






14
Feb
生成扩散模型漫谈(十六):W距离 ≤ 得分匹配
By 苏剑林 | 2023-02-14 | 24127位读者 | 引用Wasserstein距离(下面简称“W距离”),是基于最优传输思想来度量两个概率分布差异程度的距离函数,笔者之前在《从Wasserstein距离、对偶理论到WGAN》等博文中也做过介绍。对于很多读者来说,第一次听说W距离,是因为2017年出世的WGAN,它开创了从最优传输视角来理解GAN的新分支,也提高了最优传输理论在机器学习中的地位。很长一段时间以来,GAN都是生成模型领域的“主力军”,直到最近这两年扩散模型异军突起,GAN的风头才有所下降,但其本身仍不失为一个强大的生成模型。
从形式上来看,扩散模型和GAN差异很明显,所以其研究一直都相对独立。不过,去年底的一篇论文《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》打破了这个隔阂:它证明了扩散模型的得分匹配损失可以写成W距离的上界形式。这意味着在某种程度上,最小化扩散模型的损失函数,实则跟WGAN一样,都是在最小化两个分布的W距离。
8
Jun
Naive Bayes is all you need ?
By 苏剑林 | 2023-06-08 | 47160位读者 | 引用很抱歉,起了这么个具有标题党特征的题目。在写完《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》之后,笔者就觉得朴素贝叶斯(Naive Bayes)跟Attention机制有很多相同的特征,后来再推导了一下发现,Attention机制其实可以看成是一种广义的、参数化的朴素贝叶斯。既然如此,“Attention is All You Need”不也就意味着“Naive Bayes is all you need”了?这就是本文标题的缘由。
接下来笔者将介绍自己的思考过程,分析如何从朴素贝叶斯角度来理解Attention机制。
朴素贝叶斯
本文主要考虑语言模型,它要建模的是$p(x_t|x_1,\cdots,x_{t-1})$。根据贝叶斯公式,我们有
\begin{equation}p(x_t|x_1,\cdots,x_{t-1}) = \frac{p(x_1,\cdots,x_{t-1}|x_t)p(x_t)}{p(x_1,\cdots,x_{t-1})}\propto p(x_1,\cdots,x_{t-1}|x_t)p(x_t)\end{equation}
28
Jun
生成扩散模型漫谈(二十):从ReFlow到WGAN-GP
By 苏剑林 | 2023-06-28 | 24563位读者 | 引用上一篇文章《生成扩散模型漫谈(十九):作为扩散ODE的GAN》中,我们介绍了如何将GAN理解为在另一个时间维度上的扩散ODE,简而言之,GAN实际上就是将扩散模型中样本的运动转化为生成器参数的运动!然而,该文章的推导过程依赖于Wasserstein梯度流等相对复杂和独立的内容,没法很好地跟扩散系列前面的文章连接起来,技术上显得有些“断层”。
在笔者看来,《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》所介绍的ReFlow是理解扩散ODE的最直观方案,既然可以从扩散ODE的角度理解GAN,那么必定存在一个从ReFlow理解GAN的角度。经过一番尝试,笔者成功从ReFlow推出了类似WGAN-GP的结果。
理论回顾
之所以说“ReFlow是理解扩散ODE的最直观方案”,是因为它本身非常灵活,以及非常贴近实验代码——它能够通过ODE建立任意噪声分布到目标数据分布的映射,而且训练目标非常直观,不需要什么“弯弯绕绕”就可以直接跟实验代码对应起来。
15
Dec
生成扩散模型漫谈(二十七):将步长作为条件输入
By 苏剑林 | 2024-12-15 | 4316位读者 | 引用这篇文章我们再次聚焦于扩散模型的采样加速。众所周知,扩散模型的采样加速主要有两种思路,一是开发更高效的求解器,二是事后蒸馏。然而,据笔者观察,除了上两篇文章介绍过的SiD外,这两种方案都鲜有能将生成步数降低到一步的结果。虽然SiD能做到单步生成,但它需要额外的蒸馏成本,并且蒸馏过程中用到了类似GAN的交替训练过程,总让人感觉差点意思。
本文要介绍的是《One Step Diffusion via Shortcut Models》,其突破性思想是将生成步长也作为扩散模型的条件输入,然后往训练目标中加入了一个直观的正则项,这样就能直接稳定训练出可以单步生成模型,可谓简单有效的经典之作。
ODE扩散
原论文的结论是基于ODE式扩散模型的,而对于ODE式扩散的理论基础,我们在本系列的(六)、(十二)、(十四)、(十五)、(十七)等博客中已经多次介绍,其中最简单的一种理解方式大概是(十七)中的ReFlow视角,下面我们简单重复一下。
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 205455位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
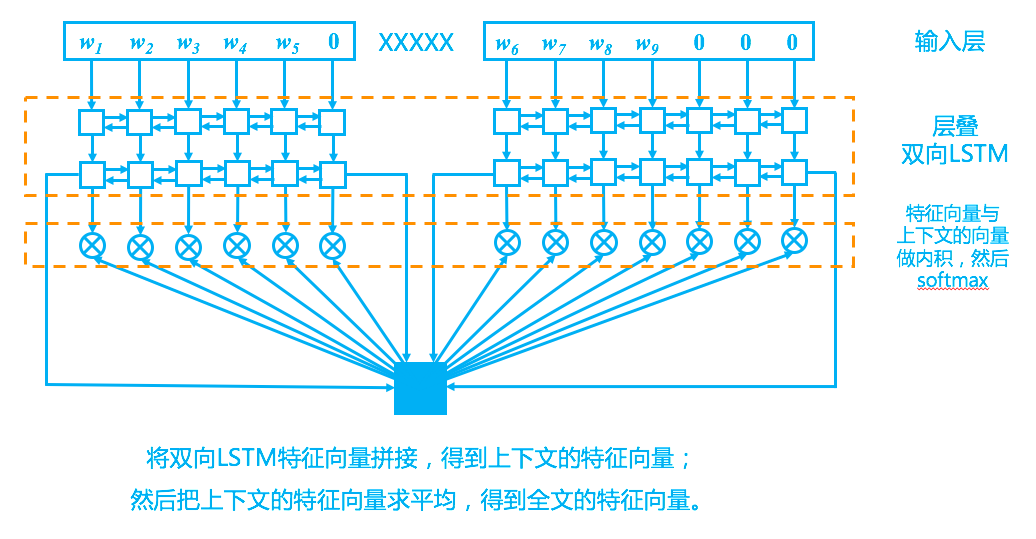
完形填空模型
7
Jun
python简单实现gillespie模拟
By 苏剑林 | 2018-06-07 | 72219位读者 | 引用
18
Jul
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
By 苏剑林 | 2018-07-18 | 352072位读者 | 引用前言:我小学开始就喜欢纯数学,后来也喜欢上物理,还学习过一段时间的理论物理,直到本科毕业时,我才慢慢进入机器学习领域。所以,哪怕在机器学习领域中,我的研究习惯还保留着数学和物理的风格:企图从最少的原理出发,理解、推导尽可能多的东西。这篇文章是我这个理念的结果之一,试图以变分推断作为出发点,来统一地理解深度学习中的各种模型,尤其是各种让人眼花缭乱的GAN。本文已经挂到arxiv上,需要读英文原稿的可以移步到《Variational Inference: A Unified Framework of Generative Models and Some Revelations》。
下面是文章的介绍。其实,中文版的信息可能还比英文版要稍微丰富一些,原谅我这蹩脚的英语...
摘要:本文从一种新的视角阐述了变分推断,并证明了EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。其中,论文也表明了标准的GAN的优化目标是不完备的,这可以解释为什么GAN的训练需要谨慎地选择各个超参数。最后,文中给出了一个可以改善这种不完备性的正则项,实验表明该正则项能增强GAN训练的稳定性。
近年来,深度生成模型,尤其是GAN,取得了巨大的成功。现在我们已经可以找到数十个乃至上百个GAN的变种。然而,其中的大部分都是凭着经验改进的,鲜有比较完备的理论指导。
本文的目标是通过变分推断来给这些生成模型建立一个统一的框架。首先,本文先介绍了变分推断的一个新形式,这个新形式其实在博客以前的文章中就已经介绍过,它可以让我们在几行字之内导出变分自编码器(VAE)和EM算法。然后,利用这个新形式,我们能直接导出GAN,并且发现标准GAN的loss实则是不完备的,缺少了一个正则项。如果没有这个正则项,我们就需要谨慎地调整超参数,才能使得模型收敛。
26
Jan
Transformer升级之路:16、“复盘”长度外推技术
By 苏剑林 | 2024-01-26 | 75485位读者 | 引用回过头来看,才发现从第7篇《Transformer升级之路:7、长度外推性与局部注意力》开始,“Transformer升级之路”这个系列就跟长度外推“杠”上了,接连9篇文章(不算本文)都是围绕长度外推展开的。如今,距离第7篇文章刚好是一年多一点,在这一年间,开源社区关于长度外推的研究有了显著进展,笔者也逐渐有了一些自己的理解,比如其实这个问题远不像一开始想象那么简单,以往很多基于局部注意力的工作也不总是有效,这暗示着很多旧的分析工作并没触及问题的核心。
在这篇文章中,笔者尝试结合自己的发现和认识,去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。
问题定义
顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等,LongBench就是就属于这类榜单。

最近评论