






6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 160355位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
27
Sep
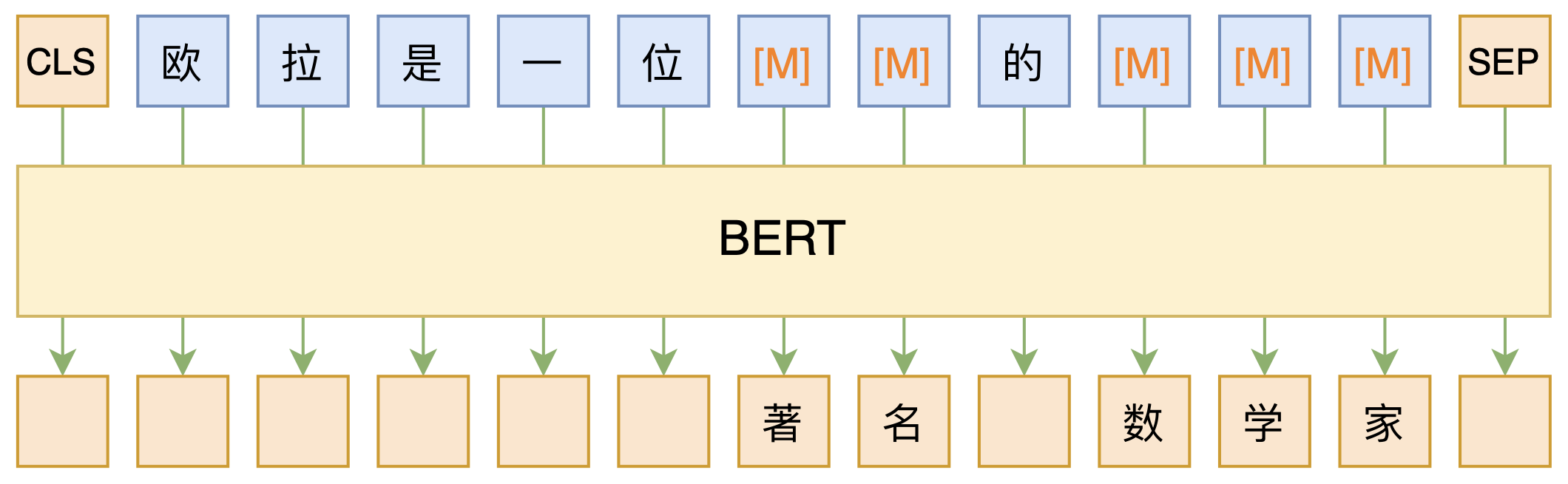
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 149262位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 83866位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
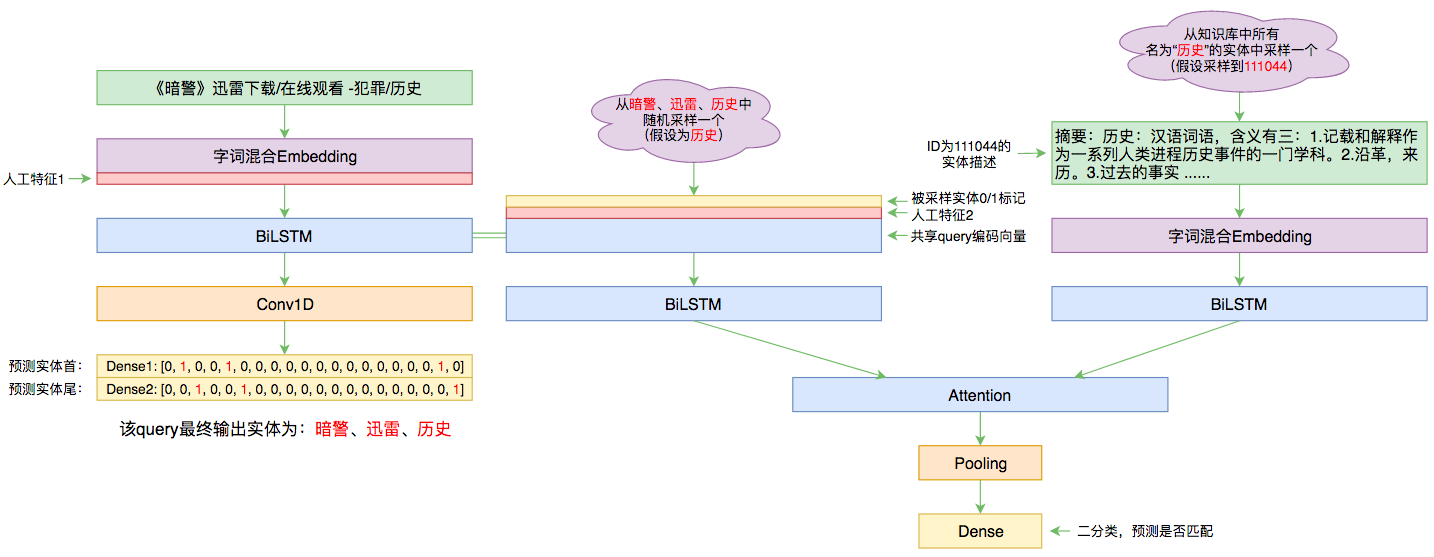
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 75405位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
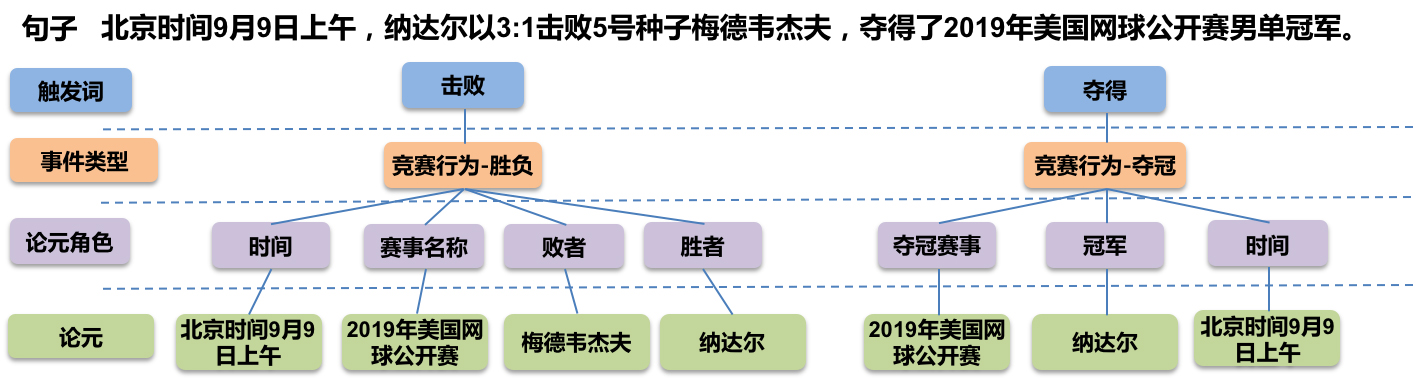
标准的事件抽取样本(图片来自百度DuEE的GitHub)
24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 91766位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。
代码
25
Dec
从loss的硬截断、软化到focal loss
By 苏剑林 | 2017-12-25 | 191765位读者 | 引用前言
今天在QQ群里的讨论中看到了focal loss,经搜索它是Kaiming大神团队在他们的论文《Focal Loss for Dense Object Detection》提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。本质上讲,focal loss就是一个解决分类问题中类别不平衡、分类难度差异的一个loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:
《如何评价kaiming的Focal Loss for Dense Object Detection?》
看到这个loss,开始感觉很神奇,感觉大有用途。因为在NLP中,也存在大量的类别不平衡的任务。最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好loss。
接着我再仔细对比了一下,我发现这个loss跟我昨晚构思的一个loss具有异曲同工之理!这就促使我写这篇博文了。我将从我自己的思考角度出发,来分析这个问题,最后得到focal loss,也给出我昨晚得到的类似的loss。
22
Aug
【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
By 苏剑林 | 2016-08-22 | 460915位读者 | 引用关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM
19
Aug
【中文分词系列】 3. 字标注法与HMM模型
By 苏剑林 | 2016-08-19 | 84006位读者 | 引用在这篇文章中,我们暂停查词典方法的介绍,转而介绍字标注的方法。前面已经提到过,字标注是通过给句子中每个字打上标签的思路来进行分词,比如之前提到过的,通过4标签来进行标注(single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾。均只取第一个字母。),这样,“为人民服务”就可以标注为“sbebe”了。4标注不是唯一的标注方式,类似地还有6标注,理论上来说,标注越多会越精细,理论上来说效果也越好,但标注太多也可能存在样本不足的问题,一般常用的就是4标注和6标注。
值得一提的是,这种通过给每个字打标签、进而将问题转化为序列到序列的学习,不仅仅是一种分词方法,还是一种解决大量自然语言问题的思路,比如命名实体识别等任务,同样可以用标注的方法来做。回到分词来,通过字标注法来进行分词的模型有隐马尔科夫模型(HMM)、最大熵模型(ME)、条件随机场模型(CRF),它们在精度上都是递增的,据说目前公开评测中分词效果最好的是4标注的CRF。然而,在本文中,我们要讲解的是最不精确的HMM。因为在我看来,它并非一个特定的模型,而是解决一大类问题的通用思想,一种简化问题的学问。
这一切,还得从概率模型谈起。

最近评论