






27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
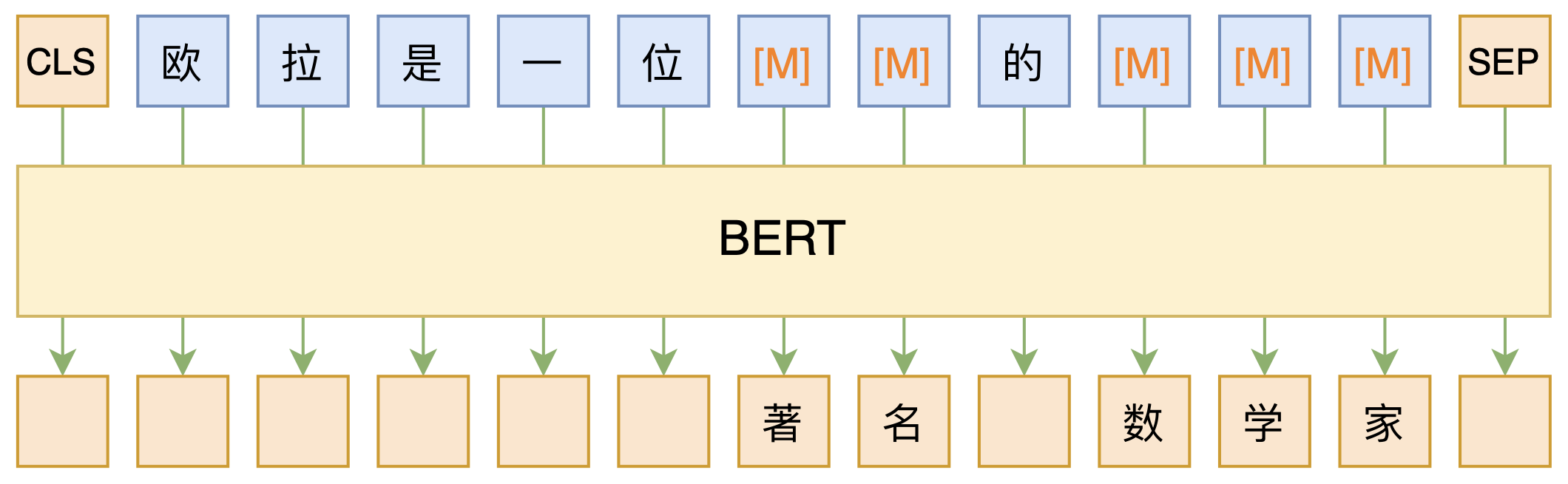
By 苏剑林 | 2020-09-27 | 153689位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
8
Apr
生成扩散模型漫谈(二十二):信噪比与大图生成(上)
By 苏剑林 | 2024-04-08 | 48903位读者 | 引用盘点主流的图像扩散模型作品,我们会发现一个特点:当前多数做高分辨率图像生成(下面简称“大图生成”)的工作,都是先通过Encoder变换到Latent空间进行的(即LDM,Latent Diffusion Model),直接在原始Pixel空间训练的扩散模型,大多数分辨率都不超过64*64,而恰好,LDM通过AutoEncoder变换后的Latent,大小通常也不超过64*64。这就自然引出了一系列问题:扩散模型是不是对于高分辨率生成存在固有困难?能否在Pixel空间直接生成高分辨率图像?
论文《Simple diffusion: End-to-end diffusion for high resolution images》尝试回答了这个问题,它通过“信噪比”分析了大图生成的困难,并以此来优化noise schdule,同时提出只需在最低分辨率feature上对架构进行scale up、多尺度Loss等技巧来保证训练效率和效果,这些改动使得原论文成功在Pixel空间上训练了分辨率高达1024*1024的图像扩散模型。

淡白口蘑
达尔文的进化学说告诉我们,自然界总是在众多的生物中挑出最能够适应环境的物种,赋予它们更高的生存几率,久而久之,这些物种经过亿万年的“优胜劣汰”,进化成了今天的千奇百怪的生物。无疑,经过长期的选择,优良的形状会被累积下来,换句话讲,这些物种在某些环境适应能力方面已经达到最优或近乎最优的状态(又是一个极值问题了)。好,现在我们来考虑蘑菇。
蘑菇是一种真菌生物,一般生长在阴暗潮湿的环境中。喜欢湿润的它自然也不希望散失掉过多的水分,因此,它努力地调整自身的形状,使它的“失水”尽可能地少。假设单位面积的蘑菇的失水速度是一致的,那么问题就变成了使一个给定体积的立体表面积尽可能少的问题了。并且考虑到水平各向同性生长的问题,理想的蘑菇形状应该就是一个平面图形的旋转体。那么这个旋转体是什么呢?聪明的你是否想到了是一个球体(的一部分)呢?
22
Jun
文本情感分类(一):传统模型
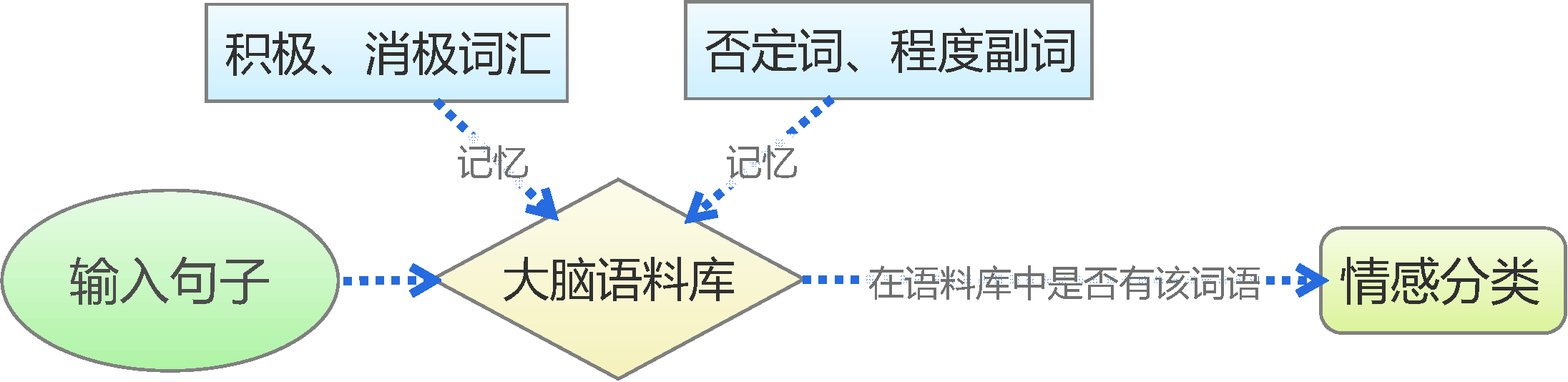
By 苏剑林 | 2015-06-22 | 228674位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
人的最简单的判断思维
15
Jul
漫话模型|模型与选芒果
By 苏剑林 | 2015-07-15 | 38639位读者 | 引用很多人觉得“模型”、“大数据”、“机器学习”这些字眼很高大很神秘,事实上,它跟我们生活中选水果差不了多少。本文用了几千字,来试图教会大家怎么选芒果...
模型的比喻

芒果
假如我要从一批芒果中,找出好吃的那个来。而我不能直接切开芒果尝尝,所以我只能观察芒果,能观察到的量有颜色、表面的气味、大小等等,这些就是我们能够收集到的信息(特征)。
生活中还要很多这样的例子,比如买火柴(可能年轻的城里人还没见过火柴?),如何判断一盒火柴的质量?难道要每根火柴都划划,看看着不着火?显然不行,我们最多也只能划几根,全部划了,火柴也不成火柴了。当然,我们还能看看火柴的样子,闻闻火柴的气味,这些动作是可以接受的。
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 613029位读者 | 引用
1
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(一)
By 苏剑林 | 2015-12-01 | 83835位读者 | 引用熵的概念
作为一名物理爱好者,我一直对统计力学中“熵”这个概念感到神秘和好奇。因此,当我接触数据科学的时候,我也对最大熵模型产生了浓厚的兴趣。
熵是什么?在通俗的介绍中,熵一般有两种解释:(1)熵是不确定性的度量;(2)熵是信息的度量。看上去说的不是一回事,其实它们说的就是同一个意思。首先,熵是不确定性的度量,它衡量着我们对某个事物的“无知程度”。熵为什么又是信息的度量呢?既然熵代表了我们对事物的无知,那么当我们从“无知”到“完全认识”这个过程中,就会获得一定的信息量,我们开始越无知,那么到达“完全认识”时,获得的信息量就越大,因此,作为不确定性的度量的熵,也可以看作是信息的度量,说准确点,是我们能从中获得的最大的信息量。
11
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(二)
By 苏剑林 | 2015-12-11 | 85376位读者 | 引用上集回顾
在第一篇中,笔者介绍了“熵”这个概念,以及它的一些来龙去脉。熵的公式为
$$S=-\sum_x p(x)\log p(x)\tag{1}$$
或
$$S=-\int p(x)\log p(x) dx\tag{2}$$
并且在第一篇中,我们知道熵既代表了不确定性,又代表了信息量,事实上它们是同一个概念。
说完了熵这个概念,接下来要说的是“最大熵原理”。最大熵原理告诉我们,当我们想要得到一个随机事件的概率分布时,如果没有足够的信息能够完全确定这个概率分布(可能是不能确定什么分布,也可能是知道分布的类型,但是还有若干个参数没确定),那么最为“保险”的方案是选择使得熵最大的分布。
最大熵原理
承认我们的无知
很多文章在介绍最大熵原理的时候,会引用一句著名的句子——“不要把鸡蛋放在同一个篮子里”——来通俗地解释这个原理。然而,笔者窃以为这句话并没有抓住要点,并不能很好地体现最大熵原理的要义。笔者认为,对最大熵原理更恰当的解释是:承认我们的无知!

最近评论