






4
Jun
当概率遇上复变:随机游走与路径积分
By 苏剑林 | 2014-06-04 | 23514位读者 | 引用我们在上一篇文章中已经看到,随机游走的概率分布是正态的,而在概率论中可以了解到正态分布(几乎)是最重要的一种分布了。随机游走模型和正态分布的应用都很广,我们或许可以思考一个问题,究竟是随机游走造就了正态分布,还是正态分布造就了随机游走?换句话说,哪个更本质些?个人就自己目前所阅读到的内容来看,随机游走更本质些,随机游走正好对应着普遍存在的随机不确定性(比如每次测量的误差),它的分布正好就是正态分布,所以正态分布才应用得如此广泛——因为随机不确定性无处不在。
下面我们来考虑随机游走的另外一种描述方式,原则上来说,它更广泛,更深刻,其大名曰“路径积分”。
13
Jan
当概率遇上复变:从二项分布到泊松分布
By 苏剑林 | 2015-01-13 | 24669位读者 | 引用泊松分布,适合于描述单位时间内随机事件发生的次数的概率分布,如某一服务设施在一定时间内受到的服务请求的次数、汽车站台的候客人数等。[维基百科]泊松分布也可以作为小概率的二项分布的近似,其推导过程在一般的概率论教材都会讲到。可是一般教材上给出的证明并不是那么让人赏心悦目,如《概率论与数理统计教程》(第二版,茆诗松等编)的第98页就给出的证明过程。那么,哪个证明过程才更让人点赞呢?我认为是利用母函数的证明。
二项分布的母函数为
$$\begin{equation}(q+px)^n,\quad q=1-p\end{equation}$$
18
Oct
【理解黎曼几何】5. 黎曼曲率
By 苏剑林 | 2016-10-18 | 55665位读者 | 引用现在我们来关注黎曼曲率。总的来说,黎曼曲率提供了一种方案,让身处空间内部的人也能计算自身所处空间的弯曲程度。俗话说,“不识庐山真面目,只缘身在此山中”,还有“当局者迷,旁观者清”,等等,因此,能够身处空间之中而发现空间中的弯曲与否,是一件很了不起的事情,就好像我们已经超越了我们现有的空间,到了更高维的空间去“居高临下”那样。真可谓“心有多远,路就有多远,世界就有多远”。
如果站在更高维空间的角度看,就容易发现空间的弯曲。比如弯曲空间中有一条测地线,从更高维的空间看,它就是一条曲线,可以计算曲率等,但是在原来的空间看,它就是直的,测地线就是直线概念的一般化,因此不可能通过这种途径发现空间的弯曲性,必须有一些迂回的途径。可能一下子不容易想到,但是各种途径都殊途同归后,就感觉它是显然的了。
怎么更好地导出黎曼曲率来,使得它能够明显地反映出弯曲空间跟平直空间的本质区别呢?为此笔者思考了很长时间,看了不少参考书(《引力与时空》、《场论》、《引力论》等),比较了几种导出黎曼曲率的方式,简要叙述如下。
19
Oct
【理解黎曼几何】6. 曲率的计数与计算(Python)
By 苏剑林 | 2016-10-19 | 53515位读者 | 引用曲率的独立分量
黎曼曲率张量是一个非常重要的张量,当且仅当它全部分量为0时,空间才是平直的。它也出现在爱因斯坦的场方程中。总而言之,只要涉及到黎曼几何,黎曼曲率张量就必然是核心内容。
已经看到,黎曼曲率张量有4个指标,这也意味着它有$n^4$个分量,$n$是空间的维数。那么在2、3、4维空间中,它就有16、81、256个分量了,可见,要计算它,是一件相当痛苦的事情。幸好,这个张量有很多的对称性质,使得独立分量的数目大大减少,我们来分析这一点。
首先我们来导出黎曼曲率张量的一些对称性质,这部分内容是跟经典教科书是一致的。定义
$$R_{\mu\alpha\beta\gamma}=g_{\mu\nu}R^{\nu}_{\alpha\beta\gamma} \tag{50} $$
定义这个量的原因,要谈及逆变张量和协变张量的区别,我们这里主要关心几何观,因此略过对张量的详细分析。这个量被称为完全协变的黎曼曲率张量,有时候也直接叫做黎曼曲率张量,只要不至于混淆,一般不做区分。通过略微冗长的代数运算(在一般的微分几何、黎曼几何或者广义相对论教材中都有),可以得到
$$\begin{aligned}&R_{\mu\alpha\beta\gamma}=-R_{\mu\alpha\gamma\beta}\\
&R_{\mu\alpha\beta\gamma}=-R_{\alpha\mu\beta\gamma}\\
&R_{\mu\alpha\beta\gamma}=R_{\beta\gamma\mu\alpha}\\
&R_{\mu\alpha\beta\gamma}+R_{\mu\beta\gamma\alpha}+R_{\mu\gamma\alpha\beta}=0
\end{aligned} \tag{51} $$
22
Jul
概率视角下的线性模型:逻辑回归有解析解吗?
By 苏剑林 | 2021-07-22 | 75711位读者 | 引用我们知道,线性回归是比较简单的问题,它存在解析解,而它的变体逻辑回归(Logistic Regression)却没有解析解,这不能不说是一个遗憾。因为逻辑回归虽然也叫“回归”,但它实际上是用于分类问题的,而对于很多读者来说分类比回归更加常见。准确来说,我们说逻辑回归没有解析解,说的是“最大似然估计下逻辑回归没有解析解”。那么,这是否意味着,如果我们不用最大似然估计,是否能找到一个可用的解析解呢?
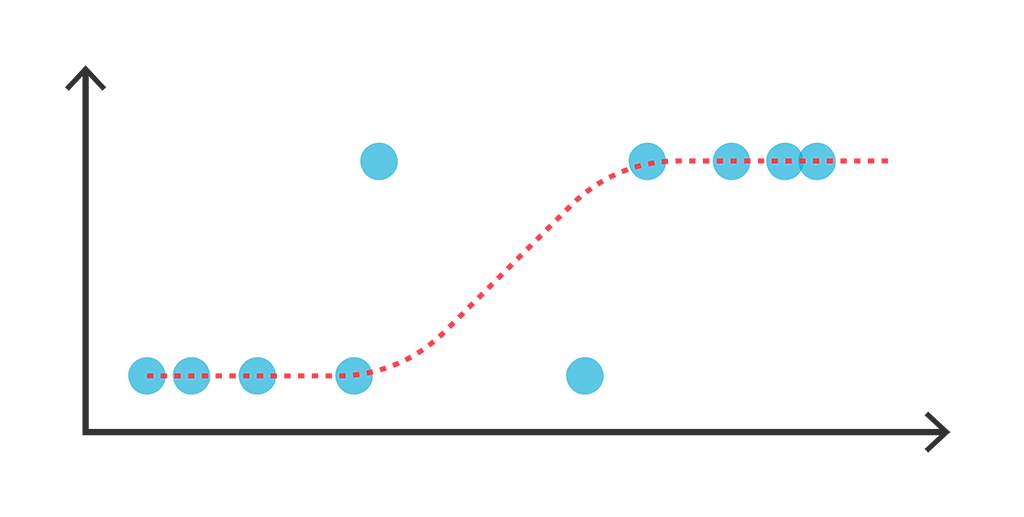
逻辑回归示意图
本文将会从非最大似然的角度,推导逻辑回归的一个解析解,简单的实验表明它效果不逊色于梯度下降求出来的最大似然解。此外,这个解析解还易于推广到单层Softmax多分类模型。
9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 61126位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计$x$的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本$x_1,x_2,\cdots,x_N\sim \tilde{p}(x)$的情况下,用一个待定的概率密度簇$q_{\theta}(x)$去拟合这批样本,拟合的目标一般是最小化负对数似然:
\begin{equation}\mathbb{E}_{x\sim \tilde{p}(x)}[-\log q_{\theta}(x)] = -\frac{1}{N}\sum_{i=1}^N \log q_{\theta}(x_i)\label{eq:mle}\end{equation}
24
Dec
概率分布的熵归一化(Entropy Normalization)
By 苏剑林 | 2021-12-24 | 47502位读者 | 引用在上一篇文章《从熵不变性看Attention的Scale操作》中,我们从熵不变性的角度推导了一个新的Attention Scale,并且实验显示具有熵不变性的新Scale确实能使得Attention的外推性能更好。这时候笔者就有一个很自然的疑问:
有没有类似L2 Normalization之类的操作,可以直接对概率分布进行变换,使得保持原始分布主要特性的同时,让它的熵为指定值?
笔者带着疑问搜索了一番,发现没有类似的研究,于是自己尝试推导了一下,算是得到了一个基本满意的结果,暂称为“熵归一化(Entropy Normalization)”,记录在此,供有需要的读者参考。
幂次变换
首先,假设$n$元分布$(p_1,p_2,\cdots,p_n)$,它的熵定义为
\begin{equation}\mathcal{H} = -\sum_i p_i \log p_i = \mathbb{E}[-\log p_i]\end{equation}
1
Jun
如何训练你的准确率?
By 苏剑林 | 2022-06-01 | 26426位读者 | 引用最近Arxiv上的一篇论文《EXACT: How to Train Your Accuracy》引起了笔者的兴趣,顾名思义这是介绍如何直接以准确率为训练目标来训练模型的。正好笔者之前也对此有过一些分析,如《函数光滑化杂谈:不可导函数的可导逼近》、《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》等, 所以带着之前的研究经验很快完成了论文的阅读,写下了这篇总结,并附上了最近关于这个主题的一些新思考。
失实的例子
论文开头指出,我们平时用的分类损失函数是交叉熵或者像SVM中的Hinge Loss,这两个损失均不能很好地拟合最终的评价指标准确率。为了说明这一点,论文举了一个很简单的例子:假设数据只有$\{(-0.25,-1),(0,-1),(0.25,,1)\}$三个点,$-1$和$1$分别代表负类和正类,待拟合模型是$f(x)=x-b$,$b$是参数,我们希望通过$\text{sign}(f(x))$来预测类别。如果用“sigmoid + 交叉熵”,那么损失函数就是$-\log \frac{1}{1+e^{-l \cdot f(x)}}$,$(x,l)$代表一对标签数据;如果用Hinge Loss,则是$\max(0, 1 - l\cdot f(x))$。

最近评论