






5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 105896位读者 | 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
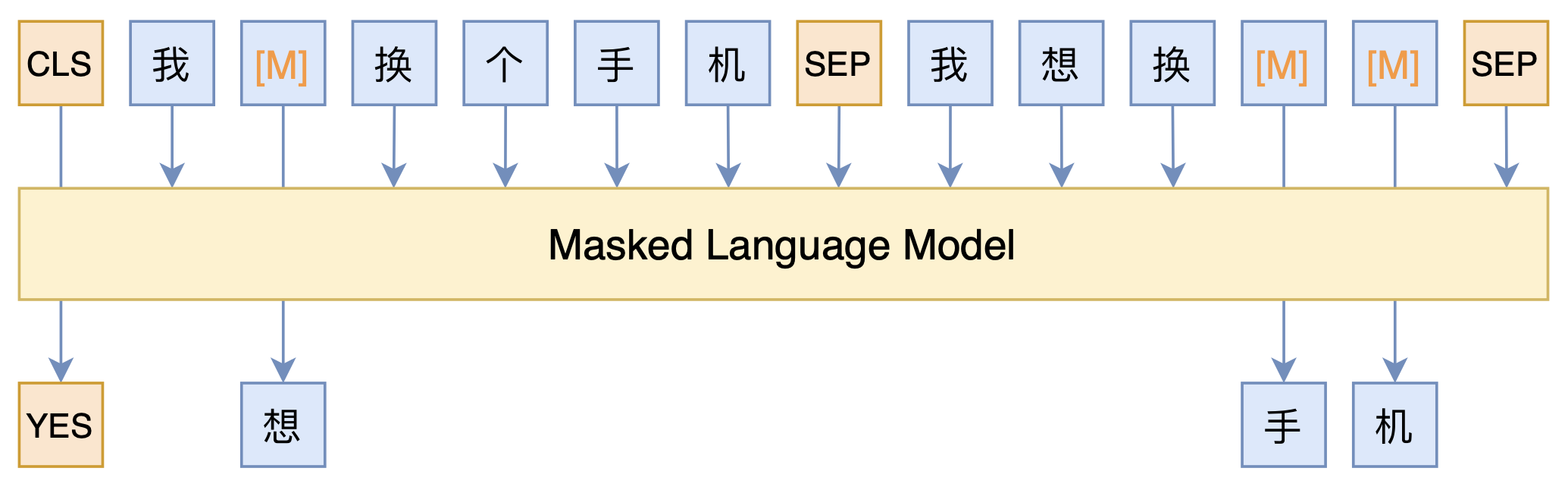
本文模型示意图
24
Sep
让人惊叹的Johnson-Lindenstrauss引理:应用篇
By 苏剑林 | 2021-09-24 | 35682位读者 | 引用上一篇文章中,我们比较详细地介绍了Johnson-Lindenstrauss引理(JL引理)的理论推导,这一篇我们来关注它的应用。
作为一个内容上本身就跟降维相关的结论,JL引理最基本的自然就是作为一个降维方法来用。但除了这个直接应用外,很多看似不相关的算法,比如局部敏感哈希(LSH)、随机SVD等,本质上也依赖于JL引理。此外,对于机器学习模型来说,JL引理通常还能为我们的维度选择提供一些理论解释。
降维的工具
JL引理提供了一个非常简单直接的“随机投影”降维思路:
给定$N$个向量$v_1,v_2,\cdots,v_N\in\mathbb{R}^m$,如果想要将它降到$n$维,那么只需要从$\mathcal{N}(0,1/n)$中采样一个$n\times m$矩阵$A$,然后$Av_1,Av_2,\cdots,Av_N$就是降维后的结果。
11
Apr
无监督语义相似度哪家强?我们做了个比较全面的评测
By 苏剑林 | 2021-04-11 | 143072位读者 | 引用一月份的时候,笔者写了《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,指出无监督语义相似度的SOTA模型BERT-flow其实可以通过一个简单的线性变换(白化操作,BERT-whitening)达到。随后,我们进一步完善了实验结果,写成了论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》。这篇博客将对这篇论文的内容做一个基本的梳理,并在5个中文语义相似度任务上进行了补充评测,包含了600多个实验结果。
方法概要
BERT-whitening的思路很简单,就是在得到每个句子的句向量$\{x_i\}_{i=1}^N$后,对这些矩阵进行一个白化(也就是PCA),使得每个维度的均值为0、协方差矩阵为单位阵,然后保留$k$个主成分,流程如下图:

BERT-whitening的基本流程
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 74310位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 59986位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
1
Sep
从三角不等式到Margin Softmax
By 苏剑林 | 2021-09-01 | 33428位读者 | 引用在《基于GRU和AM-Softmax的句子相似度模型》中我们介绍了AM-Softmax,它是一种带margin的softmax,通常用于用分类做检索的场景。当时通过图示的方式简单说了一下引入margin是因为“分类与排序的不等价性”,但没有比较定量地解释这种不等价性的来源。
在这篇文章里,我们来重提这个话题,从距离的三角不等式的角度来推导和理解margin的必要性。
三角不等式
平时,我们说的距离一般指比较直观的“欧氏距离”,但在数学上距离,距离又叫“度量”,它有公理化的定义,是指定义在某个集合上的二元函数$d(x,y)$,满足:
17
Sep
让人惊叹的Johnson-Lindenstrauss引理:理论篇
By 苏剑林 | 2021-09-17 | 83244位读者 | 引用今天我们来学习Johnson-Lindenstrauss引理,由于名字比较长,下面都简称“JL引理”。
个人认为,JL引理是每一个计算机科学的同学都必须了解的神奇结论之一,它是一个关于降维的著名的结果,它也是高维空间中众多反直觉的“维度灾难”现象的经典例子之一。可以说,JL引理是机器学习中各种降维、Hash等技术的理论基础,此外,在现代机器学习中,JL引理也为我们理解、调试模型维度等相关参数提供了重要的理论支撑。
对数的维度
JL引理,可以非常通俗地表达为:
通俗版JL引理: 塞下$N$个向量,只需要$\mathcal{O}(\log N)$维空间。
6
Jan
CoSENT(一):比Sentence-BERT更有效的句向量方案
By 苏剑林 | 2022-01-06 | 219631位读者 | 引用学习句向量的方案大致上可以分为无监督和有监督两大类,其中有监督句向量比较主流的方案是Facebook提出的“InferSent”,而后的“Sentence-BERT”进一步在BERT上肯定了它的有效性。然而,不管是InferSent还是Sentence-BERT,它们在理论上依然相当令人迷惑,因为它们虽然有效,但存在训练和预测不一致的问题,而如果直接优化预测目标cos值,效果往往特别差。
最近,笔者再次思考了这个问题,经过近一周的分析和实验,大致上确定了InferSent有效以及直接优化cos值无效的原因,并提出了一个优化cos值的新方案CoSENT(Cosine Sentence)。实验显示,CoSENT在收敛速度和最终效果上普遍都比InferSent和Sentence-BERT要好。
朴素思路
本文的场景是利用文本匹配的标注数据来构建句向量模型,其中所利用到的标注数据是常见的句子对样本,即每条样本是“(句子1, 句子2, 标签)”的格式,它们又大致上可以分类“是非类型”、“NLI类型”、“打分类型”三种,参考《用开源的人工标注数据来增强RoFormer-Sim》中的“分门别类”一节。
失效的Cos
简单起见,我们可以先只考虑“是非类型”的数据,即“(句子1, 句子2, 是否相似)”的样本。假设两个句子经过编码模型后分别得到向量$u,v$,由于检索阶段计算的是余弦相似度$\cos(u,v)=\frac{\langle u,v\rangle}{\Vert u\Vert \Vert v\Vert}$,所以比较自然的想法是设计基于$\cos(u,v)$的损失函数,比如
\begin{align}t\cdot (1 - \cos(u, v)) + (1 - t) \cdot (1 + \cos(u,v))\label{eq:cos-1}\\
t\cdot (1 - \cos(u, v))^2 + (1 - t) \cdot \cos^2(u,v)\label{eq:cos-2}
\end{align}

最近评论