






14
Mar
缓解交叉熵过度自信的一个简明方案
By 苏剑林 | 2023-03-14 | 31451位读者 | 引用众所周知,分类问题的常规评估指标是正确率,而标准的损失函数则是交叉熵,交叉熵有着收敛快的优点,但它并非是正确率的光滑近似,这就带来了训练和预测的不一致性问题。另一方面,当训练样本的预测概率很低时,交叉熵会给出一个非常巨大的损失(趋于$-\log 0^{+}=\infty$),这意味着交叉熵会特别关注预测概率低的样本——哪怕这个样本可能是“脏数据”。所以,交叉熵训练出来的模型往往有过度自信现象,即每个样本都给出较高的预测概率,这会带来两个副作用:一是对脏数据的过度拟合带来的效果下降,二是预测的概率值无法作为不确定性的良好指标。
围绕交叉熵的改进,学术界一直都有持续输出,目前这方面的研究仍处于“八仙过海,各显神通”的状态,没有标准答案。在这篇文章中,我们来学习一下论文《Tailoring Language Generation Models under Total Variation Distance》给出的该问题的又一种简明的候选方案。
20
Sep
自然数集中 N = ab + c 时 a + b + c 的最小值
By 苏剑林 | 2023-09-20 | 38106位读者 | 引用前天晚上微信群里有群友提出了一个问题:
对于一个任意整数$N > 100$,求一个近似算法,使得$N=a\times b+c$(其中$a,b,c$都是非负整数),并且令$a+b+c$尽量地小。
初看这道题,笔者第一感觉就是“这还需要算法?”,因为看上去自由度太大了,应该能求出个解析解才对,于是简单分析了一下之后就给出了个“答案”,结果很快就有群友给出了反例。这时,笔者才意识到这题并非那么平凡,随后正式推导了一番,总算得到了一个可行的算法。正当笔者以为这个问题已经结束时,另一个数学群的群友精妙地构造了新的参数化,证明了算法的复杂度还可以进一步下降!
整个过程波澜起伏,让笔者获益匪浅,遂将过程记录在此,与大家分享。
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 46117位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
15
Oct
让MathJax的数学公式随窗口大小自动缩放
By 苏剑林 | 2024-10-15 | 11201位读者 | 引用随着MathJax的出现和流行,在网页上显示数学公式便逐渐有了标准答案。然而,MathJax(包括其竞品KaTeX)只是负责将网页LaTeX代码转化为数学公式,对于自适应分辨率方面依然没有太好的办法。像本站一些数学文章,因为是在PC端排版好的,所以在PC端浏览效果尚可,但转到手机上看就可能有点难以入目了。
经过测试,笔者得到了一个方案,让MathJax的数学公式也能像图片一样,随着窗口大小而自适应缩放,从而尽量保证移动端的显示效果,在此跟大家分享一波。
背景思路
这个问题的起源是,即便在PC端进行排版,有时候也会遇到一些单行公式的长度超出了网页宽度,但又不大好换行的情况,这时候一个解决方案是用HTML代码手动调整一下公式的字体大小,比如
<span style="font-size:90%">
\begin{equation}一个超长的数学公式\end{equation}
</span>
29
Nov
从Hessian近似看自适应学习率优化器
By 苏剑林 | 2024-11-29 | 759位读者 | 引用这几天在重温去年的Meta的一篇论文《A Theory on Adam Instability in Large-Scale Machine Learning》,里边给出了看待Adam等自适应学习率优化器的新视角:它指出梯度平方的滑动平均某种程度上近似于在估计Hessian矩阵的平方,从而Adam、RMSprop等优化器实际上近似于二阶的Newton法。
这个角度颇为新颖,而且表面上跟以往的一些Hessian近似有明显的差异,因此值得我们去学习和思考一番。
牛顿下降
设损失函数为$\mathcal{L}(\boldsymbol{\theta})$,其中待优化参数为$\boldsymbol{\theta}$,我们的优化目标是
\begin{equation}\boldsymbol{\theta}^* = \mathop{\text{argmin}}_{\boldsymbol{\theta}} \mathcal{L}(\boldsymbol{\theta})\label{eq:loss}\end{equation}
假设$\boldsymbol{\theta}$的当前值是$\boldsymbol{\theta}_t$,Newton法通过将损失函数展开到二阶来寻求$\boldsymbol{\theta}_{t+1}$:
\begin{equation}\mathcal{L}(\boldsymbol{\theta})\approx \mathcal{L}(\boldsymbol{\theta}_t) + \boldsymbol{g}_t^{\top}(\boldsymbol{\theta} - \boldsymbol{\theta}_t) + \frac{1}{2}(\boldsymbol{\theta} - \boldsymbol{\theta}_t)^{\top}\boldsymbol{\mathcal{H}}_t(\boldsymbol{\theta} - \boldsymbol{\theta}_t)\end{equation}
23
Jan
分享一个slide:花式自然语言处理
By 苏剑林 | 2018-01-23 | 81903位读者 | 引用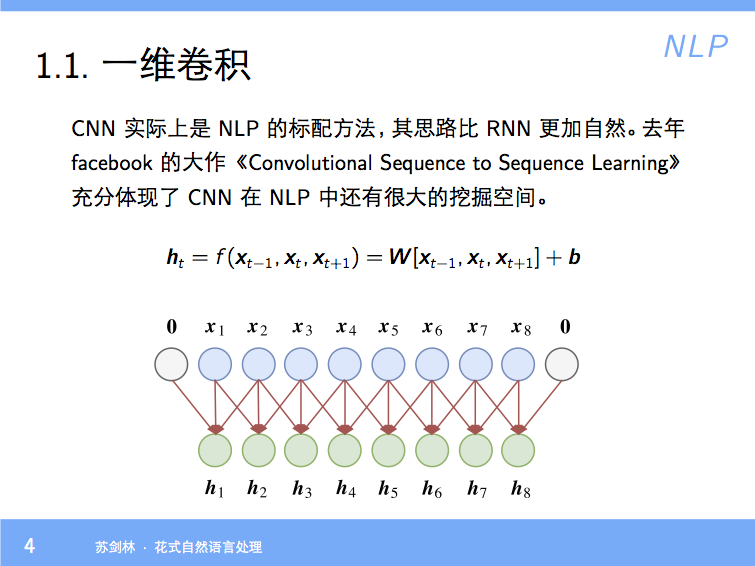
9
Aug
“凌星时刻变化”技术搜寻外行星
By 苏剑林 | 2010-08-09 | 18835位读者 | 引用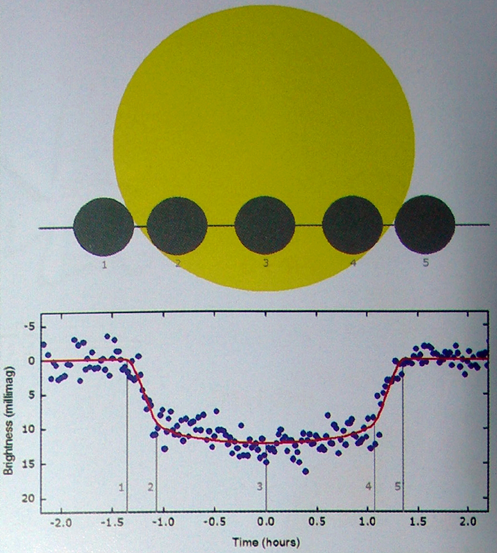
25
Apr
当概率遇上复变:解析概率
By 苏剑林 | 2014-04-25 | 28180位读者 | 引用每当看到数学的两个看似毫不相关的分支巧妙地联系了起来时,我总会为数学的神奇美丽惊叹不已。在很久以前,当我看到通过生成函数法把数论问题与复变函数方法结合起来,衍生出一门奇妙的“解析数论”时,我就惊叹过生成函数法的漂亮!可惜,一直都没有好好写整理这些内容。今天,当我在看李政道先生的《物理学中的数学方法》时,看到他把复变函数跟随机游动如鬼斧神工般了起来,再次让我拍案叫绝。最后实在压抑不住心中的激动,在此写写概率论和生成函数的事情。
数论与复变函数结合,就生成了一门“解析数论”,按照这个说法,概率与复变函数结合,应该就会有一门“解析概率”,但是我在网上搜索的时候,并没有发现这个名词的存在。经过如此,本文还是试用了这个名词。虽然这个名词没有流行,但事实上,解析概率的方法并不算新,它可以追溯到伟大的数学家拉普拉斯以及他的著作《分析概率论》中。尽管如此,这种巧妙漂亮的方法似乎没有得到大家应该有的充分的认识。
我觉得,即使作为一个简洁的计算工具,生成函数法这个美丽的技巧,也应该尽可能为科学爱好者所知,更不用说数学专业的朋友了。

最近评论