






26
Jun
OCR技术浅探:8. 综合评估
By 苏剑林 | 2016-06-26 | 29130位读者 | 引用数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准. 在本节中,我们通过自己的模型,与京东的测试数据进行比较验证.
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别. 我们采用评分的方法,对每一张图片的识别效果进行评分. 评分规则如下:
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数.
按照这个规则,每张图片的评分最多是2分,最少是0分. 如果评分超过1,说明识别效果比较好了. 经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
2
May
基于Conv1D的光谱分类模型(一维序列分类)
By 苏剑林 | 2018-05-02 | 116830位读者 | 引用前段时间天池出了个天文数据挖掘竞赛——LAMOST光谱分类(将对应的光谱识别为4类中的一类),虽然没有奖金,但还是觉得挺有意思,所以就报名参加了。做了一段时间,成绩自我感觉还可以,然而最后我却忘记了(或者说根本就没留意到)初赛最后两天还有一步是提交新的测试集结果,然后就没有然后了,留下了一个未竟的模型,可谓“出师未捷身先死”,还是被自己弄死的~

天文数据挖掘大赛——天体光谱智能分类
后来跟其他参赛选手讨论了一下,发现其实我的这个模型还是不错的。当时我记得初赛第一名的成绩是0.83+,而我当时的成绩是0.82+,排名大概是第4、5左右,而且据说很多分数在0.8+的队伍都已经使用了融合模型,而我这0.82+的成绩仅仅是单模型的结果~在平时的群聊中发现也有不少朋友在做一维序列分类模型,而光谱分类本质上也就是一个一维的序列分类,所以分享一下模型,估计对相关朋友会有一定的参考价值。
模型
事实上也不是什么特别的模型,就是普通的一维卷积加残差,对于熟悉图像处理的朋友,这实在是再普通不过的结构了。
11
Jun
SimBERTv2来了!融合检索和生成的RoFormer-Sim模型
By 苏剑林 | 2021-06-11 | 108928位读者 | 引用去年我们放出了SimBERT模型,它算是我们开源的比较成功的模型之一,获得了不少读者的认可。简单来说,SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,这一功能是开创性的。
近段时间,我们以RoFormer为基础模型,对SimBERT相关技术进一步整合和优化,最终发布了升级版的RoFormer-Sim模型。
简介
RoFormer-Sim是SimBERT的升级版,我们也可以通俗地称之为“SimBERTv2”,而SimBERT则默认是指旧版。从外部看,除了基础架构换成了RoFormer外,RoFormer-Sim跟SimBERT没什么明显差别,事实上它们主要的区别在于训练的细节上,我们可以用两个公式进行对比:
\begin{array}{c}
\text{SimBERT} = \text{BERT} + \text{UniLM} + \text{对比学习} \\[5pt]
\text{RoFormer-Sim} = \text{RoFormer} + \text{UniLM} + \text{对比学习} + \text{BART} + \text{蒸馏}\\
\end{array}
25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 118016位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。
1
Oct
中国探索火星,还等两年!
By 苏剑林 | 2009-10-01 | 26598位读者 | 引用
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 196424位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
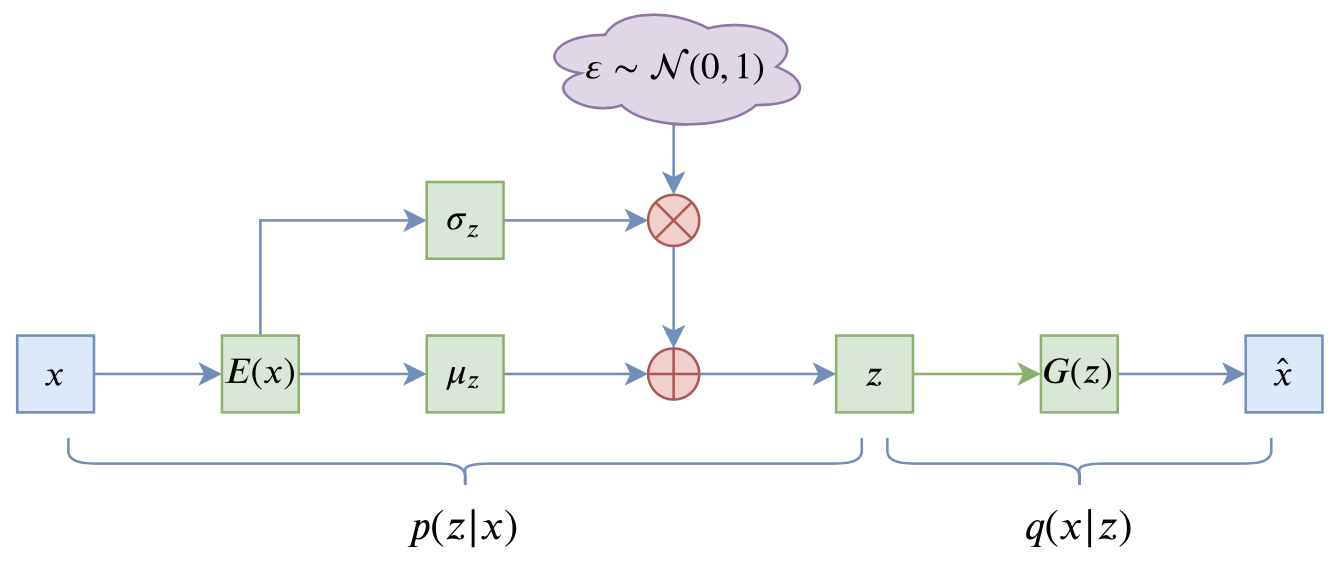
VAE训练流程图示
13
Feb
Designing GANs:又一个GAN生产车间
By 苏剑林 | 2020-02-13 | 33344位读者 | 引用在2018年的文章里《f-GAN简介:GAN模型的生产车间》笔者介绍了f-GAN,并评价其为GAN模型的“生产车间”,顾名思义,这是指它能按照固定的流程构造出很多不同形式的GAN模型来。前几天在arxiv上看到了新出的一篇论文《Designing GANs: A Likelihood Ratio Approach》(后面简称Designing GANs或原论文),发现它在做跟f-GAN同样的事情,但走的是一条截然不同的路(不过最后其实是殊途同归),整篇论文颇有意思,遂在此分享一番。
f-GAN回顾
从《f-GAN简介:GAN模型的生产车间》中我们可以知道,f-GAN的首要步骤是找到满足如下条件的函数$f$:
1、$f$是非负实数到实数的映射($\mathbb{R}^* \to \mathbb{R}$);
2、$f(1)=0$;
3、$f$是凸函数。
16
Apr
采样定理:有限个点构建出整个函数
By 苏剑林 | 2015-04-16 | 30541位读者 | 引用假设我们在听一首歌,那么听完这首歌之后,我们实际上在做这样的一个过程:耳朵接受了一段时间内的声波刺激,从而引起了大脑活动的变化。而这首歌,也就是这段时间内的声波,可以用时间$t$的函数$f(t)$描述,这个函数的区间是有限的,比如$t\in[0,T]$。接着假设另外一个场景——我们要用电脑录下我们唱的歌。这又是怎样一个过程呢?要注意电脑的信号是离散化的,而声波是连续的,因此,电脑要把歌曲记录下来,只能对信号进行采样记录。原则上来说,采集的点越多,就能够越逼真地还原我们的歌声。可是有一个问题,采集多少点才足够呢?在信息论中,一个著名的“采样定理”(又称香农采样定理,奈奎斯特采样定理)告诉我们:只需要采集有限个样本点,就能够完整地还原我们的输入信号来!
采集有限个点就能够还原一个连续的函数?这是怎么做到的?下面我们来解释这个定理。
任意给定一个函数,一般来说我们都可以将它做傅里叶变换:
$$F(\omega)=\int_{-\infty}^{+\infty} f(t)e^{i\omega t}dt\tag{1}$$
虽然我们的积分限写了正负无穷,但是由于$f(t)$是有限区间内的函数,所以上述积分区间实际上是有限的。

最近评论