






17
Apr
梯度视角下的LoRA:简介、分析、猜测及推广
By 苏剑林 | 2023-04-17 | 69556位读者 | 引用随着ChatGPT及其平替的火热,各种参数高效(Parameter-Efficient)的微调方法也“水涨船高”,其中最流行的方案之一就是本文的主角LoRA了,它出自论文《LoRA: Low-Rank Adaptation of Large Language Models》。LoRA方法上比较简单直接,而且也有不少现成实现,不管是理解还是使用都很容易上手,所以本身也没太多值得细写的地方了。
然而,直接实现LoRA需要修改网络结构,这略微麻烦了些,同时LoRA给笔者的感觉是很像之前的优化器AdaFactor,所以笔者的问题是:能否从优化器角度来分析和实现LoRA呢?本文就围绕此主题展开讨论。
方法简介
以往的一些结果(比如《Exploring Aniversal Intrinsic Task Subspace via Prompt Tuning》)显示,尽管预训练模型的参数量很大,但每个下游任务对应的本征维度(Intrinsic Dimension)并不大,换句话说,理论上我们可以微调非常小的参数量,就能在下游任务取得不错的效果。
LoRA借鉴了上述结果,提出对于预训练的参数矩阵$W_0\in\mathbb{R}^{n\times m}$,我们不去直接微调$W_0$,而是对增量做低秩分解假设:
\begin{equation}W = W_0 + A B,\qquad A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}\end{equation}
14
Feb
生成扩散模型漫谈(十六):W距离 ≤ 得分匹配
By 苏剑林 | 2023-02-14 | 22747位读者 | 引用Wasserstein距离(下面简称“W距离”),是基于最优传输思想来度量两个概率分布差异程度的距离函数,笔者之前在《从Wasserstein距离、对偶理论到WGAN》等博文中也做过介绍。对于很多读者来说,第一次听说W距离,是因为2017年出世的WGAN,它开创了从最优传输视角来理解GAN的新分支,也提高了最优传输理论在机器学习中的地位。很长一段时间以来,GAN都是生成模型领域的“主力军”,直到最近这两年扩散模型异军突起,GAN的风头才有所下降,但其本身仍不失为一个强大的生成模型。
从形式上来看,扩散模型和GAN差异很明显,所以其研究一直都相对独立。不过,去年底的一篇论文《Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance》打破了这个隔阂:它证明了扩散模型的得分匹配损失可以写成W距离的上界形式。这意味着在某种程度上,最小化扩散模型的损失函数,实则跟WGAN一样,都是在最小化两个分布的W距离。
31
May
关于NBCE方法的一些补充说明和分析
By 苏剑林 | 2023-05-31 | 24613位读者 | 引用上周在《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》中,我们介绍了一种基于朴素贝叶斯来扩展LLM的Context长度的方案NBCE(Naive Bayes-based Context Extension)。由于它有着即插即用、模型无关、不用微调等优点,也获得了一些读者的认可,总的来说目前大家反馈的测试效果还算可以。
当然,部分读者在使用的时候也提出了一些问题。本文就结合读者的疑问和笔者的后续思考,对NBCE方法做一些补充说明和分析。
方法回顾
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个Context,我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,那么就需要估计$p(T|S_1, S_2,\cdots,S_n)$。根据朴素贝叶斯思想,我们得到
\begin{equation}\log p(T|S_1, S_2,\cdots,S_n) = \color{red}{(\beta + 1)\overline{\log p(T|S)}} - \color{green}{\beta\log p(T)} + \color{skyblue}{\text{常数}}\label{eq:nbce-2}\end{equation}
16
Sep
随机分词浅探:从Viterbi Decoding到Viterbi Sampling
By 苏剑林 | 2023-09-16 | 20970位读者 | 引用上一篇文章《大词表语言模型在续写任务上的一个问题及对策》发布后,很快就有读者指出可以在训练阶段引入带有随机性的分词结果来解决同样的问题,并且已经有论文和实现。经过进一步查阅学习,笔者发现这是一个名为Subword Regularization的技巧,最早应用在NMT(机器翻译)中,目前SentencePiece也有相应的实现。看起来这个技巧确实能缓解前述问题,甚至有助于增强语言模型的容错能力,所以就有了将它加进去BytePiece的想法。
那么问题来了,如何将确定性分词改为随机性分词呢?BytePiece是基于Unigram模型的,它通过Viterbi算法找最大概率的分词方案,既然有概率,是否就可以自然地导出随机采样?本文来讨论这个问题,并分享自己的解决方案。
13
Oct
EMO:基于最优传输思想设计的分类损失函数
By 苏剑林 | 2023-10-13 | 52254位读者 | 引用众所周知,分类任务的标准损失是交叉熵(Cross Entropy,等价于最大似然MLE,即Maximum Likelihood Estimation),它有着简单高效的特点,但在某些场景下也暴露出一些问题,如偏离评价指标、过度自信等,相应的改进工作也有很多,此前我们也介绍过一些,比如《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》、《如何训练你的准确率?》、《缓解交叉熵过度自信的一个简明方案》等。由于LLM的训练也可以理解为逐token的分类任务,默认损失也是交叉熵,因此这些改进工作在LLM流行的今天依然有一定的价值。
在这篇文章中,我们介绍一篇名为《EMO: Earth Mover Distance Optimization for Auto-Regressive Language Modeling》的工作,它基于最优传输思想提出了新的改进损失函数EMO,声称能大幅提高LLM的微调效果。其中细节如何?让我们一探究竟。
16
Oct
随机分词再探:从Viterbi Sampling到完美采样算法
By 苏剑林 | 2023-10-16 | 33247位读者 | 引用在文章《随机分词浅探:从Viterbi Decoding到Viterbi Sampling》中,笔者提出了一种名为“Viterbi Sampling”的随机分词算法,它只是在求最优解的Viterbi Decoding基础上进行小修改,保留了Viterbi算法的简单快速的特点,相比于已有的Subword Regularization明显更加高效。不过,知乎上的读者 @鶴舞 指出,当前的采样算法可能会在多次二选一“稀释”了部分方案的出现概率,直接后果是原本分数最高的切分并不是以最高概率出现。
经过仔细思考后,笔者发现相应的问题确实存在,当时为了尽快得到一种新的采样算法,在细节上的思考和处理确实比较粗糙。为此,本文将进一步完善Viterbi Sampling算法,并证明完善后的算法在效果上可以跟Subword Regularization等价的。
问题分析
首先,我们来看一下评论原话:
14
Jun
通向概率分布之路:盘点Softmax及其替代品
By 苏剑林 | 2024-06-14 | 24827位读者 | 引用不论是在基础的分类任务中,还是如今无处不在的注意力机制中,概率分布的构建都是一个关键步骤。具体来说,就是将一个$n$维的任意向量,转换为一个$n$元的离散型概率分布。众所周知,这个问题的标准答案是Softmax,它是指数归一化的形式,相对来说比较简单直观,同时也伴有很多优良性质,从而成为大部分场景下的“标配”。
尽管如此,Softmax在某些场景下也有一些不如人意之处,比如不够稀疏、无法绝对等于零等,因此很多替代品也应运而生。在这篇文章中,我们将简单总结一下Softmax的相关性质,并盘点和对比一下它的部分替代方案。
Softmax回顾
首先引入一些通用记号:$\boldsymbol{x} = (x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$是需要转为概率分布的$n$维向量,它的分量可正可负,也没有限定的上下界。$\Delta^{n-1}$定义为全体$n$元离散概率分布的集合,即
\begin{equation}\Delta^{n-1} = \left\{\boldsymbol{p}=(p_1,p_2,\cdots,p_n)\left|\, p_1,p_2,\cdots,p_n\geq 0,\sum_{i=1}^n p_i = 1\right.\right\}\end{equation}
之所以标注$n-1$而不是$n$,是因为约束$\sum\limits_{i=1}^n p_i = 1$定义了$n$维空间中的一个$n-1$维子平面,再加上$p_i\geq 0$的约束,$(p_1,p_2,\cdots,p_n)$的集合就只是该平面的一个子集,即实际维度只有$n-1$。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 21186位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
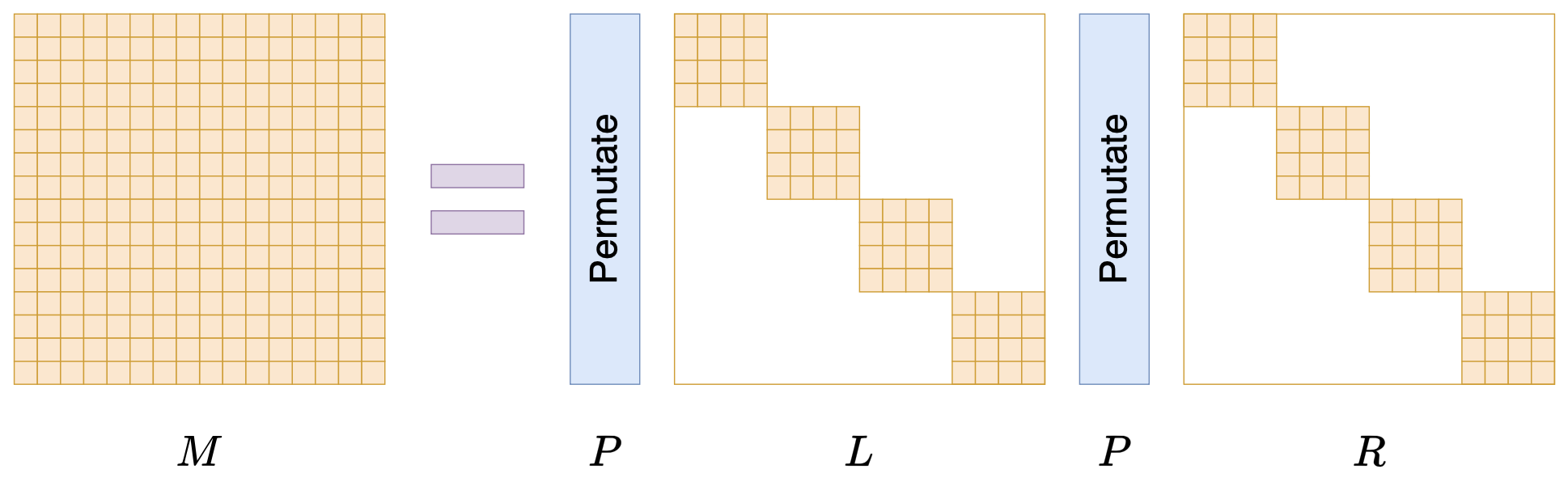
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。

最近评论