






24
Apr
最小熵原理(二):“当机立断”之词库构建
By 苏剑林 | 2018-04-24 | 83950位读者 | 引用在本文,我们介绍“套路宝典”第一式——“当机立断”:1、导出平均字信息熵的概念,然后基于最小熵原理推导出互信息公式;2、并且完成词库的无监督构建、给出一元分词模型的信息熵诠释,从而展示有关生成套路、识别套路的基本方法和技巧。
这既是最小熵原理的第一个使用案例,也是整个“套路宝典”的总纲。
你练或者不练,套路就在那里,不增不减。
为什么需要词语
从上一篇文章可以看到,假设我们根本不懂中文,那么我们一开始会将中文看成是一系列“字”随机组合的字符串,但是慢慢地我们会发现上下文是有联系的,它并不是“字”的随机组合,它应该是“套路”的随机组合。于是为了减轻我们的记忆成本,我们会去挖掘一些语言的“套路”。第一个“套路”,是相邻的字之间的组合定式,这些组合定式,也就是我们理解的“词”。
平均字信息熵
假如有一批语料,我们将它分好词,以词作为中文的单位,那么每个词的信息量是$-\log p_w$,因此我们就可以计算记忆这批语料所要花费的时间为
$$-\sum_{w\in \text{语料}}\log p_w\tag{2.1}$$
这里$w\in \text{语料}$是对语料逐词求和,不用去重。如果不分词,按照字来理解,那么需要的时间为
$$-\sum_{c\in \text{语料}}\log p_c\tag{2.2}$$
29
Sep
f-GAN简介:GAN模型的生产车间
By 苏剑林 | 2018-09-29 | 155866位读者 | 引用今天介绍一篇比较经典的工作,作者命名为f-GAN,他在文章中给出了通过一般的$f$散度来构造一般的GAN的方案。可以毫不夸张地说,这论文就是一个GAN模型的“生产车间”,它一般化的囊括了很多GAN变种,并且可以启发我们快速地构建新的GAN变种(当然有没有价值是另一回事,但理论上是这样)。
局部变分
整篇文章对$f$散度的处理事实上在机器学习中被称为“局部变分方法”,它是一种非常经典且有用的估算技巧。事实上本文将会花大部分篇幅介绍这种估算技巧在$f$散度中的应用结果。至于GAN,只不过是这个结果的基本应用而已。
f散度
首先我们还是对$f$散度进行基本的介绍。所谓$f$散度,是KL散度的一般化:
$$\begin{equation}\mathcal{D}_f(P\Vert Q) = \int q(x) f\left(\frac{p(x)}{q(x)}\right)dx\label{eq:f-div}\end{equation}$$
注意,按照通用的约定写法,括号内是$p/q$而不是$q/p$,大家不要自然而言地根据KL散度的形式以为是$q/p$。
26
Mar
科学空间浏览指南(FAQ)
By 苏剑林 | 2019-03-26 | 132165位读者 | 引用事实上,除了写博客内容,在这几年里,笔者是花了相当一部分时间来做科学空间的“表面功夫”,为此还专门学了一点php、css和js。虽然不敢说精益求精,但总体来说网站的浏览体验应该比前几年要好得多。
考虑到有些读者可能需要的功能,但一时半会未必能留意到,遂来整理一些站内技巧。
文章篇
什么环境阅读文章最佳?
两年前科学空间就已经加入了响应式设计,自动适应不同分辨率的屏幕。因此,不管哪个分辨率的环境应该都能看清文字内容,唯一的问题是,在小屏幕手机下公式可能会显示不全或者错位。为了较好地阅读公式,最好在7寸以上的屏幕上阅读。如果一定要用小屏幕的手机,可以考虑横屏阅读。
6
Nov
Keras:Tensorflow的黄金标准
By 苏剑林 | 2019-11-06 | 76587位读者 | 引用这两周投入了比较多的精力去做bert4keras的开发,除了一些API的规范化工作外,其余的主要工作量是构建预训练部分的代码。在昨天,预训练代码基本构建完毕,并同时在TPU/多GPU环境下测试通过,从而有志(有算力)改进预训练模型的同学多了一个选择。——这可能是目前最为清晰易懂的bert及其预训练代码。
预训练代码链接: https://github.com/bojone/bert4keras/tree/master/pretraining
经过这两周的开发(填坑),笔者的最大感想就是:Keras已经成为了tensorflow的黄金标准了。只要你的代码按照Keras的标准规范写,那可以轻松迁移到tf.keras中去,继而可以非常轻松地在TPU或多GPU环境下训练,真正的几乎是一劳永逸。相反,如果你的写法过于灵活,包括像笔者之前介绍的很多“移花接木”式的Keras技巧,就可能会有不少问题,甚至可能出现的一种情况是:就算你已经在多GPU上跑通了,在TPU上你也死活调不通。

Keras和Tensorflow
19
Jun
简述无偏估计和有偏估计
By 苏剑林 | 2019-06-19 | 82104位读者 | 引用对于大多数读者(包括笔者)来说,他们接触到的第一个有偏估计量,应该是方差
\begin{equation}\hat{\sigma}^2_{\text{有偏}} = \frac{1}{n}\sum_{i=1}^n \left(x_i - \hat{\mu}\right)^2,\quad \hat{\mu} = \frac{1}{n}\sum_{i=1}^n x_i\label{eq:youpianfangcha}\end{equation}
然后又了解到对应的无偏估计应该是
\begin{equation}\hat{\sigma}^2_{\text{无偏}} = \frac{1}{n-1}\sum_{i=1}^n \left(x_i - \hat{\mu}\right)^2\label{eq:wupianfangcha}\end{equation}
在很多人的眼里,公式$\eqref{eq:youpianfangcha}$才是合理的,怎么就有偏了?公式$\eqref{eq:wupianfangcha}$将$n$换成反直觉的$n-1$,反而就无偏了?
下面试图用尽量清晰的语言讨论一下无偏估计和有偏估计两个概念。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 80787位读者 | 引用
18
Jul
也来扯几句“全国青少年科技创新大赛”
By 苏剑林 | 2020-07-18 | 35061位读者 | 引用
13
Nov
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 90722位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
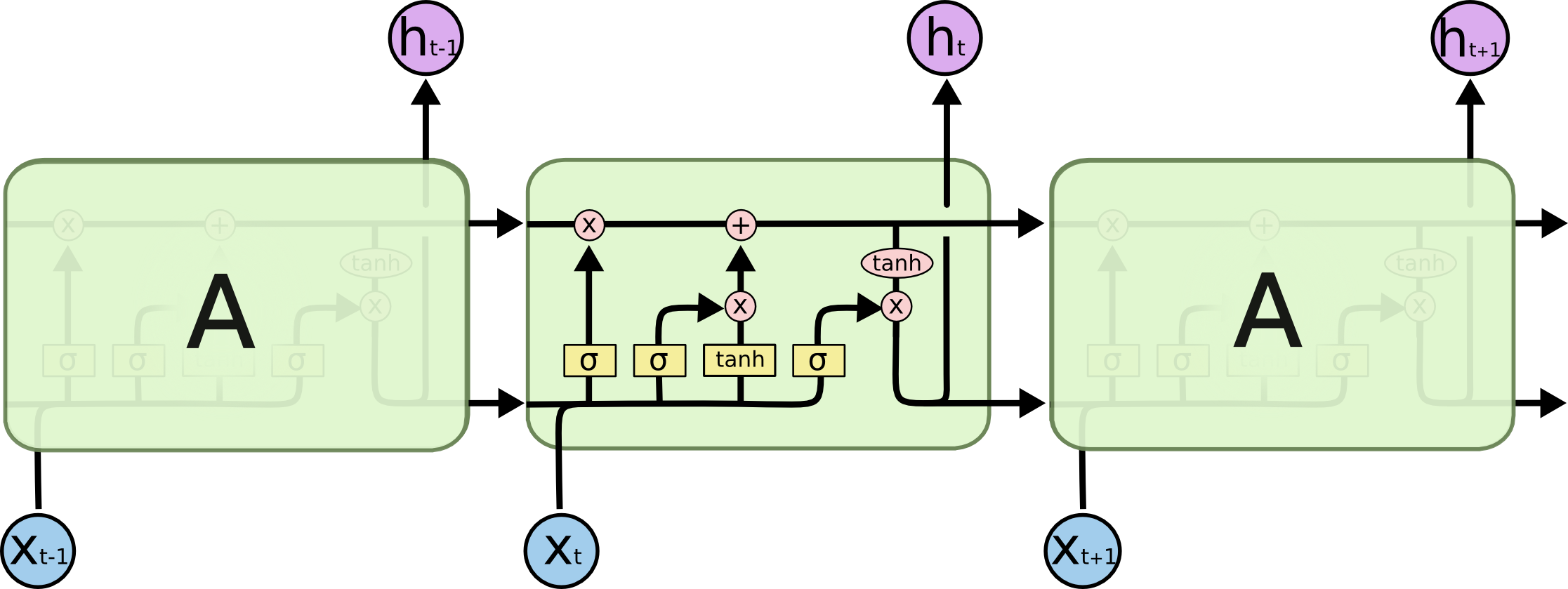
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。

最近评论