






19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 130702位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
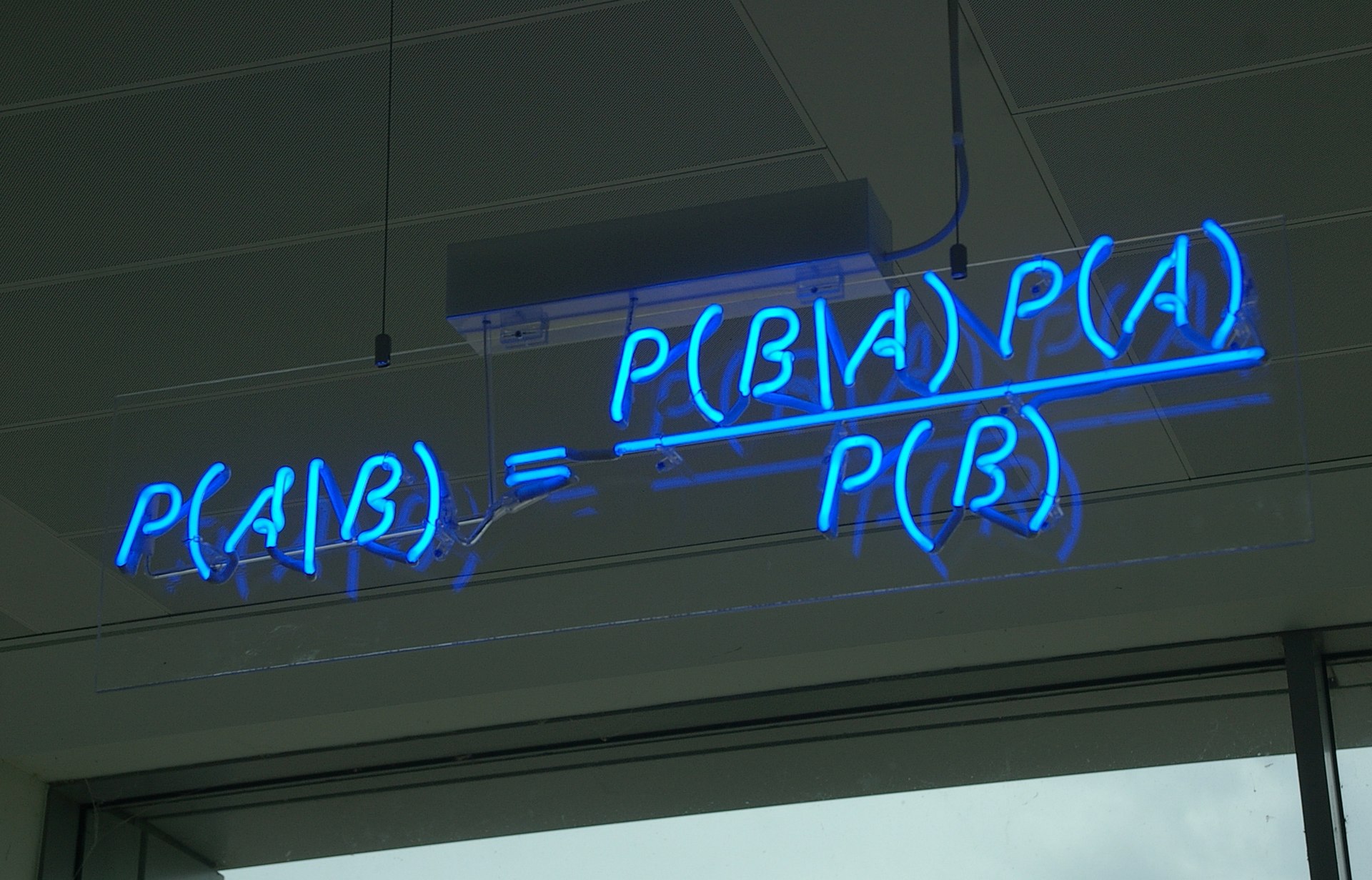
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 72486位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。
14
Sep
生成扩散模型漫谈(十):统一扩散模型(理论篇)
By 苏剑林 | 2022-09-14 | 68394位读者 | 引用老读者也许会发现,相比之前的更新频率,这篇文章可谓是“姗姗来迟”,因为这篇文章“想得太多”了。
通过前面九篇文章,我们已经对生成扩散模型做了一个相对全面的介绍。虽然理论内容很多,但我们可以发现,前面介绍的扩散模型处理的都是连续型对象,并且都是基于正态噪声来构建前向过程。而“想得太多”的本文,则希望能够构建一个能突破以上限制的扩散模型统一框架(Unified Diffusion Model,UDM):
1、不限对象类型(可以是连续型$\boldsymbol{x}$,也可以是离散型的$\boldsymbol{x}$);
2、不限前向过程(可以用加噪、模糊、遮掩、删减等各种变换构建前向过程);
3、不限时间类型(可以是离散型的$t$,也可以是连续型的$t$);
4、包含已有结果(可以推出前面的DDPM、DDIM、SDE、ODE等结果)。
这是不是太过“异想天开”了?有没有那么理想的框架?本文就来尝试一下。
21
Sep
生成扩散模型漫谈(十一):统一扩散模型(应用篇)
By 苏剑林 | 2022-09-21 | 41913位读者 | 引用在《生成扩散模型漫谈(十):统一扩散模型(理论篇)》中,笔者自称构建了一个统一的模型框架(Unified Diffusion Model,UDM),它允许更一般的扩散方式和数据类型。那么UDM框架究竟能否实现如期目的呢?本文通过一些具体例子来演示其一般性。
框架回顾
首先,UDM通过选择噪声分布$q(\boldsymbol{\varepsilon})$和变换$\boldsymbol{\mathcal{F}}$来构建前向过程
\begin{equation}\boldsymbol{x}_t = \boldsymbol{\mathcal{F}}_t(\boldsymbol{x}_0,\boldsymbol{\varepsilon}),\quad \boldsymbol{\varepsilon}\sim q(\boldsymbol{\varepsilon})\end{equation}
然后,通过如下的分解来实现反向过程$\boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)$的采样
\begin{equation}\hat{\boldsymbol{x}}_0\sim p(\boldsymbol{x}_0|\boldsymbol{x}_t)\quad \& \quad \boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\hat{\boldsymbol{x}}_0)\end{equation}
其中$p(\boldsymbol{x}_0|\boldsymbol{x}_t)$就是用$\boldsymbol{x}_t$预估$\boldsymbol{x}_0$的概率,一般用简单分布$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$来近似建模,训练目标基本上就是$-\log q(\boldsymbol{x}_0|\boldsymbol{x}_t)$或其简单变体。当$\boldsymbol{x}_0$是连续型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$一般就取条件正态分布;当$\boldsymbol{x}_0$是离散型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$可以选择自回归模型或者非自回归模型。
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 99934位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。
28
Mar
Google新作试图“复活”RNN:RNN能否再次辉煌?
By 苏剑林 | 2023-03-28 | 56440位读者 | 引用当前,像ChatGPT之类的LLM可谓是“风靡全球”。有读者留意到,几乎所有LLM都还是用最初的Multi-Head Scaled-Dot Attention,近年来大量的Efficient工作如线性Attention、FLASH等均未被采用。是它们版本效果太差,还是根本没有必要考虑效率?其实答案笔者在《线性Transformer应该不是你要等的那个模型》已经分析过了,只有序列长度明显超过hidden size时,标准Attention才呈现出二次复杂度,在此之前它还是接近线性的,它的速度比很多Efficient改进都快,而像GPT3用到了上万的hidden size,这意味着只要你的LLM不是面向数万长度的文本生成,那么用Efficient改进是没有必要的,很多时候速度没提上去,效果还降低了。
那么,真有数万甚至数十万长度的序列处理需求时,我们又该用什么模型呢?近日,Google的一篇论文《Resurrecting Recurrent Neural Networks for Long Sequences》重新优化了RNN模型,特别指出了RNN在处理超长序列场景下的优势。那么,RNN能否再次辉煌?
12
May
Transformer升级之路:9、一种全局长度外推的新思路
By 苏剑林 | 2023-05-12 | 55086位读者 | 引用说到Transformer无法处理超长序列的原因,大家的第一反应通常都是Self Attention的二次复杂度。但事实上,即便忽略算力限制,常规的Transformer也无法处理超长序列,因为它们的长度外推性(Length Extrapolation)并不好,具体表现为当输入序列明显超过训练长度时,模型的效果通常会严重下降。
尽管已有一些相关工作,但长度外推问题离实际解决还比较远。本文介绍笔者构思的一种参考方案,它可能是目前唯一一种可以用在生成模型上、具备全局依赖能力的长度外推方法。
方法回顾
长度外推,也称为长度泛化(Length Generalization),此前我们在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》已经介绍过部分工作。然而,它们各有各的问题。
13
Nov
【生活杂记】炒锅的尽头是铁锅
By 苏剑林 | 2023-11-13 | 53715位读者 | 引用
铁锅(网络图)
很多会下厨的同学估计都纠结过一件事情,那就是炒锅的选择。
对于炒锅的纠结,归根结底是不粘与方便的权衡。最简单的不粘锅自然是带涂层的不粘锅,如果家里的热源只有电磁炉,并且炒菜习惯比较温和,那么涂层不粘锅往往是最佳选择了。不过,一旦有了明火的燃气灶,又或者是比较喜欢爆炒,那么涂层锅可能就不是那么适合了,毕竟温度过高涂层总有脱落的风险,此时一般就考虑无涂层不粘锅。
无涂层不粘锅也有五花八门的选择,比如朴素的铁锅、带蜂窝纹的不锈钢锅、有钛锅、纯钛锅等等,价格大体上也单调递增。不过用到最后,我觉得大部分人都会回归到朴素的铁锅。

最近评论