






12
Jan
Self-Orthogonality Module:一个即插即用的核正交化模块
By 苏剑林 | 2020-01-12 | 55056位读者 | 引用前些天刷Arxiv看到新文章《Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters》(下面简称“原论文”),看上去似乎有点意思,于是阅读了一番,读完确实有些收获,在此记录分享一下。
给全连接或者卷积模型的核加上带有正交化倾向的正则项,是不少模型的需求,比如大名鼎鼎的BigGAN就加入了类似的正则项。而这篇论文则引入了一个新的正则项,笔者认为整个分析过程颇为有趣,可以一读。
为什么希望正交?
在开始之前,我们先约定:本文所出现的所有一维向量都代表列向量。那么,现在假设有一个$d$维的输入样本$\boldsymbol{x}\in \mathbb{R}^d$,经过全连接或卷积层时,其核心运算就是:
\begin{equation}\boldsymbol{y}^{\top}=\boldsymbol{x}^{\top}\boldsymbol{W},\quad \boldsymbol{W}\triangleq (\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k)\label{eq:k}\end{equation}
其中$\boldsymbol{W}\in \mathbb{R}^{d\times k}$是一个矩阵,它就被称“核”(全连接核/卷积核),而$\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k\in \mathbb{R}^{d}$是该矩阵的各个列向量。
25
Nov
6个派生优化器的简单介绍及其实现
By 苏剑林 | 2019-11-25 | 52717位读者 | 引用优化器可能是深度学习最“玄学”的一个模块之一了:有时候换一个优化器就能带来明显的提升,有时候别人说提升很多的优化器用到自己的任务上却一丁点用都没有,理论性质好的优化器不一定工作得很好,纯粹拍脑袋而来的优化器也未必就差了。但不管怎样,优化器终究也为热爱“深度炼丹”的同学提供了多一个选择。
近几年来,关于优化器的工作似乎也在慢慢增多,很多论文都提出了对常用优化器(尤其是Adam)的大大小小的改进。本文就汇总一些优化器工作或技巧,并统一给出了代码实现,供读者有需调用。
基本形式
所谓“派生”,就是指相关的技巧都是建立在已有的优化器上的,任意一个已有的优化器都可以用上这些技巧,从而变成一个新的优化器。
已有的优化器的基本形式为:
\begin{equation}\begin{aligned}\boldsymbol{g}_t =&\, \nabla_{\boldsymbol{\theta}} L\\
\boldsymbol{h}_t =&\, f(\boldsymbol{g}_{\leq t})\\
\boldsymbol{\theta}_{t+1} =&\, \boldsymbol{\theta}_t - \gamma \boldsymbol{h}_t
\end{aligned}\end{equation}
其中$\boldsymbol{g}_t$即梯度,而$\boldsymbol{g}_{\leq t}$指的是截止到当前步的所有梯度信息,它们经过某种运算$f$(比如累积动量、累积二阶矩校正学习率等)后得到$\boldsymbol{h}_t$,然后由$\boldsymbol{h}_t$来更新参数,这里的$\gamma$就是指学习率。
11
Oct
BN究竟起了什么作用?一个闭门造车的分析
By 苏剑林 | 2019-10-11 | 120360位读者 | 引用BN,也就是Batch Normalization,是当前深度学习模型(尤其是视觉相关模型)的一个相当重要的技巧,它能加速训练,甚至有一定的抗过拟合作用,还允许我们用更大的学习率,总的来说颇多好处(前提是你跑得起较大的batch size)。
那BN究竟是怎么起作用呢?早期的解释主要是基于概率分布的,大概意思是将每一层的输入分布都归一化到$\mathcal{N}(0,1)$上,减少了所谓的Internal Covariate Shift,从而稳定乃至加速了训练。这种解释看上去没什么毛病,但细思之下其实有问题的:不管哪一层的输入都不可能严格满足正态分布,从而单纯地将均值方差标准化无法实现标准分布$\mathcal{N}(0,1)$;其次,就算能做到$\mathcal{N}(0,1)$,这种诠释也无法进一步解释其他归一化手段(如Instance Normalization、Layer Normalization)起作用的原因。
在去年的论文《How Does Batch Normalization Help Optimization?》里边,作者明确地提出了上述质疑,否定了原来的一些观点,并提出了自己关于BN的新理解:他们认为BN主要作用是使得整个损失函数的landscape更为平滑,从而使得我们可以更平稳地进行训练。
本博文主要也是分享这篇论文的结论,但论述方法是笔者“闭门造车”地构思的。窃认为原论文的论述过于晦涩了,尤其是数学部分太不好理解,所以本文试图尽可能直观地表达同样观点。
(注:阅读本文之前,请确保你已经清楚知道BN是什么,本文不再重复介绍BN的概念和流程。)
1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 98702位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
10
Jun
无监督分词和句法分析!原来BERT还可以这样用
By 苏剑林 | 2020-06-10 | 85894位读者 | 引用BERT的一般用法就是加载其预训练权重,再接一小部分新层,然后在下游任务上进行finetune,换句话说一般的用法都是有监督训练的。基于这个流程,我们可以做中文的分词、NER甚至句法分析,这些想必大家就算没做过也会有所听闻。但如果说直接从预训练的BERT(不finetune)就可以对句子进行分词,甚至析出其句法结构出来,那应该会让人感觉到意外和有趣了。
本文介绍ACL 2020的论文《Perturbed Masking: Parameter-free Probing for Analyzing and Interpreting BERT》,里边提供了直接利用Masked Language Model(MLM)来分析和解释BERT的思路,而利用这种思路,我们可以无监督地做到分词甚至句法分析。
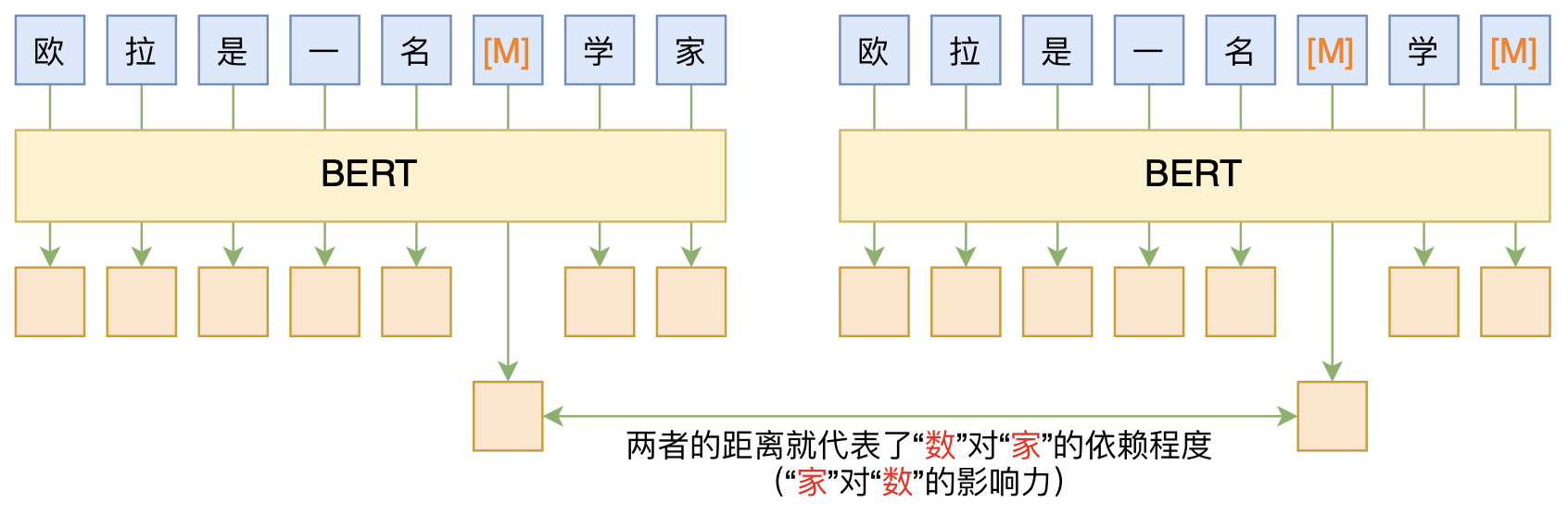
基于BERT的“token-token”相关度计算图示
16
Jun
如何应对Seq2Seq中的“根本停不下来”问题?
By 苏剑林 | 2020-06-16 | 64866位读者 | 引用在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现<eos>标记为止,这就是所谓的“自回归”生成模型。然而,研究过Seq2Seq的读者应该都能发现,这种自回归的解码偶尔会出现“根本停不下来”的现象,主要是某个片段反复出现,比如“今天天气不错不错不错不错不错...”、“你觉得我说得对不对不对不对不对不对...”等等,但就是死活不出现<eos>标记。ICML 2020的文章《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策,本文来简单介绍一下论文的主要内容。
解码算法
对于自回归模型来说,我们建立的是如下的条件语言模型
\begin{equation}p(y_t|y_{\lt t}, x)\label{eq:p}\end{equation}
那么解码算法就是在已知上述模型时,给定$x$来输出对应的$y=(y_1,y_2,\dots,y_T)$来。解码算法大致可以分为两类:确定性解码算法和随机性解码算法,原论文分别针对这两类解码讨论来讨论了“根本停不下来”问题,所以我们需要来了解一下这两类解码算法。
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 93593位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 116488位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
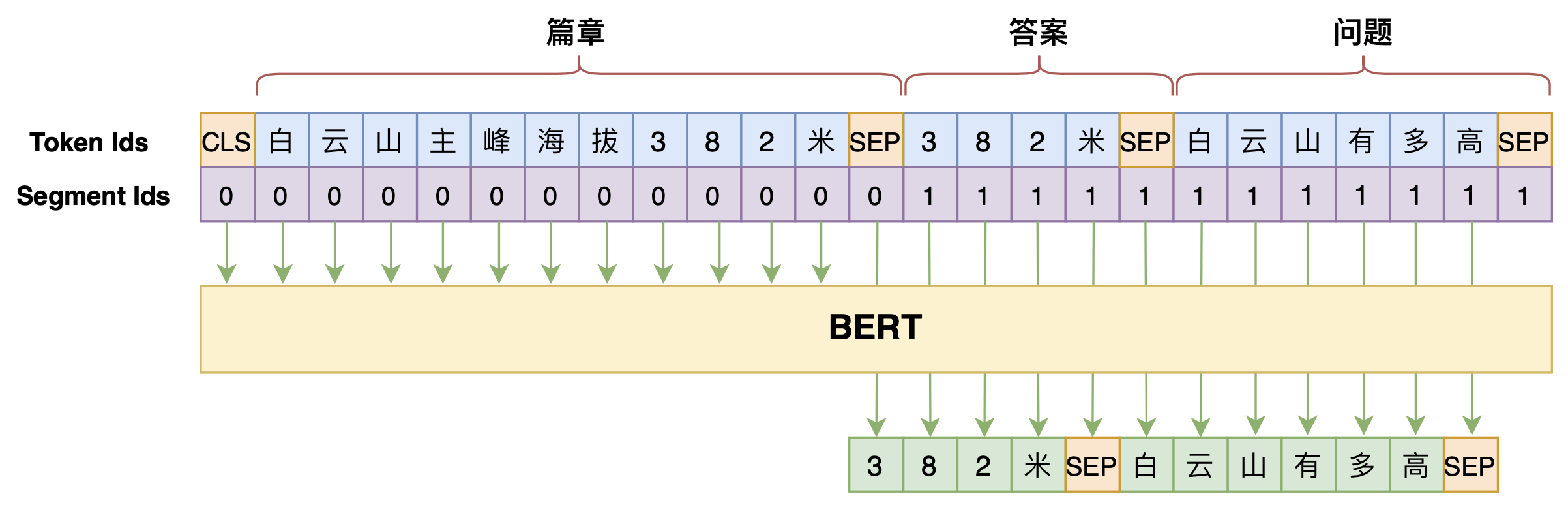
本文的问答生成模型示意图

最近评论