






20
Mar
[欧拉数学]伯努利级数及相关级数的总结
By 苏剑林 | 2016-03-20 | 95122位读者 | 引用最近在算路径积分的时候,频繁地遇到了以下两种无穷级数:
$$\sum_n \frac{1}{n^2\pm\omega^2}\quad \text{和} \quad \prod_n \left(1\pm\frac{\omega^2}{n^2}\right)$$
当然,直接用Mathematica可以很干脆地算出结果来,但是我还是想知道为什么,至少大概地知道。
伯努利级数
当$\omega=0$的时候,第一个级数变为著名的伯努利级数
$$\sum_n \frac{1}{n^2}=1+\frac{1}{4}+\frac{1}{9}+\frac{1}{16}+\dots$$
既然跟伯努利级数有关,那么很自然想到,从伯努利级数的求和入手。
9
Apr
一个非线性差分方程的隐函数解
By 苏剑林 | 2016-04-09 | 41313位读者 | 引用问题来源
笔者经常学习的数学研发论坛曾有一帖讨论下述非线性差分方程的渐近求解:
$$a_{n+1}=a_n+\frac{1}{a_n^2},\, a_1=1$$
原帖子在这里,从这帖子中我获益良多,学习到了很多新技巧。主要思路是通过将两边立方,然后设$x_n=a_n^3$,变为等价的递推问题:
$$x_{n+1}=x_n+3+\frac{3}{x_n}+\frac{1}{x_n^2},\,x_1=1$$
然后可以通过巧妙的技巧得到渐近展开式:
$$x_n = 3n+\ln n+a+\frac{\frac{1}{3}(\ln n+a)-\frac{5}{18}}{n}+\dots$$
具体过程就不提了,读者可以自行到上述帖子学习。
然而,这种形式的解虽然精妙,但存在一些笔者不是很满意的地方:
1、解是渐近的级数,这就意味着实际上收敛半径为0;
2、是$n^{-k}$形式的解,对于较小的$n$难以计算,这都使得高精度计算变得比较困难;
3、当然,题目本来的目的是渐近计算,但是渐近分析似乎又没有必要展开那么多项;
4、里边带有了一个本来就比较难计算的极限值$a$;
5、求解过程似乎稍欠直观。
当然,上面这些缺点,有些是鸡蛋里挑骨头的。不过,也正是这些缺点,促使我寻找更好的形式的解,最终导致了这篇文章。
18
May
调侃:万有引力与爱因斯坦的理论
By 苏剑林 | 2016-05-18 | 48609位读者 | 引用我不是研究引力的,也没有很好地学习过引力。在理论物理方面,我学习经典力学和量子力学比学习广义相对论要多得多。因此,本来我是不应该谈引力的,以免误人子弟。不过,在一次坐车的途中,司机的刹车和加速让我联想到了一些跟引力有关的东西,自我感觉比较有趣,所以发给大家分享一下,也请大家指正。
等效原理

坐汽车
引力,准确来说应该是“万有引力”。所谓“万有”,有两个含义:1、所有物体都能够产生引力;2、所有物体都被引力影响。一个力居然是“万有”的,这让爱因斯坦感觉到非常奇怪,这也是四种基本力之中,引力跟其他力区别最明显的地方。相比之下,电磁相互作用力就只能存在于有“电”的地方,弱相互作用只存在于费米子,等等。
除了引力之外,我们平时还遇到过什么“万有”的力吗?貌似没有。但是我们想象一下,当你坐在一辆长途大巴匀速前进时,突然司机来了一个急刹车,在刹车的那一瞬间,所有人都往前倾了,不仅如此,可能你的行李箱、你的随身物品都往前移的,事实上,车上所有东西都受到了一个往前的力!对于那辆车上的人和物来说,刹车的那一瞬间,就存在着一个“万有”的力!
15
Apr
斯特灵(stirling)公式与渐近级数
By 苏剑林 | 2016-04-15 | 59478位读者 | 引用斯特灵近似,或者称斯特灵公式,最开始是作为阶乘的近似提出
$$n!\sim \sqrt{2\pi n}\left(\frac{n}{e}\right)^n$$
符号$\sim$意味着
$$\lim_{n\to\infty}\frac{\sqrt{2\pi n}\left(\frac{n}{e}\right)^n}{n!}=1$$
将斯特灵公式进一步提高精度,就得到所谓的斯特灵级数
$$n!=\sqrt{2\pi n}\left(\frac{n}{e}\right)^n\left(1+\frac{1}{12n}+\frac{1}{288n^2}\dots\right)$$
很遗憾,这个是渐近级数。
相关资料有:
https://zh.wikipedia.org/zh-cn/斯特灵公式
https://en.wikipedia.org/wiki/Stirling%27s_approximation
本文将会谈到斯特灵公式及其渐近级数的一个改进的推导,并解释渐近级数为什么渐近。
15
May
Coming Back...
By 苏剑林 | 2016-05-15 | 38192位读者 | 引用上一篇博文的发布时间是4月15日,到今天刚好一个月没更新了,但是科学空间的访问量还在。感谢大家对本空间的支持,BoJone对久未更新表示非常抱歉。在恢复更新之前,请允许笔者记记流水账。
在“消失”的一个月中,笔者主要的事情是毕业论文和数据挖掘竞赛。首先毕业论文方面,论文于4月22日交稿,4月29日答辩,答辩完后就意味着毕业论文的事情结束了。我的毕业论文主要写了路径积分在描述随机游走、偏微分方程、随机微分方程的应用。既然是本科论文,就不能说得太晦涩,因此论文整体来看还是比较易读的,可以作为路径积分的入门教程。后面我会略加修改,分开几部分发布在科学空间中的,到时请大家批评指正。
说到路径积分,不得不说到做《量子力学与路径积分》的习题解答这件事情了。很遗憾,这一个多月来,基本没有时间做习题。不过后面我会继续做下去的,已发布的版本,也请有兴趣的读者指出问题。记得年初的时候,朋友问我今年的愿望是什么,我随意地回答了“希望做完一本书的习题”,这本书,当然就是《量子力学与路径积分》了,我相信今年应该能够完成的。
17
Jun
OCR技术浅探:1. 全文简述
By 苏剑林 | 2016-06-17 | 43705位读者 | 引用写在前面:前面的博文已经提过,在上个月我参加了第四届泰迪杯数据挖掘竞赛,做的是A题,跟OCR系统有些联系,还承诺过会把最终的结果开源。最近忙于毕业、搬东西,一直没空整理这些内容,现在抽空整理一下。
把结果发出来,并不是因为结果有多厉害、多先进(相反,当我对比了百度的这篇论文《基于深度学习的图像识别进展:百度的若干实践》之后,才发现论文的内容本质上还是传统那一套,远远还跟不上时代的潮流),而是因为虽然OCR技术可以说比较成熟了,但网络上根本就没有对OCR系统进行较为详细讲解的文章,而本文就权当补充这部分内容吧。我一直认为,技术应该要开源才能得到发展(当然,在中国这一点也确实值得商榷,因为开源很容易造成山寨),不管是数学物理研究还是数据挖掘,我大多数都会发表到博客中,与大家交流。
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 55592位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
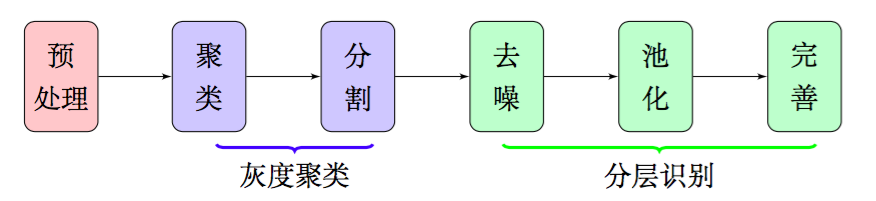
图2:特征提取大概流程
24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 40319位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
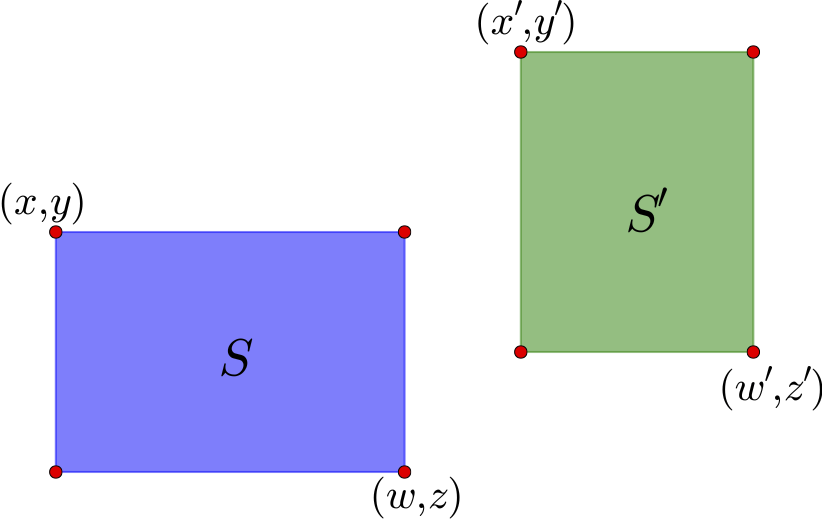
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域

最近评论