






24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 59822位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 56908位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 71618位读者 | 引用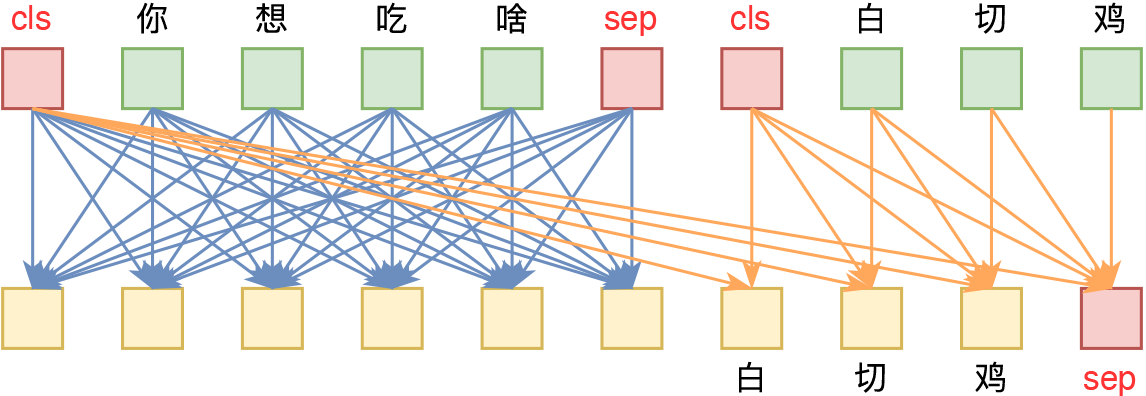
7
Jun
相对位置编码Transformer的一个理论缺陷与对策
By 苏剑林 | 2022-06-07 | 92302位读者 | 引用位置编码是Transformer中很重要的一环,在《让研究人员绞尽脑汁的Transformer位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将Transformer的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多NLP/CV的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在Softmax之前的Attention矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得Transformer无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。
简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射 \begin{equation}\begin{array}{lc} \text{输入:} & [0, 0, \cdots, 0, 0] \\ & \downarrow\\ \text{输出:} & [1, 2, \cdots, n-1, n] \end{array}\end{equation}


生日祝福
2012年3月28日,我19岁了。
三月是一个很美的月份,我的很多值得纪念的日子都在三月发生,还有好友们都在三月接二连三地生日,几乎让我措手不及了,呵呵。我的同桌黄金,好友家益,还有我自己都在这个月成为十九岁的孩子了。算起来,我应该是“最年轻”的了^_^

3-25-聚餐合照
我的生日收到了许多人的祝福,这让我觉得很意外,我一直觉得,我不善于人际交往,所以不应该会有太多人关注我,但惊喜在我身上发生了。谢谢大家。
人生如梦,繁星流动,和你同路,从不相识开始心接近,默默以真挚待人......这是《朋友》的歌词,也是我们之间的真实写照。感谢上天,让我的人生之路上有你们的相伴,人生因为你们而更加精彩。愿能够与你们一起度过、奋斗过更多的日子!我们相约,我们是一辈子的朋友!
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 44894位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
30
Jul
素数之美1:所有素数之积
By 苏剑林 | 2014-07-30 | 32822位读者 | 引用在之前的欧拉数学中,我们计算过所有素数的倒数之和,得出素数的倒数之和是发散的,从而这也是一个关于素数个数为无穷的证明。在本篇文章中,我们尝试计算所有素数之积,通过一个简单的技巧,得到素数之积的一个上限(以后我们也会计算下限),从而也得到$\pi(n)$的一个上限公式。更重要的,该估计是初等地证明Bertrand假设(说的是n与2n之间定有一个素数)的重要基础之一。本文内容部分参考自《数学天书中的证明》和《解析和概率数论导引》。
素数之积
笔者已经说过,数论的神奇之处就是它总是出人意料地把数学的不同领域联系了起来。读者很快就可以看到,本文的证明和组合数学有重要联系(但仅仅是简单的联系)。关于素数之积,我们有以下结论:
不超过$n$的所有素数之积小于$4^{n-1}$。

最近评论