






20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 31824位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
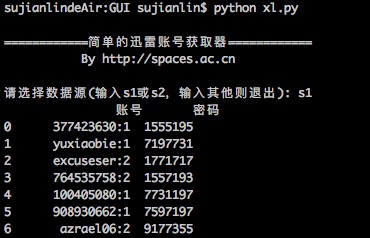
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
4
Mar
趣题:如何编程列出一个集合的所有子集
By 苏剑林 | 2016-03-04 | 29823位读者 | 引用
12
Apr
【备忘】用树莓派3做无线路由器
By 苏剑林 | 2016-04-12 | 64624位读者 | 引用3月初发布的树莓派3自带了WiFi和蓝牙,再加上它本来就有一个网口,因此俨然就是一台无线路由器了。我也忍不住入手了一个,打算用来做路由器和NAS。树莓派做路由器的教程已经有很多了,当然,基本都是基于树莓派2的,3之前的版本都没有自带WiFi,因此需要自己配无线网卡,而3自带了无线网卡,配置就方便多了。参考了两篇外文教程,成功配置,在这里记录一下。
参考教程:
https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
https://gist.github.com/Lewiscowles1986/fecd4de0b45b2029c390#file-rpi3-ap-setup-sh
17
Jun
OCR技术浅探:2. 背景与假设
By 苏剑林 | 2016-06-17 | 38041位读者 | 引用研究背景
关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件.
然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进.
综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 我们队伍将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究假设
在本文中,我们假设图像的文字部分有以下的特征:
24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 40088位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
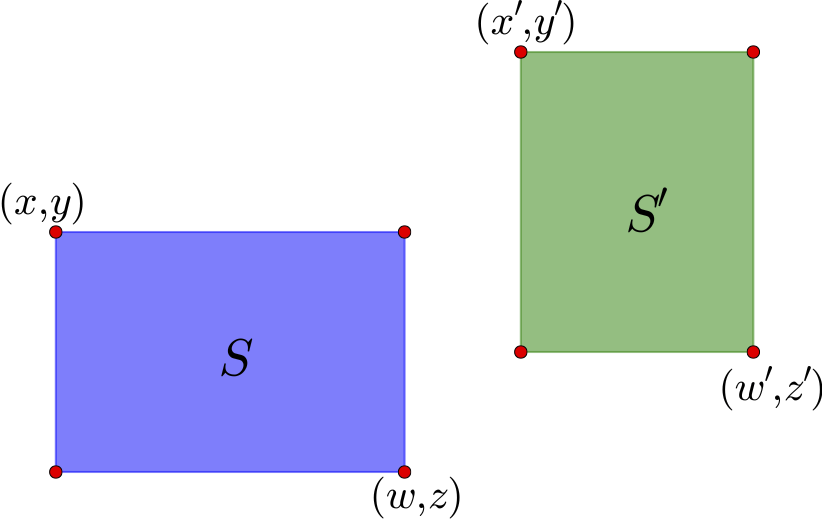
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域
24
Jun
OCR技术浅探:5. 文本切割
By 苏剑林 | 2016-06-24 | 45638位读者 | 引用

13
Aug
两个惊艳的python库:tqdm和retry
By 苏剑林 | 2016-08-13 | 65949位读者 | 引用Python基本是我目前工作、计算、数据挖掘的唯一编程语言(除了符号计算用Mathematica外)。当然,基本的Python功能并不是很强大,但它胜在有巨量的第三方扩展库。在选用Python的第三方库时,我都会经过仔细考虑,希望能挑选出最简单的、最直观的一个(因为本人比较笨,太复杂用不了)。在数据处理方面,我用得最多的是Numpy和Pandas,这两个绝对称得上王者级别的库,当然不能不提的是Scipy,但我很少直接用它,一般会通过Pandas间接调用了;可视化方面不用说是Matplotlib了;在建模方面,我会用Keras,直接上深度学习模型,Keras已经成为相当流行的深度学习框架了,如果做文本挖掘,通常还会用到jieba(分词)、Gensim(主题建模,包含了诸如word2vec之类的模型),机器学习库还有流行的Scikit Learn,但我很少用;网络方面,写爬虫我用requests,这是个人性化的网络库,如果写网站,我会用bottle,这是个单文件版的迷你框架,一切由自己定义,当然,我也不会去写什么大型网站,我就写一个简单的的接口那样而已;最后如果要并行的话,一般直接用multiprocessing。
不过,以上都不是本文要推荐的,本文要推荐的是两个可以渗透到日常写代码的库,它实现了我们平时很多时候都需要的功能,但是不用增加什么代码,绝对让人眼前一亮。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 80402位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
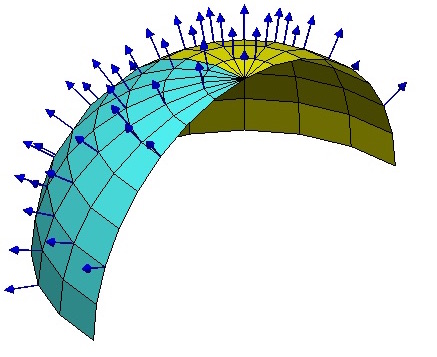
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。

最近评论