






17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 32741位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。
8
Aug
三次方程的三角函数解法
By 苏剑林 | 2010-08-08 | 86224位读者 | 引用对于解方程,代数学家希望能够从理论上证明解的存在性以及解的求法,所以就有了1到4次方程的求根公式、5次及以上的代数方程没有根式可解等重要理论;然而,通常的学者(如物理学家、天文学家)都不需要这些内容,他们只关心如何尽可能快地求出指定方程的根(尤其是实数根),所以他们通常关注的是方程的数值算法,当然,如果能有一个相对简单的求根公式,也是他们所希望的。而接下来所要介绍的内容,则是满足了这一需要的三次方程的求根公式,其中用到的相当一部分的理论,是与三角函数相关的。
储备
\begin{equation}\frac{2}{\tan 2A}=\frac{1}{\tan A}-\tan A\end{equation}
\begin{equation}\frac{2}{\sin 2A}=\frac{1}{\tan A}+\tan A\end{equation}
\begin{equation}\cos(3A)=4\cos^3 A-3\cos A\end{equation}
8
Jul
一道比较函数大小的题目
By 苏剑林 | 2011-07-08 | 21496位读者 | 引用
24
Nov
力的无穷分解与格林函数法
By 苏剑林 | 2014-11-24 | 36617位读者 | 引用我小时候一直有个疑问:
直升机上的螺旋桨能不能用来挡雨?
一般的螺旋桨是若干个“条状”物通过旋转对称而形成的,也就是说,它并非一个面,按常理来说,它是没办法用来挡雨的。但是,如果在高速旋转的情况下,甚至假设旋转速度可以任意大,那么我们任意时刻都没有办法穿过它了,这种情况下,它似乎与一个实在的面无异?
力的无穷分解
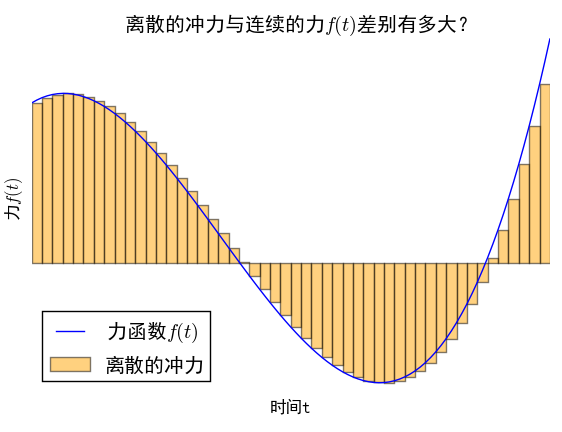
力的离散化
而让人惊喜的是,在通常的物理系统中,将力分段为无数个小区间内的恒力的做法,能够导致正确的答案,而且,这恰好是线性常微分方程的格林函数法。下面我们来分析这一做法。
27
Dec
费曼路径积分思想的发展(四)
By 苏剑林 | 2012-12-27 | 39551位读者 | 引用4、量子场论中的泛函方法
路径积分出现之初,大多数物理学家反映都很冷淡,甚至怀疑它的正确性。这一方面是对路径积分方法的陌生与误解所致。在泊珂淖会议上,玻尔就把费曼图误解成粒子运动的轨迹,并对之进行了尖锐的批评。([19],P.459)另一方面,费曼并没有用公理化的方法,从作用量或拉格朗日量出发系统地推导出费曼规则,他是靠经验、猜测、检验和比较来给出与各种图相应的规则的。尽管如此,费曼却能把他的方法推广到当时热门的介子理论,并且只需一个晚上就可解决他人用正则哈密顿方法要用几个月的时间才能解决的问题。费曼方法的有效性,使戴逊大为惊讶,并促使他相信路径积分“必定是根本上正确的”([1],P.54)理论。随之,戴逊便决定把“理解费曼(的思想)并用一种他人能理解的语言来加以阐述”([1],p.54)作为自己的主要工作。1948年,戴逊成功地证明了朝永振一朗、施温格和费曼三人的理论“在其共同适用领域内”[25]的等价性。费曼的粒子图像的路径积分方法由此改头换面,变成了场论形式的泛函积分方法。
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 152700位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 413797位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
18
May
基于量子化假设推导模型的尺度定律(Scaling Law)
By 苏剑林 | 2023-05-18 | 36620位读者 | 引用尺度定律(Scaling Law),指的是模型能力与模型尺度之间的渐近关系。具体来说,模型能力我们可以简单理解为模型的损失函数,模型尺度可以指模型参数量、训练数据量、训练步数等,所谓尺度定律,就是研究损失函数跟参数量、数据量、训练步数等变量的大致关系。《Scaling Laws for Neural Language Models》、《Training Compute-Optimal Large Language Models》等工作的实验结果表明,神经网络的尺度定律多数呈现“幂律(Power law)”的形式。
为什么会是幂律呢?能否从理论上解释呢?论文《The Quantization Model of Neural Scaling》基于“量子化”假设给出了一个颇为有趣的推导。本文一同来欣赏一下。

最近评论