






21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 37010位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。
15
Mar
WGAN的成功,可能跟Wasserstein距离没啥关系
By 苏剑林 | 2021-03-15 | 55118位读者 | 引用WGAN,即Wasserstein GAN,算是GAN史上一个比较重要的理论突破结果,它将GAN中两个概率分布的度量从f散度改为了Wasserstein距离,从而使得WGAN的训练过程更加稳定,而且生成质量通常也更好。Wasserstein距离跟最优传输相关,属于Integral Probability Metric(IPM)的一种,这类概率度量通常有着更优良的理论性质,因此WGAN的出现也吸引了很多人从最优传输和IPMs的角度来理解和研究GAN模型。
然而,最近Arxiv上的论文《Wasserstein GANs Work Because They Fail (to Approximate the Wasserstein Distance)》则指出,尽管WGAN是从Wasserstein GAN推导出来的,但是现在成功的WGAN并没有很好地近似Wasserstein距离,相反如果我们对Wasserstein距离做更好的近似,效果反而会变差。事实上,笔者一直以来也有这个疑惑,即Wasserstein距离本身并没有体现出它能提升GAN效果的必然性,该论文的结论则肯定了该疑惑,所以GAN能成功的原因依然很迷~
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 66287位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
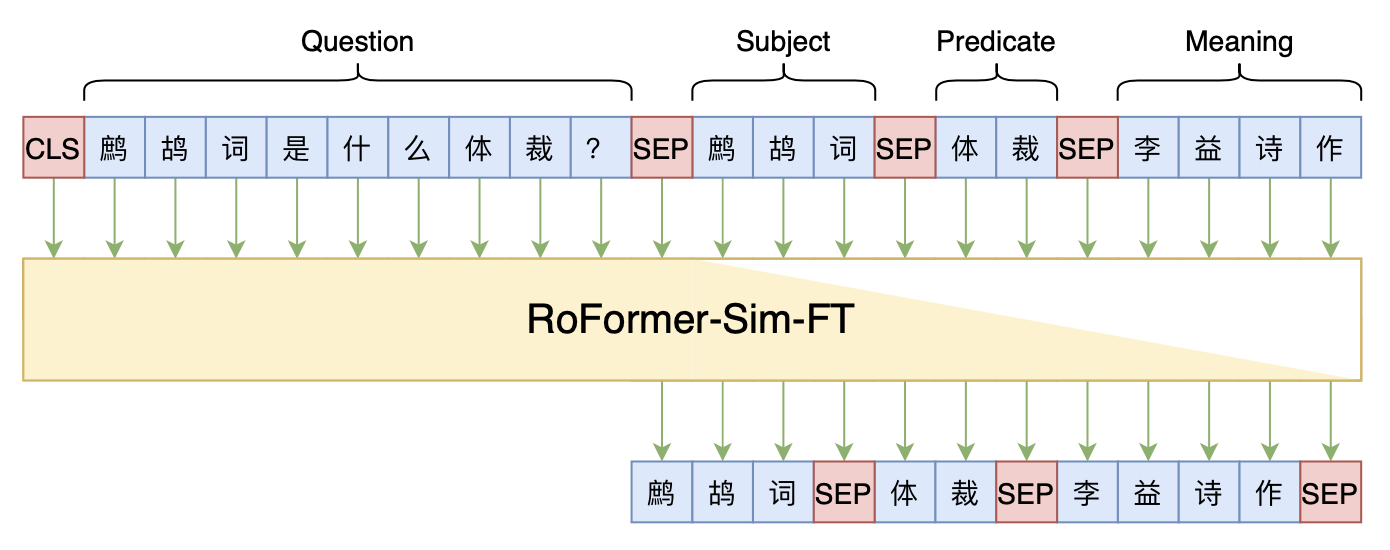
本文baseline模型示意图
5
Dec
智能家居之小爱同学控制极米投影仪的简单方案
By 苏剑林 | 2022-12-05 | 33977位读者 | 引用前段时间买了一个极米投影仪,开始折腾才发现极米跟小米基本没啥关系,它根本无法跟小爱同学互动。在众多名字带“米”的品牌中,极米是为数不多的无法接入米家生态的品牌,想必有不少用户开始都会被极米这个名字误导,关键是极米投影仪还在小米商城上有得卖(捂脸)。
买都买了,还过了七天无理由,退是退不成了,只能试着折腾一下,看看能不能强行互动。
现有方案
首先网上搜了一下,网友给出的参考方案大体上有几种,一种是用“米家智能插座 + 上电自动开机”来控制开关机(事实上主要的联动就是开关机了),一种是接入Home Assistant后通过ADB控制,还有一种是修改遥控器,给遥控器加入红外模块,继而用小爱同学的红外遥控功能。
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 32475位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
3
Apr
Bias项的神奇作用:RoPE + Bias = 更好的长度外推性
By 苏剑林 | 2023-04-03 | 42715位读者 | 引用万万没想到,Bias项能跟Transformer的长度外推性联系在一起!
长度外推性是我们希望Transformer具有的一个理想性质,笔者曾在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》系统地介绍过这一问题。至于Bias项(偏置项),目前的主流观点是当模型足够大时,Bias项不会有什么特别的作用,所以很多模型选择去掉Bias项,其中代表是Google的T5和PaLM,我们后面做的RoFormerV2和GAU-α也沿用了这个做法。
那么,这两个看上去“风牛马不相及”的东西,究竟是怎么联系起来的呢?Bias项真的可以增强Transformer的长度外推性?且听笔者慢慢道来。
5
May
如何度量数据的稀疏程度?
By 苏剑林 | 2023-05-05 | 33004位读者 | 引用在机器学习中,我们经常会谈到稀疏性,比如我们经常说注意力矩阵通常是很稀疏的。然而,不知道大家发现没有,我们似乎从没有给出过度量稀疏程度的标准方法。也就是说,以往我们关于稀疏性的讨论,仅仅是直观层面的感觉,并没有过定量分析。那么问题来了,稀疏性的度量有标准方法了吗?
经过搜索,笔者发现确实是有一些可用的指标,比如$l_1/l_2$、熵等,但由于关注视角的不同,在稀疏性度量方面并没有标准答案。本文简单记录一下笔者的结果。
基本结果
狭义上来讲,“稀疏”就是指数据中有大量的零,所以最简单的稀疏性指标就是统计零的比例。但如果仅仅是这样的话,注意力矩阵就谈不上稀疏了,因为softmax出来的结果一定是正数。所以,有必要推广稀疏的概念。一个朴素的想法是统计绝对值不超过$\epsilon$的元素比例,但这个$\epsilon$怎么确定呢?
1
Jan
新年快乐!记录一下 Cool Papers 的开发体验
By 苏剑林 | 2024-01-01 | 57967位读者 | 引用上周在《写了个刷论文的辅助网站:Cool Papers》中,笔者分享了一个自己开发的刷论文网站Cool Papers,并得到了一些用户的认可。然而,“使用的人越多,暴露的问题就越多”,当用户量上来后,才感觉到之前写的代码是多么不严谨,于是过去一整周都在不停地修Bug之中,直到今天下午还发现了一个Bug在修。这篇文章简单总结一下笔者在开发和修Bug过程中的感想。
Cool Papers:https://papers.cool
技术
事实上,“papers.cool”这个域名已经注册了四年多,从这可以看出笔者其实很早以前就计划着做类似Cool Papers的网站,也做过一些雏形,但之所以这个网站在四年后才正式诞生,根本原因就只有一个:技术不行。

最近评论