






24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 61689位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 74129位读者 | 引用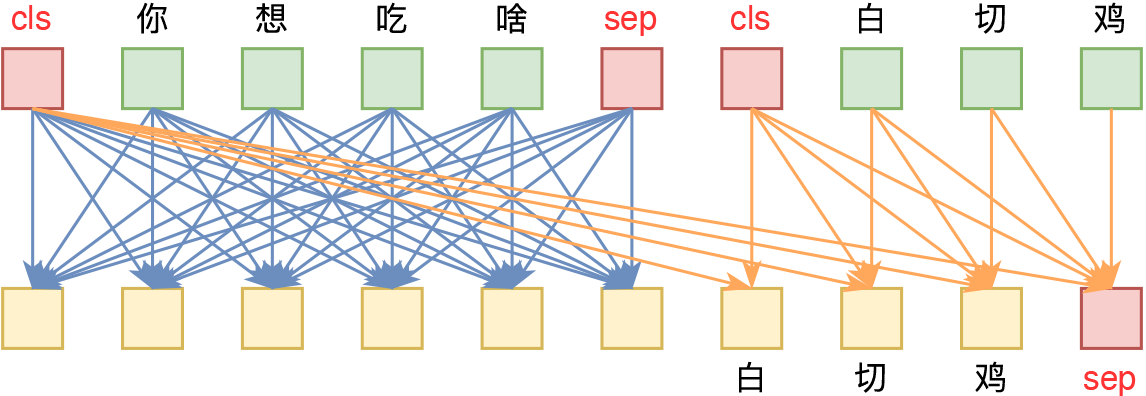
19
Jul
用开源的人工标注数据来增强RoFormer-Sim
By 苏剑林 | 2021-07-19 | 141646位读者 | 引用大家知道,从SimBERT到SimBERTv2(RoFormer-Sim),我们算是为中文文本相似度任务建立了一个还算不错的基准模型。然而,SimBERT和RoFormer-Sim本质上都只是“弱监督”模型,跟“无监督”类似,我们不能指望纯弱监督的模型能达到完美符合人的认知效果。所以,为了进一步提升RoFormer-Sim的效果,我们尝试了使用开源的一些标注数据来辅助训练。本文就来介绍我们的探索过程。
有的读者可能想:有监督有啥好讲的?不就是直接训练么?说是这么说,但其实并没有那么“显然易得”,还是有些“雷区”的,所以本文也算是一份简单的“扫雷指南”吧。
前情回顾
笔者发现,自从SimBERT发布后,读者问得最多的问题大概是:
为什么“我喜欢北京”跟“我不喜欢北京”相似度这么高?它们不是意思相反吗?
22
Jul
概率视角下的线性模型:逻辑回归有解析解吗?
By 苏剑林 | 2021-07-22 | 78679位读者 | 引用我们知道,线性回归是比较简单的问题,它存在解析解,而它的变体逻辑回归(Logistic Regression)却没有解析解,这不能不说是一个遗憾。因为逻辑回归虽然也叫“回归”,但它实际上是用于分类问题的,而对于很多读者来说分类比回归更加常见。准确来说,我们说逻辑回归没有解析解,说的是“最大似然估计下逻辑回归没有解析解”。那么,这是否意味着,如果我们不用最大似然估计,是否能找到一个可用的解析解呢?
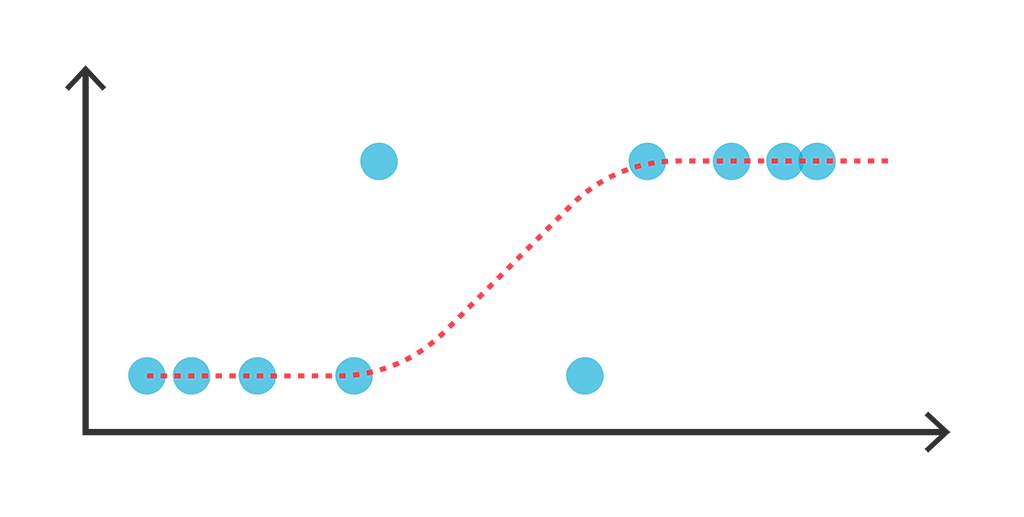
逻辑回归示意图
本文将会从非最大似然的角度,推导逻辑回归的一个解析解,简单的实验表明它效果不逊色于梯度下降求出来的最大似然解。此外,这个解析解还易于推广到单层Softmax多分类模型。
26
Jul
FlatNCE:小批次对比学习效果差的原因竟是浮点误差?
By 苏剑林 | 2021-07-26 | 46622位读者 | 引用自SimCLR在视觉无监督学习大放异彩以来,对比学习逐渐在CV乃至NLP中流行了起来,相关研究和工作越来越多。标准的对比学习的一个广为人知的缺点是需要比较大的batch_size(SimCLR在batch_size=4096时效果最佳),小batch_size的时候效果会明显降低,为此,后续工作的改进方向之一就是降低对大batch_size的依赖。那么,一个很自然的问题是:标准的对比学习在小batch_size时效果差的原因究竟是什么呢?
近日,一篇名为《Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE》对此问题作出了回答:因为浮点误差。看起来真的很让人难以置信,但论文的分析确实颇有道理,并且所提出的改进FlatNCE确实也工作得更好,让人不得不信服。
细微之处
接下来,笔者将按照自己的理解和记号来介绍原论文的主要内容。对比学习(Contrastive Learning)就不帮大家详细复习了,大体上来说,对于某个样本$x$,我们需要构建$K$个配对样本$y_1,y_2,\cdots,y_K$,其中$y_t$是正样本而其余都是负样本,然后分别给每个样本对$(x, y_i)$打分,分别记为$s_1,s_2,\cdots,s_K$,对比学习希望拉大正负样本对的得分差,通常直接用交叉熵作为损失:
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_i e^{s_i}} = \log \left(\sum_i e^{s_i}\right) - s_t = \log \left(1 + \sum_{i\neq t} e^{s_i - s_t}\right)\end{equation}
17
Aug
浅谈Transformer的初始化、参数化与标准化
By 苏剑林 | 2021-08-17 | 175297位读者 | 引用前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候$\boldsymbol{Q}\boldsymbol{K}^{\top}$之后忘记除以$\sqrt{d}$了,于是重新温习了一下为什么除以$\sqrt{d}$如此重要的原因。当然,Google的T5确实是没有除以$\sqrt{d}$的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。
藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。
采样分布
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。
8
Nov
模型优化漫谈:BERT的初始标准差为什么是0.02?
By 苏剑林 | 2021-11-08 | 91553位读者 | 引用前几天在群里大家讨论到了“Transformer如何解决梯度消失”这个问题,答案有提到残差的,也有提到LN(Layer Norm)的。这些是否都是正确答案呢?事实上这是一个非常有趣而综合的问题,它其实关联到挺多模型细节,比如“BERT为什么要warmup?”、“BERT的初始化标准差为什么是0.02?”、“BERT做MLM预测之前为什么还要多加一层Dense?”,等等。本文就来集中讨论一下这些问题。
梯度消失说的是什么意思?
在文章《也来谈谈RNN的梯度消失/爆炸问题》中,我们曾讨论过RNN的梯度消失问题。事实上,一般模型的梯度消失现象也是类似,它指的是(主要是在模型的初始阶段)越靠近输入的层梯度越小,趋于零甚至等于零,而我们主要用的是基于梯度的优化器,所以梯度消失意味着我们没有很好的信号去调整优化前面的层。
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 66563位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。

最近评论