






18
May
基于量子化假设推导模型的尺度定律(Scaling Law)
By 苏剑林 | 2023-05-18 | 28554位读者 | 引用尺度定律(Scaling Law),指的是模型能力与模型尺度之间的渐近关系。具体来说,模型能力我们可以简单理解为模型的损失函数,模型尺度可以指模型参数量、训练数据量、训练步数等,所谓尺度定律,就是研究损失函数跟参数量、数据量、训练步数等变量的大致关系。《Scaling Laws for Neural Language Models》、《Training Compute-Optimal Large Language Models》等工作的实验结果表明,神经网络的尺度定律多数呈现“幂律(Power law)”的形式。
为什么会是幂律呢?能否从理论上解释呢?论文《The Quantization Model of Neural Scaling》基于“量子化”假设给出了一个颇为有趣的推导。本文一同来欣赏一下。
20
Jul
语言模型输出端共享Embedding的重新探索
By 苏剑林 | 2023-07-20 | 24933位读者 | 引用预训练刚兴起时,在语言模型的输出端重用Embedding权重是很常见的操作,比如BERT、第一版的T5、早期的GPT,都使用了这个操作,这是因为当模型主干部分不大且词表很大时,Embedding层的参数量很可观,如果输出端再新增一个独立的同样大小的权重矩阵的话,会导致显存消耗的激增。不过随着模型参数规模的增大,Embedding层的占比相对变小了,加之《Rethinking embedding coupling in pre-trained language models》等研究表明共享Embedding可能会有些负面影响,所以现在共享Embedding的做法已经越来越少了。
本文旨在分析在共享Embedding权重时可能遇到的问题,并探索如何更有效地进行初始化和参数化。尽管共享Embedding看起来已经“过时”,但这依然不失为一道有趣的研究题目。
16
Sep
生成函数法与整数的分拆
By 苏剑林 | 2014-09-16 | 29939位读者 | 引用我们在高中甚至初中,都有可能遇到这样的题目:
设$x,y,z$是非负整数,问$x+y+z=2014$有多少组不同的解?(不同顺序视为不同的解)
难度稍高点,可以改为
设$x,y,z$是非负整数,$0\leq x\leq y\leq z$,问$x+y+z=2014$有多少组不同的解?
这些问题都属于整数的分拆问题(广为流传的哥德巴赫猜想也是一个整数分拆问题)。有很多不同的思路可以求解这两道题,然而,个人认为这些方法中最引人入胜的(可能也是最有力的)首推“生成函数法”。
关于生成函数,本节就不多作介绍了,如果缺乏相关基础的朋友,请先阅读相关资料了解该方法。不少数论的、离散数学的、计算机科学的书籍中,都介绍了生成函数法(也叫母函数法)。本质上讲,母函数法能有诸多应用,是因为$x^a\times x^b=x^{a+b}$这一性质的成立。

淡白口蘑
达尔文的进化学说告诉我们,自然界总是在众多的生物中挑出最能够适应环境的物种,赋予它们更高的生存几率,久而久之,这些物种经过亿万年的“优胜劣汰”,进化成了今天的千奇百怪的生物。无疑,经过长期的选择,优良的形状会被累积下来,换句话讲,这些物种在某些环境适应能力方面已经达到最优或近乎最优的状态(又是一个极值问题了)。好,现在我们来考虑蘑菇。
蘑菇是一种真菌生物,一般生长在阴暗潮湿的环境中。喜欢湿润的它自然也不希望散失掉过多的水分,因此,它努力地调整自身的形状,使它的“失水”尽可能地少。假设单位面积的蘑菇的失水速度是一致的,那么问题就变成了使一个给定体积的立体表面积尽可能少的问题了。并且考虑到水平各向同性生长的问题,理想的蘑菇形状应该就是一个平面图形的旋转体。那么这个旋转体是什么呢?聪明的你是否想到了是一个球体(的一部分)呢?
30
Apr
当概率遇上复变:随机游走基本公式
By 苏剑林 | 2014-04-30 | 57537位读者 | 引用
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 178441位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
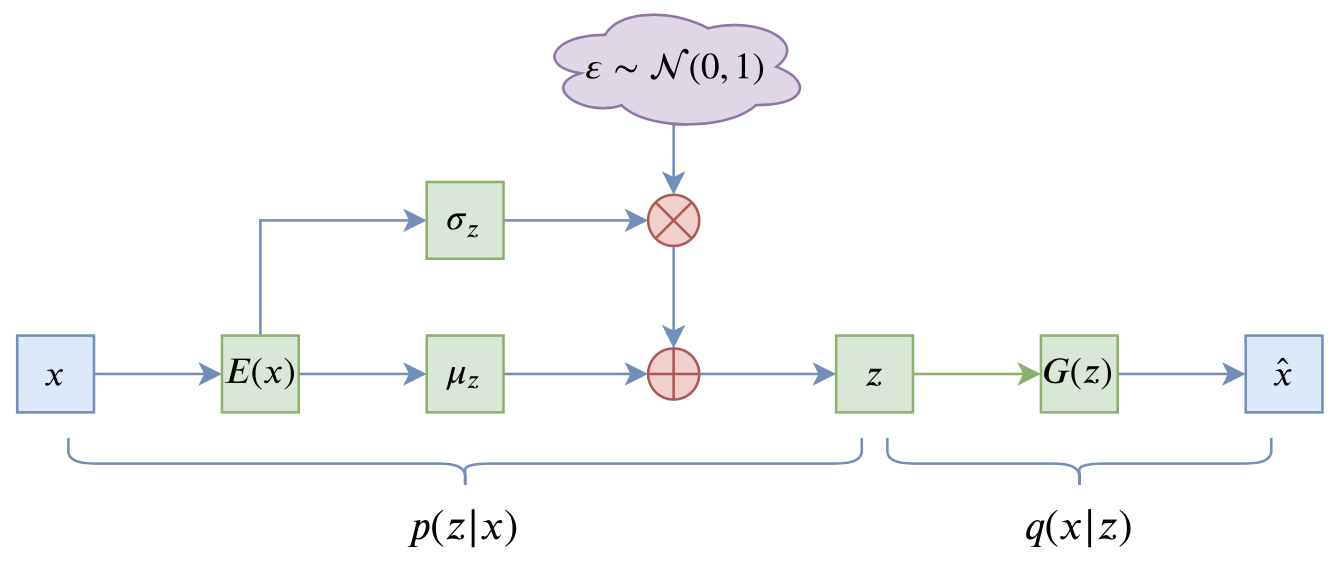
VAE训练流程图示
13
Feb
Designing GANs:又一个GAN生产车间
By 苏剑林 | 2020-02-13 | 31577位读者 | 引用在2018年的文章里《f-GAN简介:GAN模型的生产车间》笔者介绍了f-GAN,并评价其为GAN模型的“生产车间”,顾名思义,这是指它能按照固定的流程构造出很多不同形式的GAN模型来。前几天在arxiv上看到了新出的一篇论文《Designing GANs: A Likelihood Ratio Approach》(后面简称Designing GANs或原论文),发现它在做跟f-GAN同样的事情,但走的是一条截然不同的路(不过最后其实是殊途同归),整篇论文颇有意思,遂在此分享一番。
f-GAN回顾
从《f-GAN简介:GAN模型的生产车间》中我们可以知道,f-GAN的首要步骤是找到满足如下条件的函数$f$:
1、$f$是非负实数到实数的映射($\mathbb{R}^* \to \mathbb{R}$);
2、$f(1)=0$;
3、$f$是凸函数。
18
Dec
迟到一年的建模:再探碎纸复原
By 苏剑林 | 2014-12-18 | 75413位读者 | 引用前言:一年前国赛的时候,很初级地做了一下B题,做完之后还写了个《碎纸复原:一个人的数学建模》。当时就是对题目很有兴趣,然后通过一天的学习,基本完成了附件一二的代码,对附件三也只是有个概念。而今年我们上的数学建模课,老师把这道题作为大作业让我们做,于是我便再拾起了一年前的那份激情,继续那未完成的一个人的数学建模...
与去年不同的是,这次将所有代码用Python实现了,更简洁,更清晰,甚至可能更高效~~以下是论文全文。
研究背景
2011年10月29日,美国国防部高级研究计划局(DARPA)宣布了一场碎纸复原挑战赛(Shredder Challenge),旨在寻找到高效有效的算法,对碎纸机处理后的碎纸屑进行复原。[1]该竞赛吸引了全美9000支参赛队伍参与角逐,经过一个多月的时间,有一支队伍成功完成了官方的题目。
近年来,碎纸复原技术日益受到重视,它显示了在碎片中“还原真相”的可能性,表明我们可以从一些破碎的片段中“解密”出原始信息来。另一方面,该技术也和照片处理领域中的“全景图拼接技术”有一定联系,该技术是指通过若干张不同侧面的照片,合成一张完整的全景图。因此,分析研究碎纸复原技术,有着重要的意义。

最近评论