






8
Nov
模型优化漫谈:BERT的初始标准差为什么是0.02?
By 苏剑林 | 2021-11-08 | 86508位读者 | 引用前几天在群里大家讨论到了“Transformer如何解决梯度消失”这个问题,答案有提到残差的,也有提到LN(Layer Norm)的。这些是否都是正确答案呢?事实上这是一个非常有趣而综合的问题,它其实关联到挺多模型细节,比如“BERT为什么要warmup?”、“BERT的初始化标准差为什么是0.02?”、“BERT做MLM预测之前为什么还要多加一层Dense?”,等等。本文就来集中讨论一下这些问题。
梯度消失说的是什么意思?
在文章《也来谈谈RNN的梯度消失/爆炸问题》中,我们曾讨论过RNN的梯度消失问题。事实上,一般模型的梯度消失现象也是类似,它指的是(主要是在模型的初始阶段)越靠近输入的层梯度越小,趋于零甚至等于零,而我们主要用的是基于梯度的优化器,所以梯度消失意味着我们没有很好的信号去调整优化前面的层。
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 29723位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
7
Mar
Tiger:一个“抠”到极致的优化器
By 苏剑林 | 2023-03-07 | 40751位读者 | 引用这段时间笔者一直在实验《Google新搜出的优化器Lion:效率与效果兼得的“训练狮”》所介绍的Lion优化器。之所以对Lion饶有兴致,是因为它跟笔者之前的关于理想优化器的一些想法不谋而合,但当时笔者没有调出好的效果,而Lion则做好了。
相比标准的Lion,笔者更感兴趣的是它在$\beta_1=\beta_2$时的特殊例子,这里称之为“Tiger”。Tiger只用到了动量来构建更新量,根据《隐藏在动量中的梯度累积:少更新几步,效果反而更好?》的结论,此时我们不新增一组参数来“无感”地实现梯度累积!这也意味着在我们有梯度累积需求时,Tiger已经达到了显存占用的最优解,这也是“Tiger”这个名字的来源(Tight-fisted Optimizer,抠门的优化器,不舍得多花一点显存)。
此外,Tiger还加入了我们的一些超参数调节经验,以及提出了一个防止模型出现NaN(尤其是混合精度训练下)的简单策略。我们的初步实验显示,Tiger的这些改动,能够更加友好地完成模型(尤其是大模型)的训练。
28
Aug
Lion/Tiger优化器训练下的Embedding异常和对策
By 苏剑林 | 2023-08-28 | 26875位读者 | 引用打从在《Tiger:一个“抠”到极致的优化器》提出了Tiger优化器之后,Tiger就一直成为了我训练模型的“标配”优化器。最近笔者已经尝试将Tiger用到了70亿参数模型的预训练之中,前期效果看上来尚可,初步说明Tiger也是能Scale Up的。不过,在查看训练好的模型权重时,笔者发现Embedding出现了一些异常值,有些Embedding的分量达到了$\pm 100$的级别。
经过分析,笔者发现类似现象并不会在Adam中出现,这是Tiger或者Lion这种带符号函数$\text{sign}$的优化器特有的问题,对此文末提供了两种参考解决方案。本文将记录笔者的分析过程,供大家参考。
现象
接下来,我们的分析都以Tiger优化器为例,但分析过程和结论同样适用于Lion。
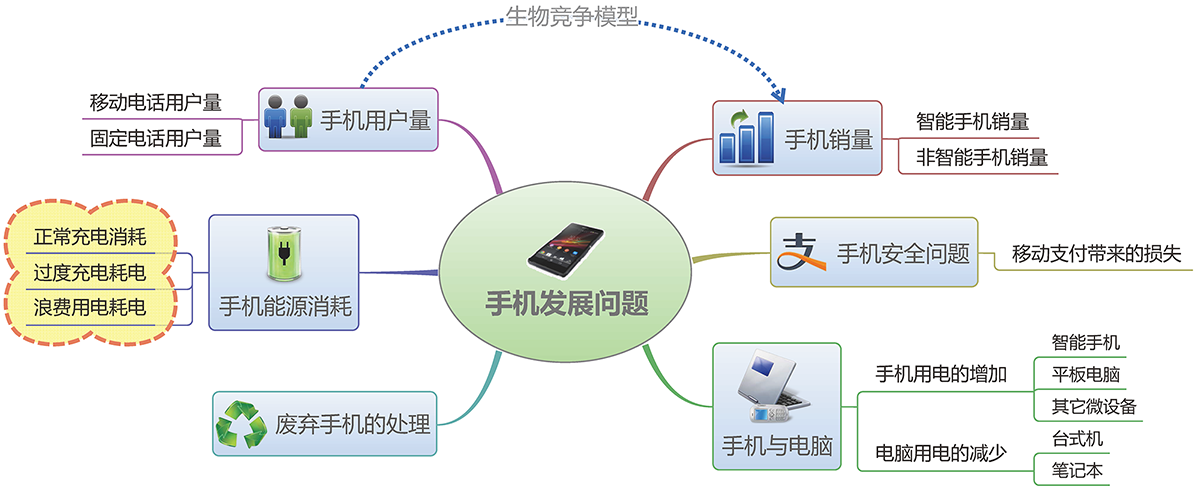
思维导图
这学期的数学建模课,对笔者来说,基本上就是一个锻炼论文写作和Python技能的过程。不过是写论文还是写博客,我都致力于写出符合自己审美观的作品,因此我才会选择$\LaTeX$,我才会选择Python。$\LaTeX$写出来的科学论文是公认的标准而好看的格式,而Python,的确可以作出漂亮的图,也可以简洁地完成所需要的数值计算。我越来越发现,在数学建模、写作方面,除了必不可少的符号推导部分(这部分只能用Mathematica),我已经离不开Python了。
为什么还要求漂亮?内容好不就行了吗?的确,内容才是主要的,但是如果能把展示效果美化一下,而且又不耗费更多的功夫,那么何乐而不为呢?
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 18624位读者 | 引用
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 66760位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 220552位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
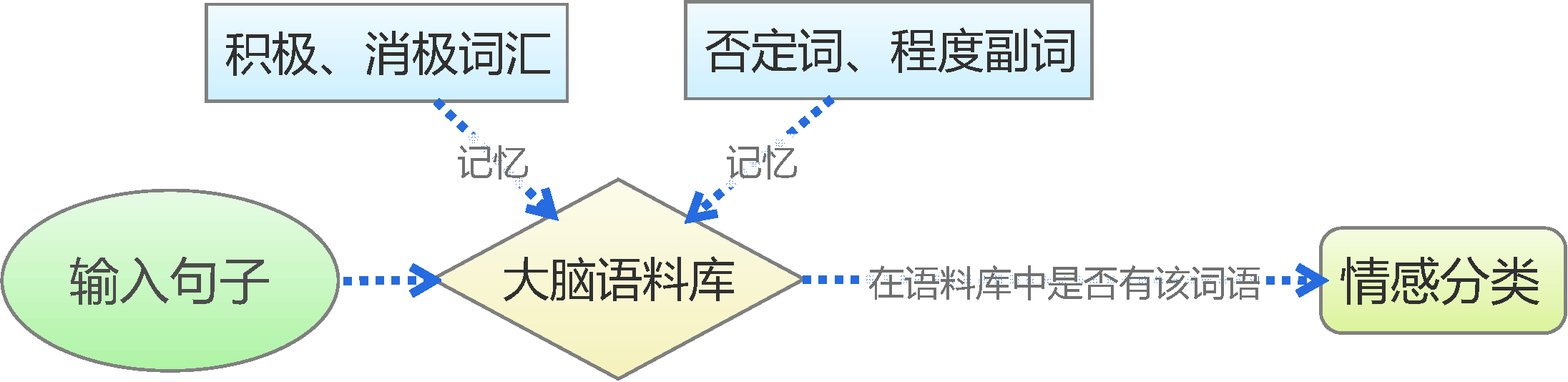
人的最简单的判断思维

最近评论