






13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 380002位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 130702位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
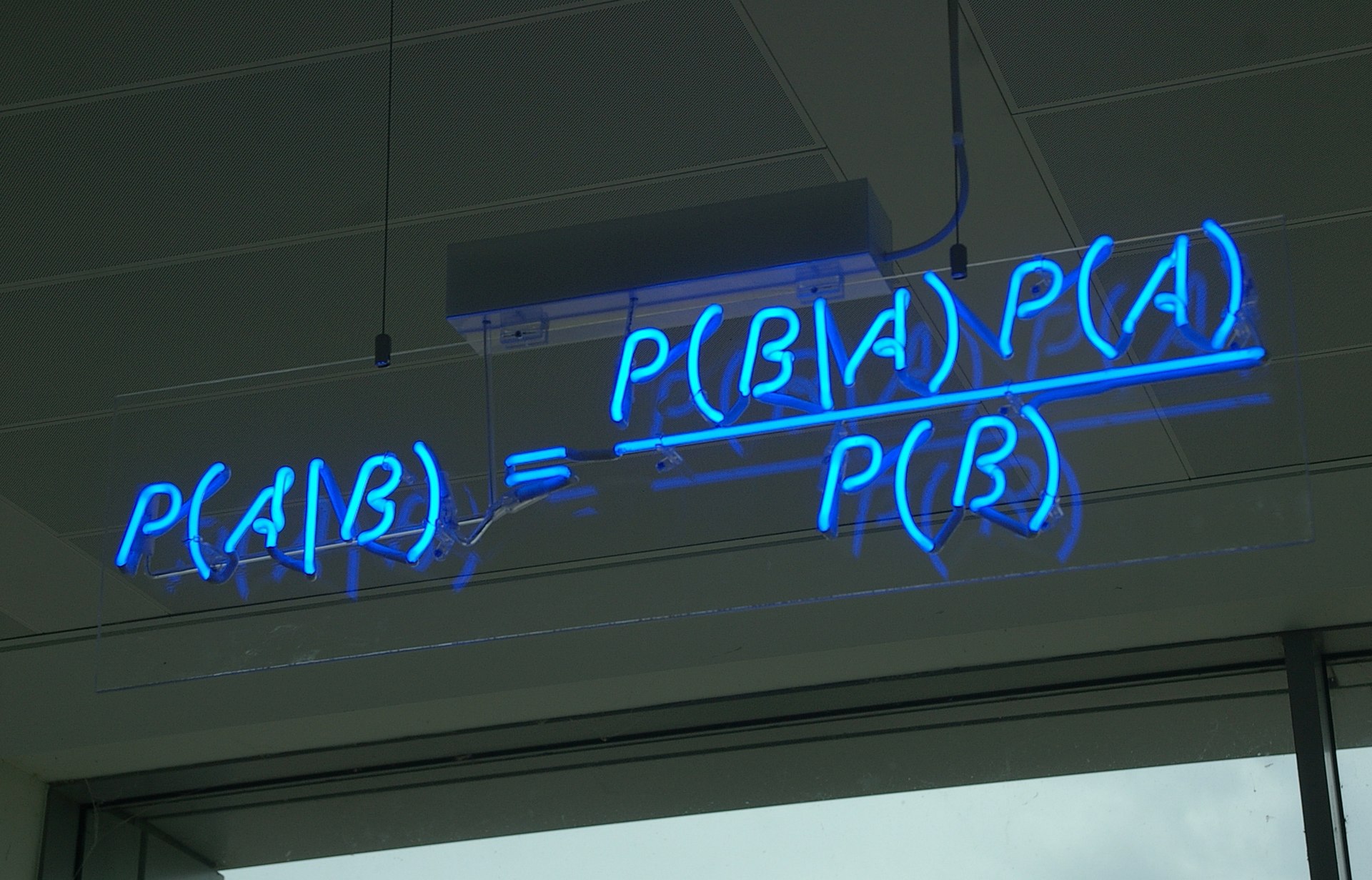
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 66055位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 36911位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
27
Jul
生成扩散模型漫谈(四):DDIM = 高观点DDPM
By 苏剑林 | 2022-07-27 | 194763位读者 | 引用相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》、《复分析:可视化方法》等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》介绍的DDIM模型就是经典的案例,本文一起来欣赏它。
思路分析
在《生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟DDIM紧密相关。具体来说,文章的推导路线可以简单归纳如下:
\begin{equation}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{推导}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{推导}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{近似}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{equation}
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 72483位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。
5
Dec
智能家居之小爱同学控制极米投影仪的简单方案
By 苏剑林 | 2022-12-05 | 32067位读者 | 引用前段时间买了一个极米投影仪,开始折腾才发现极米跟小米基本没啥关系,它根本无法跟小爱同学互动。在众多名字带“米”的品牌中,极米是为数不多的无法接入米家生态的品牌,想必有不少用户开始都会被极米这个名字误导,关键是极米投影仪还在小米商城上有得卖(捂脸)。
买都买了,还过了七天无理由,退是退不成了,只能试着折腾一下,看看能不能强行互动。
现有方案
首先网上搜了一下,网友给出的参考方案大体上有几种,一种是用“米家智能插座 + 上电自动开机”来控制开关机(事实上主要的联动就是开关机了),一种是接入Home Assistant后通过ADB控制,还有一种是修改遥控器,给遥控器加入红外模块,继而用小爱同学的红外遥控功能。
7
Dec
从局部到全局:语义相似度的测地线距离
By 苏剑林 | 2022-12-07 | 29768位读者 | 引用前段时间在最近的一篇论文《Unsupervised Opinion Summarization Using Approximate Geodesics》中学到了一个新的概念,叫做“测地线距离(Geodesic Distance)”,感觉有点意思,特来跟大家分享一下。
对笔者来说,“新”的不是测地线距离概念本身(以前学黎曼几何的时候就已经接触过了),而是语义相似度领域原来也可以巧妙地构造出测地线距离出来,并在某些场景下发挥作用。如果乐意,我们还可以说这是“流形上的语义相似度”,是不是瞬间就高级了不少?
论文梗概
首先,我们简单总结一下原论文的主要内容。顾名思义,论文的主题是摘要,通常我们的无监督摘要是这样做的:假设文章由$n$个句子$t_1,t_2,\cdots,t_n$组成,给每个句子设计打分函数$s(t_i)$(经典的是tf-idf及其变体),然后挑出打分最大的若干个句子作为摘要。当然,论文做的不是简单的摘要,而是“Opinion Summarization”,这个“Opinion”,我们可以理解为实现给定的主题或者中心$c$,摘要应该倾向于抽取出与$c$相关的句子,所以打分函数应该还应该跟$c$有关,即$s(t_i, c)$。

最近评论