






2
Jun
路径积分系列:3.路径积分
By 苏剑林 | 2016-06-02 | 75462位读者 | 引用路径积分是量子力学的一种描述方法,源于物理学家费曼[5],它是一种泛函积分,它已经成为现代量子理论的主流形式. 近年来,研究人员对它的兴趣愈发增加,尤其是它在量子领域以外的应用,出现了一些著作,如[7]. 但在国内了解路径积分的人并不多,很多量子物理专业的学生可能并没有听说过路径积分.
从数学角度来看,路径积分是求偏微分方程的Green函数的一种方法. 我们知道,在偏微分方程的研究中,如果能够求出对应的Green函数,那么对偏微分方程的研究会大有帮助,而通常情况下Green函数并不容易求解. 但构建路径积分只需要无穷小时刻的Green函数,因此形式和概念上都相当简单.
本章并没有新的内容,只是做了一个尝试:从随机游走问题出发,给出路径积分的一个简明而直接的介绍,展示了如何将抛物型的偏微分方程问题转化为路径积分形式.
从点的概率到路径的概率
在上一章对随机游走的研究中,我们得出从$x_0$出发,$t$时间后,走到$x_n$处的概率密度为
$$\frac{1}{\sqrt{2\pi \alpha T}}\exp\left(-\frac{(x_n-x_0)^2}{2\alpha t}\right).\tag{22}$$
这是某时刻某点到另一个时刻另一点的概率,在数学上,我们称之为扩散方程$(21)$的传播子,或者Green函数.
9
Jun
路径积分系列:4.随机微分方程
By 苏剑林 | 2016-06-09 | 29762位读者 | 引用本章将路径积分用于随机微分方程,并且得到了与不对称随机游走一样的结果,从而证明了它与该模型的等价性.
将路径积分用于随机微分方程的研究,这一思路由来已久. 费曼在他的著作[5]中,已经建立了路径积分与线性随机微分方程的关系. 而对于非线性的情况,也有不少研究,但比较混乱,如文献[8]甚至给出了错误的结果.
本文从路径积分的离散化概念出发,明确地建立了两个路径积分微元的雅可比行列式关系,从而对非线性随机微分方程也建立了路径积分. 本文的结果跟文献[9]的结果是一致的.
概念
本文所研究的仅仅是随机常微分方程,它与一般的常微分方程的区别在于布朗运动项的引入,如常见的一类随机微分方程为
$$dx(t)=p(x(t),t)dt + \sqrt{\alpha} dW_t.\tag{48}$$
其中$W_t$代表着一个标准的布朗运动. 由于引入了随机项,所以解$x(t)$不再是确定的,而是有一定的概率分布.
在对随机微分方程中,感兴趣的量有很多,比如关于$x$的某个量的期望、方差,或者稳定性,等等. 随机微分方程领域中有各种分析的技巧,但是显然,直接求出$x(t)$的概率分布后对概率分布进行研究,是最理想最容易的方案. 路径积分正是给出了求概率分布的一个方法.
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 101112位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
27
Jul
今天升级了Blog(欢迎大家来“顶”!)
By 苏剑林 | 2009-07-27 | 64626位读者 | 引用
19
Jan
宇宙驿站服务器升级完毕
By 苏剑林 | 2014-01-19 | 31721位读者 | 引用
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 89700位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 117038位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
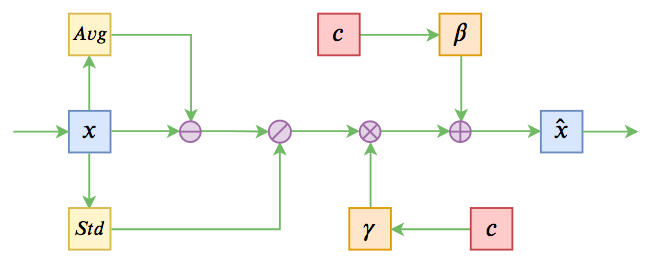
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 196056位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
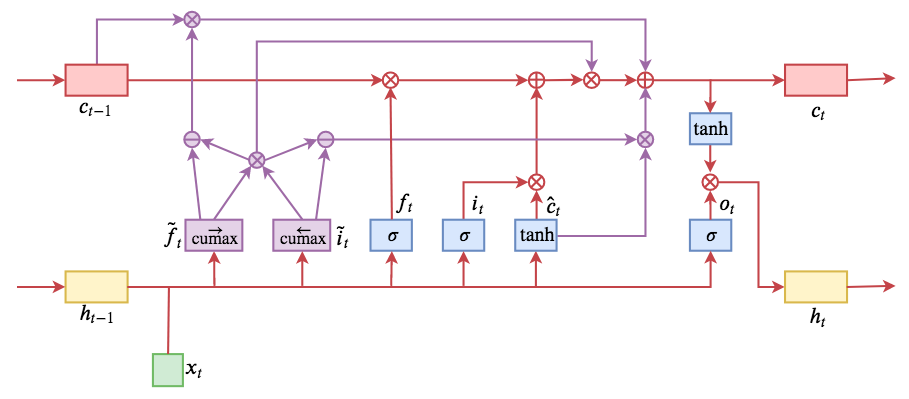
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~

最近评论