






18
Jul
也来扯几句“全国青少年科技创新大赛”
By 苏剑林 | 2020-07-18 | 35352位读者 | 引用
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 55019位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
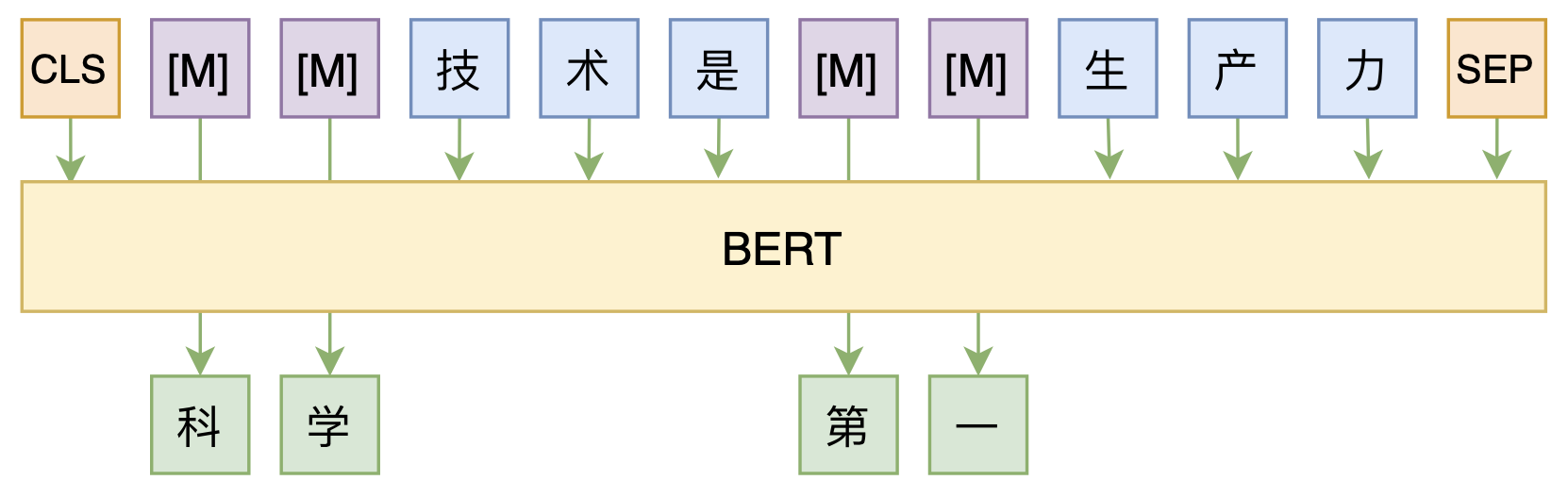
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
20
Aug
最小熵原理(六):词向量的维度应该怎么选择?
By 苏剑林 | 2020-08-20 | 101843位读者 | 引用随着NLP的发展,像Word2Vec、Glove这样的词向量模型,正逐渐地被基于Transformer的BERT等模型代替,不过经典始终是经典,词向量模型依然在不少场景发光发热,并且仍有不少值得我们去研究的地方。本文我们来关心一个词向量模型可能有的疑惑:词向量的维度大概多少才够?
先说结论,笔者给出的估算结果是
\begin{equation}n > 8.33\log N\label{eq:final}\end{equation}
更简约的话可以直接记$n > 8\log N$,其中$N$是词表大小,$n$就是词向量维度,$\log$是自然对数。当$n$超过这个阈值时,就说明模型有足够的容量容纳这$N$个词语(当然$n$越大过拟合风险也越大)。这样一来,当$N=100000$时,得到的$n$大约是96,所以对于10万个词的词向量模型来说,维度选择96就足够了;如果要容纳500万个词,那么$n$大概就是128。
31
Aug
再谈类别不平衡问题:调节权重与魔改Loss的对比联系
By 苏剑林 | 2020-08-31 | 79886位读者 | 引用类别不平衡问题,也称为长尾分布问题,在本博客里已经有好几次相关讨论了,比如《从loss的硬截断、软化到focal loss》、《将“Softmax+交叉熵”推广到多标签分类问题》、《通过互信息思想来缓解类别不平衡问题》。对于缓解类别不平衡,比较基本的方法就是调节样本权重,看起来“高端”一点的方法则是各种魔改loss了(比如Focal Loss、Dice Loss、Logits Adjustment等),本文希望比较系统地理解一下它们之间的联系。
长尾分布:少数类别的样本数目非常多,多数类别的样本数目非常少。
从光滑准确率到交叉熵
这里的分析主要以sigmoid的2分类为主,但多数结论可以平行推广到softmax的多分类。设$x$为输入,$y\in\{0,1\}$为目标,$p_{\theta}(x) \in [0, 1]$为模型。理想情况下,当然是要评测什么指标,我们就去优化那个指标。对于分类问题来说,最朴素的指标当然就是准确率,但准确率并没有办法提供有效的梯度,所以不能直接来训练。
15
Sep
殊途同归的策略梯度与零阶优化
By 苏剑林 | 2020-09-15 | 57087位读者 | 引用深度学习如此成功的一个巨大原因就是基于梯度的优化算法(SGD、Adam等)能有效地求解大多数神经网络模型。然而,既然是基于梯度,那么就要求模型是可导的,但随着研究的深入,我们时常会有求解不可导模型的需求,典型的例子就是直接优化准确率、F1、BLEU等评测指标,或者在神经网络里边加入了不可导模块(比如“跳读”操作)。

Gradient
本文将简单介绍两种求解不可导的模型的有效方法:强化学习的重要方法之一策略梯度(Policy Gradient),以及干脆不需要梯度的零阶优化(Zeroth Order Optimization)。表面上来看,这是两种思路完全不一样的优化方法,但本文将进一步证明,在一大类优化问题中,其实两者基本上是等价的。
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 153705位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
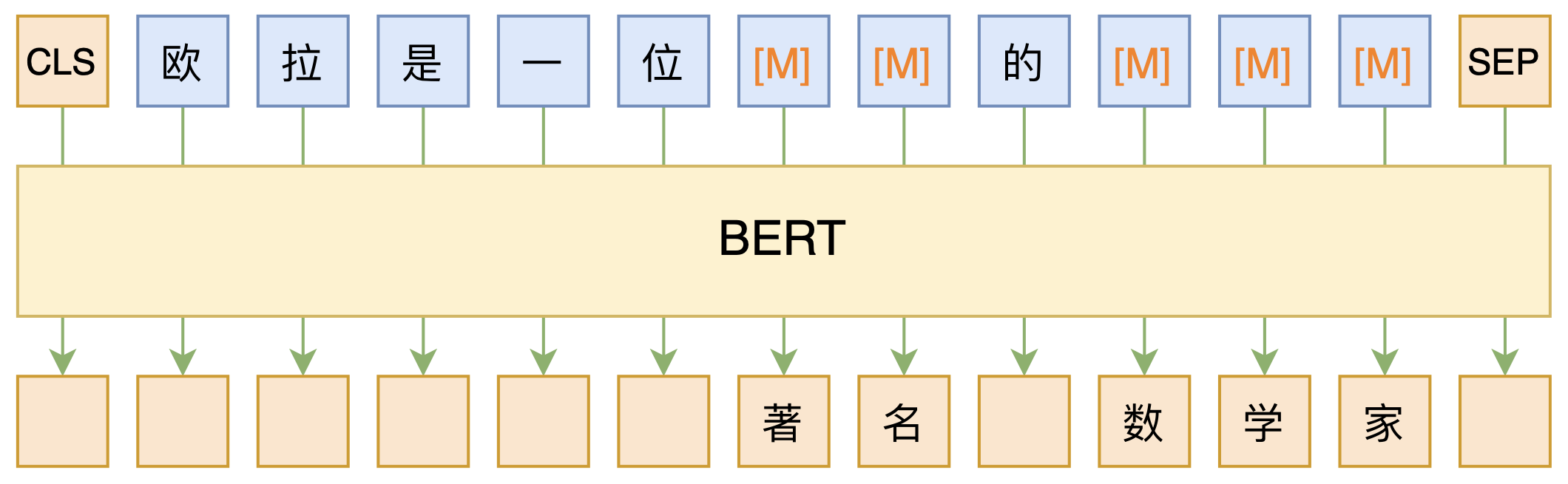
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
29
Oct
用ALBERT和ELECTRA之前,请确认你真的了解它们
By 苏剑林 | 2020-10-29 | 71738位读者 | 引用在预训练语言模型中,ALBERT和ELECTRA算是继BERT之后的两个“后起之秀”。它们从不同的角度入手对BERT进行了改进,最终提升了效果(至少在不少公开评测数据集上是这样),因此也赢得了一定的口碑。但在平时的交流学习中,笔者发现不少朋友对这两个模型存在一些误解,以至于在使用过程中浪费了不必要的时间。在此,笔者试图对这两个模型的一些关键之处做下总结,供大家参考,希望大家能在使用这两个模型的时候少走一些弯路。

ALBERT与ELECTRA
(注:本文中的“BERT”一词既指开始发布的BERT模型,也指后来的改进版RoBERTa,我们可以将BERT理解为没充分训练的RoBERTa,将RoBERTa理解为更充分训练的BERT。本文主要指的是它跟ALBERT和ELECTRA的对比,因此不区分BERT和RoBERTa。)
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 69319位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。

最近评论