






18
Jan
当大数据进入厨房:让大数据教你做菜!
By 苏剑林 | 2016-01-18 | 42101位读者 | 引用说在前面

美食(图片来源于互联网)
在空间侧边栏的笔者的自我介绍中,有一行是“厨房爱好者”,虽然笔者不怎么会做菜,但确实,厨房是我的一个爱好。当然,笔者的爱好很多,数学、物理、天文、计算机等,都喜欢,都想学,弄到多而不精。在之前的文章中也已经提到过,数据挖掘也是我的一个爱好,而当数据挖掘跟厨房这两个爱好相遇了,会有什么有趣的结果吗?
笔者正是做了这样一个事情:从美食中国的家常菜目录下面,写了个简单的爬虫,抓取了一批菜谱数据下来,进行简单的数据分析。(在此对美食中国表示衷心感谢。选择美食中国的原因是它的数据比较规范。)数据分析在我目前公司的高性能服务器做,分析起来特别舒服~~
这里共收集了18209个菜谱,共包含了9700种食材(包括主料、辅料、调料,部分可能由于命名不规范等原因会重复)。当然,这个数据量相对于很多领域的大数据标准来说,实在不值一提。但是在大数据极少涉及的厨房,应该算是比较多的了。
30
May
路径积分系列:1.我的毕业论文
By 苏剑林 | 2016-05-30 | 28112位读者 | 引用之前承诺过会把毕业论文共享出来,让大家批评指正,却一直偷懒没动。事实上,毕业论文的主要内容就是路径积分的一些入门级别的内容,标题为《随机游走、随机微分方程与偏微分方程的路径积分方法》。我的摘要是这样写的:
本文从随机游走模型出发,得到了关于随机游走模型的一般结果;然后基于随机游走模型引入了路径积分,并且通过路径积分方法,实现了随机游走、随机微分方程与抛物型微分方程的相互转化,并给出了一些计算案例.
路径积分方法是量子理论的一种形式,但实际上它可以抽象为一个有用的数学工具,本文的主要方法正是抽象后的路径积分;其次,量子力学中有一个相当典型的抛物型偏微分方程——薛定谔方程,物理学家已经对它进行了大量的研究,有众多的成果;而随机微分方程是一个微分方程的拓展,在物理、工程、金融等很多方面都有重要应用,这个领域中也有很多研究方法;最后,随机游走是一个简单而重要的模型,它是很多扩散模型的基础,而且具有容易使用计算机模拟的特性. 因此,实现三者的转化是很有意义的.
本文有一些新的内容,比如现有文献比较少研究的不对称随机游走方面、以及现有文献比较含糊的对路径积分的介绍等,可以供同好参考,希望借此方式,能够让一些读者以更简洁明了的方式理解路径积分. 但是本文主要是陈述性的,旨在在国内推广路径积分方法. 在国外,路径积分方法得到了相当的重视,它源于量子力学,但应用已经不仅仅限于量子力学,如著作[1],因此,推广路径积分方法、增加路径积分的中文资料,是很有意义和很有必要的事情.
本文所有推导和例子均以一维为例,相应的多维问题可以类似地计算。
2
Jun
路径积分系列:3.路径积分
By 苏剑林 | 2016-06-02 | 73545位读者 | 引用路径积分是量子力学的一种描述方法,源于物理学家费曼[5],它是一种泛函积分,它已经成为现代量子理论的主流形式. 近年来,研究人员对它的兴趣愈发增加,尤其是它在量子领域以外的应用,出现了一些著作,如[7]. 但在国内了解路径积分的人并不多,很多量子物理专业的学生可能并没有听说过路径积分.
从数学角度来看,路径积分是求偏微分方程的Green函数的一种方法. 我们知道,在偏微分方程的研究中,如果能够求出对应的Green函数,那么对偏微分方程的研究会大有帮助,而通常情况下Green函数并不容易求解. 但构建路径积分只需要无穷小时刻的Green函数,因此形式和概念上都相当简单.
本章并没有新的内容,只是做了一个尝试:从随机游走问题出发,给出路径积分的一个简明而直接的介绍,展示了如何将抛物型的偏微分方程问题转化为路径积分形式.
从点的概率到路径的概率
在上一章对随机游走的研究中,我们得出从$x_0$出发,$t$时间后,走到$x_n$处的概率密度为
$$\frac{1}{\sqrt{2\pi \alpha T}}\exp\left(-\frac{(x_n-x_0)^2}{2\alpha t}\right).\tag{22}$$
这是某时刻某点到另一个时刻另一点的概率,在数学上,我们称之为扩散方程$(21)$的传播子,或者Green函数.
26
Jun
OCR技术浅探:9. 代码共享(完)
By 苏剑林 | 2016-06-26 | 67837位读者 | 引用
22
Aug
【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
By 苏剑林 | 2016-08-22 | 460060位读者 | 引用关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM
18
Aug
【中文分词系列】 2. 基于切分的新词发现
By 苏剑林 | 2016-08-18 | 122582位读者 | 引用上一篇文章讲的是基于词典和AC自动机的快速分词。基于词典的分词有一个明显的优点,就是便于维护,容易适应领域。如果迁移到新的领域,那么只需要添加对应的领域新词,就可以实现较好地分词。当然,好的、适应领域的词典是否容易获得,这还得具体情况具体分析。本文要讨论的就是新词发现这一部分的内容。
这部分内容在去年的文章《新词发现的信息熵方法与实现》已经讨论过了,算法是来源于matrix67的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》。在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到$n$字词,就需要找出$1\sim n$字的切片,然后分别做计算,这对于$n$比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
19
Aug
【中文分词系列】 3. 字标注法与HMM模型
By 苏剑林 | 2016-08-19 | 83742位读者 | 引用在这篇文章中,我们暂停查词典方法的介绍,转而介绍字标注的方法。前面已经提到过,字标注是通过给句子中每个字打上标签的思路来进行分词,比如之前提到过的,通过4标签来进行标注(single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾。均只取第一个字母。),这样,“为人民服务”就可以标注为“sbebe”了。4标注不是唯一的标注方式,类似地还有6标注,理论上来说,标注越多会越精细,理论上来说效果也越好,但标注太多也可能存在样本不足的问题,一般常用的就是4标注和6标注。
值得一提的是,这种通过给每个字打标签、进而将问题转化为序列到序列的学习,不仅仅是一种分词方法,还是一种解决大量自然语言问题的思路,比如命名实体识别等任务,同样可以用标注的方法来做。回到分词来,通过字标注法来进行分词的模型有隐马尔科夫模型(HMM)、最大熵模型(ME)、条件随机场模型(CRF),它们在精度上都是递增的,据说目前公开评测中分词效果最好的是4标注的CRF。然而,在本文中,我们要讲解的是最不精确的HMM。因为在我看来,它并非一个特定的模型,而是解决一大类问题的通用思想,一种简化问题的学问。
这一切,还得从概率模型谈起。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 80117位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
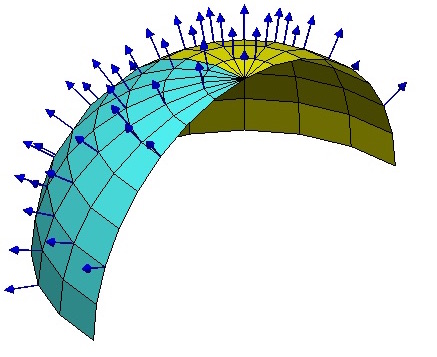
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。

最近评论