






17
Sep
变分自编码器(四):一步到位的聚类方案
By 苏剑林 | 2018-09-17 | 349817位读者 | 引用由于VAE中既有编码器又有解码器(生成器),同时隐变量分布又被近似编码为标准正态分布,因此VAE既是一个生成模型,又是一个特征提取器。在图像领域中,由于VAE生成的图片偏模糊,因此大家通常更关心VAE作为图像特征提取器的作用。提取特征都是为了下一步的任务准备的,而下一步的任务可能有很多,比如分类、聚类等。本文来关心“聚类”这个任务。
一般来说,用AE或者VAE做聚类都是分步来进行的,即先训练一个普通的VAE,然后得到原始数据的隐变量,接着对隐变量做一个K-Means或GMM之类的。但是这样的思路的整体感显然不够,而且聚类方法的选择也让我们纠结。本文介绍基于VAE的一个“一步到位”的聚类思路,它同时允许我们完成无监督地完成聚类和条件生成。
理论
一般框架
回顾VAE的loss(如果没印象请参考《变分自编码器(二):从贝叶斯观点出发》):
$$KL\Big(p(x,z)\Big\Vert q(x,z)\Big) = \iint p(z|x)\tilde{p}(x)\ln \frac{p(z|x)\tilde{p}(x)}{q(x|z)q(z)} dzdx\tag{1}$$
通常来说,我们会假设$q(z)$是标准正态分布,$p(z|x),q(x|z)$是条件正态分布,然后代入计算,就得到了普通的VAE的loss。
10
Oct
变分自编码器 = 最小化先验分布 + 最大化互信息
By 苏剑林 | 2018-10-10 | 127163位读者 | 引用这篇文章很简短,主要描述的是一个很有用、也不复杂、但是我居然这么久才发现的事实~
在《深度学习的互信息:无监督提取特征》一文中,我们通过先验分布和最大化互信息两个loss的加权组合来得到Deep INFOMAX模型最后的loss。在那篇文章中,虽然把故事讲完了,但是某种意义上来说,那只是个拼凑的loss。而本文则要证明那个loss可以由变分自编码器自然地导出来。
过程
不厌其烦地重复一下,变分自编码器(VAE)需要优化的loss是
\begin{equation}\begin{aligned}&KL(\tilde{p}(x)p(z|x)\Vert q(z)q(x|z))\\
=&\iint \tilde{p}(x)p(z|x)\log \frac{\tilde{p}(x)p(z|x)}{q(x|z)q(z)} dzdx\end{aligned}\end{equation}
相关的论述在本博客已经出现多次了。VAE中既包含编码器,又包含解码器,如果我们只需要编码特征,那么再训练一个解码器就显得很累赘了。所以重点是怎么将解码器去掉。
其实再简单不过了,把VAE的loss分开两部分
几年前,笔者曾经以自己对矩阵的粗浅理解写了一个“理解矩阵”系列,其中有一篇《为什么只有方阵有行列式?》讨论了非方阵的行列式问题,里边给出了“非方针的行列式不好看”和“方阵的行列式就够了”的观点。本文来再次思考这个问题。
首先回顾方阵的行列式,其实行列式最重要的价值在于它的几何意义:
n维方阵的行列式的绝对值,等于它的各个行(或列)向量所张成的n维立体的超体积。
这个几何意义是行列式的一切重要性的源头,相关的讨论可以参考《行列式的点滴》,它也是我们讨论非方阵行列式的基础。
分析
对于方阵$\boldsymbol{A}_{n\times n}$来说,可以将它看成$n$个行向量的组合,也可以看成$n$个列向量的组合,不管是哪一种,行列式的绝对值都等于这$n$个向量所张成的$n$维立体的超体积。换句话说,对于方阵来说,行、列向量的区分不改变行列式。
对于非方阵$\boldsymbol{B}_{n \times k}$就不一样了,不失一般性,假设$n > k$。我们可以将它看成$n$个$k$维行向量的组合,也可以看成$k$个$n$维列向量的组合。非方针的行列式,应该也具有同样含义,即它们所张成的立体的超体积。
我们来看第一种情况,如果看成$n$个$k$维行向量,那么就得视为这$n$个向量张成的$n$维体的超体积了,但是要注意$n > k$,因此这$n$个向量必然线性相关,因此它们根本就张不成一个$n$维体,也许是一个$n-1$维体甚至更低,这样一来,它的$n$维体的超体积自然为0。
但是第二种情况就没有那么平凡了。如果看成$k$个$n$维列向量,那么这$k$个向量虽然是$n$维的,但它们张成的是一个$k$维体,这$k$维体的超体积未必为0。我们就以这个非平凡的体积作为非方阵行列式的定义好了。
14
Jan
基于CNN和序列标注的对联机器人
By 苏剑林 | 2019-01-14 | 43941位读者 | 引用缘起
前几天在量子位公众号上看到了《这个脑洞清奇的对联AI,大家都玩疯了》一文,觉得挺有意思,难得的是作者还整理并公开了数据集,所以决定自己尝试一下。
动手
“对对联”,我们可以看成是一个句子生成任务,可以用seq2seq完成,跟笔者之前写的《玩转Keras之seq2seq自动生成标题》一样,稍微修改一下输入即可。上面提到的文章所用的方法也是seq2seq,可见这算是标准做法了。
15
Nov
又一道川菜!媲美“开水白菜”的瓜燕穗肚
By 苏剑林 | 2018-11-15 | 35520位读者 | 引用
1
Mar
构造一个显式的、总是可逆的矩阵
By 苏剑林 | 2019-03-01 | 43335位读者 | 引用从《恒等式 det(exp(A)) = exp(Tr(A)) 赏析》一文我们得到矩阵$\exp(\boldsymbol{A})$总是可逆的,它的逆就是$\exp(-\boldsymbol{A})$。问题是$\exp(\boldsymbol{A})$只是一个理论定义,单纯这样写没有什么价值,因为它要把每个$\boldsymbol{A}^n$都算出来。
有没有什么具体的例子呢?有,本文来构造一个显式的、总是可逆的矩阵。
其实思路非常简单,假设$\boldsymbol{x},\boldsymbol{y}$是两个$k$维列向量,那么$\boldsymbol{x}\boldsymbol{y}^{\top}$就是一个$k\times k$的矩阵,我们就来考虑
\begin{equation}\begin{aligned}\exp\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)=&\sum_{n=0}^{\infty}\frac{\left(\boldsymbol{x}\boldsymbol{y}^{\top}\right)^n}{n!}\\
=&\boldsymbol{I}+\boldsymbol{x}\boldsymbol{y}^{\top}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{2}+\frac{\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}\boldsymbol{x}\boldsymbol{y}^{\top}}{6}+\dots\end{aligned}\end{equation}
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 101093位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 116866位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
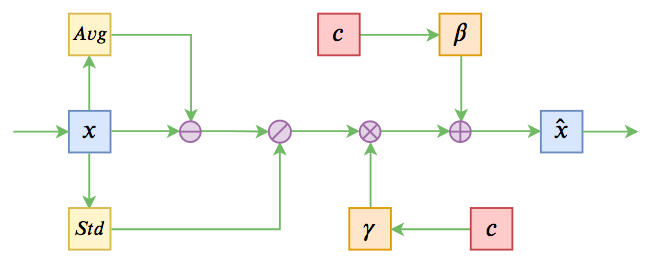
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。

最近评论