






13
Oct
基于fine tune的图像分类(百度分狗竞赛)
By 苏剑林 | 2017-10-13 | 28436位读者 | 引用
baidu_jingsai
前两年百度的大数据竞赛都是自然语言处理方面的,今年画风一转,变成了图像的细颗粒度分类,赛题内容就是将宠物狗归为100类中的其中一类。这个任务本身是很平凡的,做法也很常规,无外乎就是数据扩增、imagenet模型的fine tune、模型集成三个方面。笔者并不擅长于模型集成,只做了前面两个步骤,成绩也非常一般(准确率80%上下)。但感觉里边的某些代码可能对读者有帮助,遂共享一翻。下面结合着代码来讲解。
比赛官网(随时有失效的可能):http://js.baidu.com
模型
模型主要用tensorflow+keras实现。首先自然是导入各种模块
#! -*- coding:utf-8 -*-
import numpy as np
from scipy import misc
import tensorflow as tf
from keras.applications.xception import Xception,preprocess_input
from keras.layers import Input,Dense,Lambda,Embedding
from keras.layers.merge import multiply
from keras import backend as K
from keras.models import Model
from keras.optimizers import SGD
from tqdm import tqdm
import glob
np.random.seed(2017)
tf.set_random_seed(2017)
13
Oct
【随拍】门口的广州塔
By 苏剑林 | 2017-10-13 | 28476位读者 | 引用
14
Oct
训练集、验证集和测试集的意义
By 苏剑林 | 2017-10-14 | 50222位读者 | 引用
23
Jan
分享一个slide:花式自然语言处理
By 苏剑林 | 2018-01-23 | 81675位读者 | 引用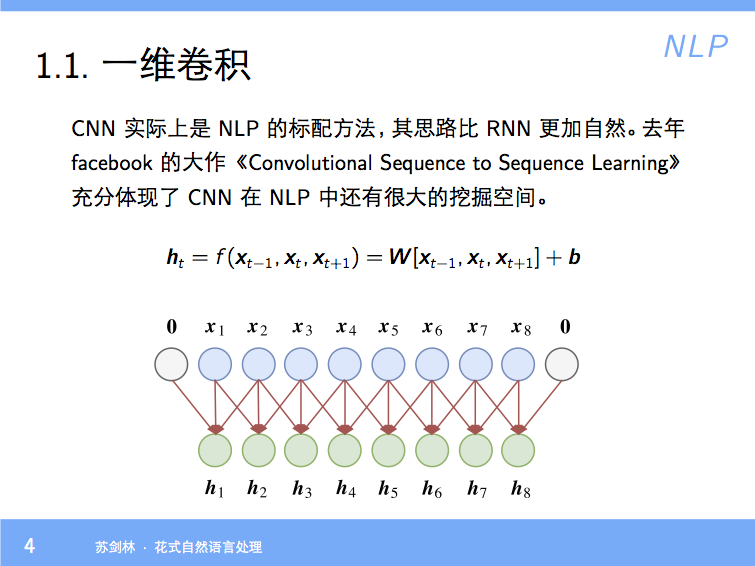
30
Jan
【分享】千万级百度知道语料
By 苏剑林 | 2018-01-30 | 81367位读者 | 引用发布
2018年01月30日
数目
共1千万条
格式
[
{
"url": "http://zhidao.baidu.com/question/565618371557484884.html",
"question": "学文员有哪些专科学校",
"tags": [
"学校",
"专科",
"院校信息"
]
},
{
"url": "http://zhidao.baidu.com/question/2079794100345438428.html",
"question": "网赌和澳门赌有区别吗",
"tags": [
"网络",
"澳门",
"赌博"
]
}
]
7
Jun
python简单实现gillespie模拟
By 苏剑林 | 2018-06-07 | 70131位读者 | 引用
7
Jul
从SamplePairing到mixup:神奇的正则项
By 苏剑林 | 2018-07-07 | 78439位读者 | 引用SamplePairing和mixup是两种一脉相承的图像数据扩增手段,它们看起来很不合理,而操作则非常简单,但结果却非常漂亮:在多个图像分类任务中都表明它们能提高最终分类模型的精度。
某些读者会困惑于一个问题:为什么如此不合理的数据扩增手段,能得到如此好的效果?而本文则要表明,它们看起来是一种数据扩增方法,事实上它们是对模型的一种正则化方案。正如周星驰的电影《国产凌凌漆》的一句经典台词:
表面上看这是一个吹风机,其实它是一个刮胡刀。
数据扩增
让我们从数据扩增说起。数据扩增是指我们在对原始数据做一些简单的变换后,它们对应的类别往往不会变化,所以我们可以在原来数据的基础上,“造”出更多的数据来。比如一幅小狗的照片,将它水平翻转、轻微的旋转、裁剪、平移等操作后,我们认为它的类别没有变化,它还是原来的那只狗。这样一来,从一个样本我们可以衍生出好几个样本,从而增加了训练样本量。

狗

旋转的狗
15
Nov


最近评论