近笔者已经尝试将Tiger用到了70亿参数模型的预训练之中,前期效果看上来尚可,初步说明Tiger也是能Scale Up的。不过,在查看训练好的模型权重时,笔者发现Embedding出现了一些异常值,有些Embedding的分量达到了$\pm 100$的级别。
经过分析,笔者发现类似现象并不会在Adam中出现,这是Tiger或者Lion这种带符号函数$\text{sign}$的优化器特有的问题,对此文末提供了两种参考解决方案。本文将记录笔者的分析过程,供大家参考。
现象
接下来,我们的分析都以Tiger优化器为例,但分析过程和结论同样适用于Lion。
7
Dec
生成扩散模型漫谈(二十一):中值定理加速ODE采样
By 苏剑林 | 2023-12-07 | 75988位读者 | 引用在生成扩散模型的发展史上,DDIM和同期Song Yang的扩散SDE都称得上是里程碑式的工作,因为它们建立起了扩散模型与随机微分方程(SDE)、常微分方程(ODE)这两个数学领域的紧密联系,从而允许我们可以利用SDE、ODE已有的各种数学工具来对分析、求解和拓展扩散模型,比如后续大量的加速采样工作都以此为基础,可以说这打开了生成扩散模型的一个全新视角。
本文我们聚焦于ODE。在本系列的(六)、(十二)、(十四)、(十五)、(十七)等博客中,我们已经推导过ODE与扩散模型的联系,本文则对扩散ODE的采样加速做简单介绍,并重点介绍一种巧妙地利用“中值定理”思想的新颖采样加速方案“AMED”。
欧拉方法
正如前面所说,我们已经有多篇文章推导过扩散模型与ODE的联系,所以这里不重复介绍,而是直接将扩散ODE的采样定义为如下ODE的求解:
\begin{equation}\frac{d\boldsymbol{x}_t}{dt} = \boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)\label{eq:dm-ode}\end{equation}
31
Jan
幂等生成网络IGN:试图将判别和生成合二为一的GAN
By 苏剑林 | 2024-01-31 | 43471位读者 | 引用前段时间,一个名为“幂等生成网络(Idempotent Generative Network,IGN)”的生成模型引起了一定的关注。它自称是一种独立于已有的VAE、GAN、flow、Diffusion之外的新型生成模型,并且具有单步采样的特点。也许是大家苦于当前主流的扩散模型的多步采样生成过程久矣,因此任何声称可以实现单步采样的“风吹草动”都很容易吸引人们的关注。此外,IGN名称中的“幂等”一词也增加了它的神秘感,进一步扩大了人们的期待,也成功引起了笔者的兴趣,只不过之前一直有别的事情要忙,所以没来得及认真阅读模型细节。
最近闲了一点,想起来还有个IGN没读,于是重新把论文翻了出来,但阅读之后却颇感困惑:这哪里是个新模型,不就是个GAN的变种吗?跟常规GAN不同的是,它将生成器和判别器合二为一了。那这个“合二为一”是不是有什么特别的好处,比如训练更稳定?个人又感觉没有。下面将分享笔者从GAN角度理解IGN的过程和疑问。
生成对抗
关于GAN(Generative Adversarial Network,生成对抗网络),笔者前几年系统地学习过一段时间(查看GAN标签可以查看到相关文章),但近几年没有持续地关注了,因此这里先对GAN做个简单的回顾,也方便后续章节中我们对比GAN与IGN之间的异同。

最近评论