






19
Mar
Attention Residuals 回忆录
By 苏剑林 | 2026-03-19 | 19371位读者 | 引用这篇文章介绍我们的一个最新作品Attention Residuals(AttnRes),顾名思义,这是用Attention的思路去改进Residuals。
不少读者应该都听说过Pre Norm/Post Norm之争,但这说到底只是Residuals本身的“内斗”,包括后来很多Normalization的变化都是如此。比较有意思的变化是HC,它开始走扩大残差流的路线,但也许是效果上的不稳定,并没有引起太多反响。后来的故事大家可能都知道了,去年底DeepSeek的mHC改进了HC,并在更大规模实验上验证了它的有效性。
相比于进一步扩大残差流,我们选择了另一条激进的路线:直接在层间做Attention来替代Residuals。当然,全流程走通还是有很多细节和工作的,这里就简单回忆一下相关的心路历程。
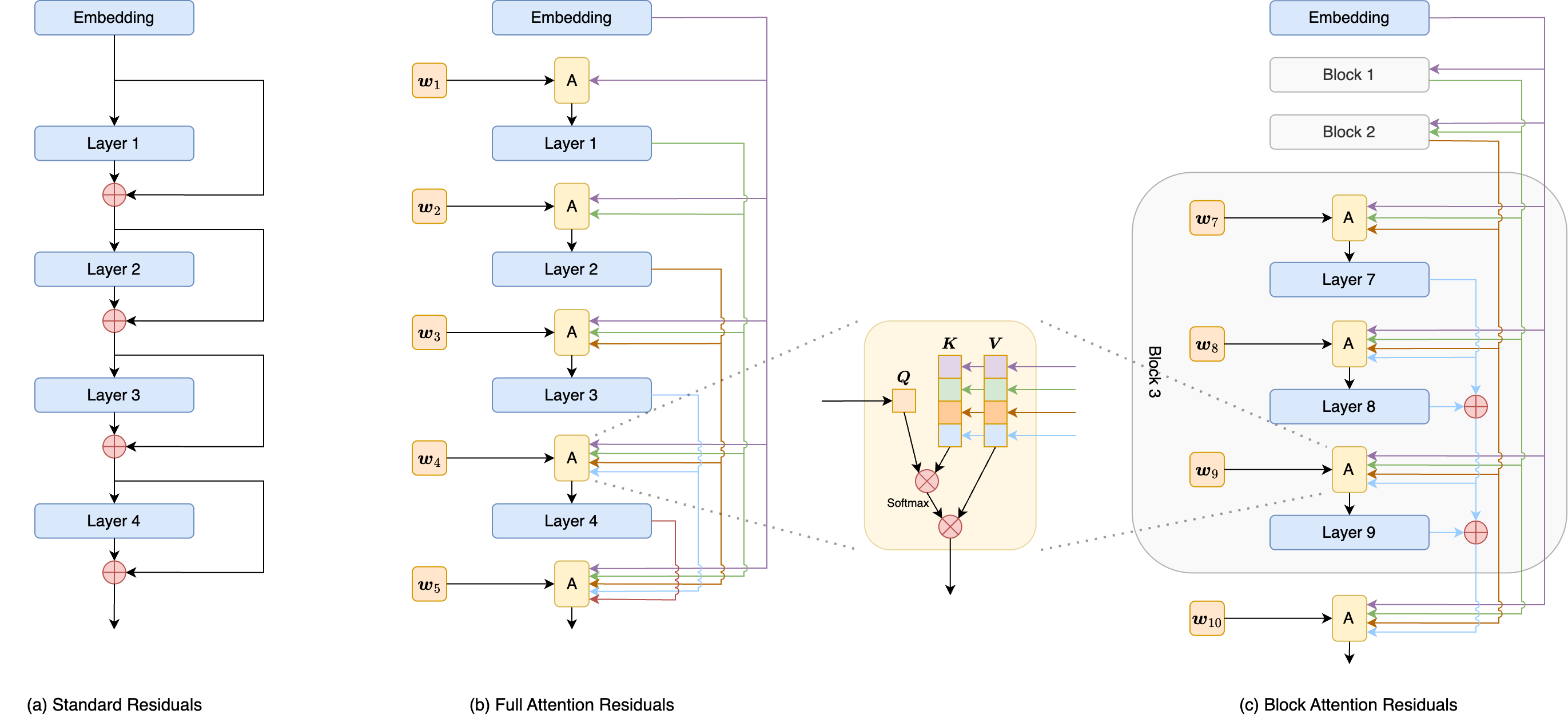
AttnRes示意图
8
Feb
MoE环游记:1、从几何意义出发
By 苏剑林 | 2025-02-08 | 159955位读者 | 引用前两年福至心灵之下,开了一个“Transformer升级之路”系列,陆续分享了主流Transformer架构的一些改进工作和个人思考,得到了部份读者的认可。这篇文章开始,我们沿着同样的风格,介绍当前另一个主流架构MoE(Mixture of Experts)。
MoE的流行自不必多说,近来火出圈的DeepSeek-V3便是MoE架构,传言GPT-4也是MoE架构,国内最近出的一些模型也有不少用上了MoE。然而,虽然MoE的研究由来已久,但其应用长时间内都不愠不火,大致上是从去年初的《Mixtral of Experts》开始,MoE才逐渐吸引大家的注意力,其显著优点是参数量大,但训练和推理成本都显著低。
但同时MoE也有一些难题,如训练不稳定、负载不均衡、效果不够好等,这也是它早年没有流行起来的主要原因。不过随着这两年关注度的提升,这些问题在很大程度上已经得到解决,我们在接下来的介绍中会逐一谈到这些内容。
18
May
基于量子化假设推导模型的尺度定律(Scaling Law)
By 苏剑林 | 2023-05-18 | 70286位读者 | 引用尺度定律(Scaling Law),指的是模型能力与模型尺度之间的渐近关系。具体来说,模型能力我们可以简单理解为模型的损失函数,模型尺度可以指模型参数量、训练数据量、训练步数等,所谓尺度定律,就是研究损失函数跟参数量、数据量、训练步数等变量的大致关系。《Scaling Laws for Neural Language Models》、《Training Compute-Optimal Large Language Models》等工作的实验结果表明,神经网络的尺度定律多数呈现“幂律(Power law)”的形式。
为什么会是幂律呢?能否从理论上解释呢?论文《The Quantization Model of Neural Scaling》基于“量子化”假设给出了一个颇为有趣的推导。本文一同来欣赏一下。
7
Mar
Tiger:一个“抠”到极致的优化器
By 苏剑林 | 2023-03-07 | 79729位读者 | 引用这段时间笔者一直在实验《Google新搜出的优化器Lion:效率与效果兼得的“训练狮”》所介绍的Lion优化器。之所以对Lion饶有兴致,是因为它跟笔者之前的关于理想优化器的一些想法不谋而合,但当时笔者没有调出好的效果,而Lion则做好了。
相比标准的Lion,笔者更感兴趣的是它在$\beta_1=\beta_2$时的特殊例子,这里称之为“Tiger”。Tiger只用到了动量来构建更新量,根据《隐藏在动量中的梯度累积:少更新几步,效果反而更好?》的结论,此时我们不新增一组参数来“无感”地实现梯度累积!这也意味着在我们有梯度累积需求时,Tiger已经达到了显存占用的最优解,这也是“Tiger”这个名字的来源(Tight-fisted Optimizer,抠门的优化器,不舍得多花一点显存)。
此外,Tiger还加入了我们的一些超参数调节经验,以及提出了一个防止模型出现NaN(尤其是混合精度训练下)的简单策略。我们的初步实验显示,Tiger的这些改动,能够更加友好地完成模型(尤其是大模型)的训练。
28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 41439位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。
19
Mar
为什么需要残差?一个来自DeepNet的视角
By 苏剑林 | 2022-03-19 | 98214位读者 | 引用在《训练1000层的Transformer究竟有什么困难?》中我们介绍了微软提出的能训练1000层Transformer的DeepNet技术。而对于DeepNet,读者一般也有两种反应,一是为此感到惊叹而点赞,另一则是觉得新瓶装旧酒没意思。出现后一种反应的读者,往往是因为DeepNet所提出的两个改进点——增大恒等路径权重和降低残差分支初始化——实在过于稀松平常,并且其他工作也出现过类似的结论,因此很难有什么新鲜感。
诚然,单从结论来看,DeepNet实在算不上多有意思,但笔者觉得,DeepNet的过程远比结论更为重要,它有意思的地方在于提供了一个简明有效的梯度量级分析思路,并可以用于分析很多相关问题,比如本文要讨论的“为什么需要残差”,它就可以给出一个比较贴近本质的答案。
增量爆炸
为什么需要残差?答案是有了残差才更好训练深层模型,这里的深层可能是百层、千层甚至万层。那么问题就变成了为什么没有残差就不容易训练深层模型呢?
11
Mar
门控注意力单元(GAU)还需要Warmup吗?
By 苏剑林 | 2022-03-11 | 69048位读者 | 引用在文章《训练1000层的Transformer究竟有什么困难?》发布之后,很快就有读者问到如果将其用到《FLASH:可能是近来最有意思的高效Transformer设计》中的“门控注意力单元(GAU)”,那结果是怎样的?跟标准Transformer的结果有何不同?本文就来讨论这个问题。
先说结论
事实上,GAU是非常容易训练的模型,哪怕我们不加调整地直接使用“Post Norm + Xavier初始化”,也能轻松训练个几十层的GAU,并且还不用Warmup。所以关于标准Transformer的很多训练技巧,到了GAU这里可能就无用武之地了...
为什么GAU能做到这些?很简单,因为在默认设置之下,理论上$\text{GAU}(\boldsymbol{x}_l)$相比$\boldsymbol{x}_l$几乎小了两个数量级,所以
\begin{equation}\boldsymbol{x}_{l+1} = \text{LN}(\boldsymbol{x}_l + \text{GAU}(\boldsymbol{x}_l))\approx \boldsymbol{x}_l\end{equation}
25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 192516位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。

最近评论