






1
Feb
【NASA每日一图】牧羊卫星Prometheus
By 苏剑林 | 2010-02-01 | 33973位读者 | 引用
6
Aug
五种零食揭示宇宙的形状
By 苏剑林 | 2009-08-06 | 20929位读者 | 引用
26
Oct
新词发现的信息熵方法与实现
By 苏剑林 | 2015-10-26 | 110687位读者 | 引用在本博客的前面文章中,已经简单提到过中文文本处理与挖掘的问题了,中文数据挖掘与英语同类问题中最大的差别是,中文没有空格,如果要较好地完成语言任务,首先得分词。目前流行的分词方法都是基于词库的,然而重要的问题就来了:词库哪里来?人工可以把一些常用的词语收集到词库中,然而这却应付不了层出不穷的新词,尤其是网络新词等——而这往往是语言任务的关键地方。因此,中文语言处理很核心的一个任务就是完善新词发现算法。
新词发现说的就是不加入任何先验素材,直接从大规模的语料库中,自动发现可能成词的语言片段。前两天我去小虾的公司膜拜,并且试着加入了他们的一个开发项目中,主要任务就是网络文章处理。因此,补习了一下新词发现的算法知识,参考了Matrix67.com的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》,尤其是里边的信息熵思想,并且根据他的思路,用Python写了个简单的脚本。
24
Oct
太阳帆技术的粗浅分析
By 苏剑林 | 2010-10-24 | 37562位读者 | 引用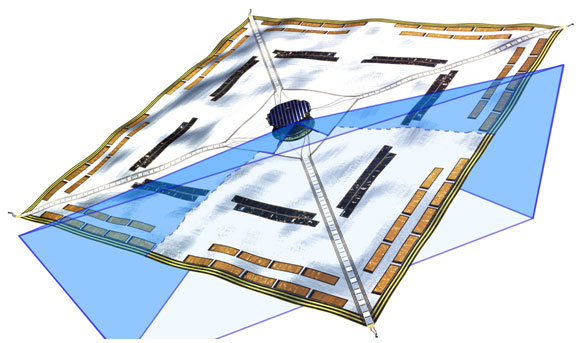
高斯说过“数学是科学的皇后,而算术则是数学的女王。”这里的“算术”,其实就是我们现在所说的数论。从很小的时候开始,我便对数论情有独钟。虽然后来接触了很多更为有趣的数学分支,但是对数学的热情依然不减。我想,这大概是因为小时候的情结吧。小学时候,小小年纪的我,刚刚学完素数、合数、约数、整除等等概念,对数字尤其有兴趣。我想,在那时候我唯一能够读懂的数学难题只有数论这一领域吧。比如费马大定理,$x^n+y^n=z^n$,对于n大于2没有正整数解,很容易就知道它在讲什么;再比如,哥德巴赫猜想,每个大于4的偶数都可以分拆成两个奇素数之和,也很简单就弄懂它讲的是什么。所以,小小的我看懂了这些问题后就饶有兴致地摆弄数字啦,也许正因为如此,才让我对数字乃至对数学都有深厚的爱。
哥德巴赫猜想,无疑是数论中的一个璀璨明珠,可是目前来讲,它还是可望不可即的。一个看似如此简单的猜想,却困惑了数学家几百年,至今无人能解。尽管如此,我还是愿意细细地研究它,慢慢地品味它,在“论证”、或者说验算它的时候,欣赏到数学那神秘的美妙。本文主要就是研究给定偶数的“哥德巴赫分拆数”,即通过实际验算得出每个偶数分拆为两个素数之和的不同分拆方式的数目,比如6=3+3,只有一种分拆方式;8=3+5=5+3;有两种分拆方式;10=3+7=5+5=7+3,有三种分拆方式;等等。偶数2n的分拆数记为$G_2 (2n)$。
(这里定义的“分拆数”跟网上以及一般文献中的定义不同,这里把3+5和5+3看成是两种分拆方式,而网上一般的定义是只看成一种。我这里的定义的好处在于分拆方式的数目实际表示了分拆中涉及到的所有素数的个数。)
哥德巴赫猜想很难,这话没错,但是事实上哥德巴赫猜想是一个非常弱的命题。它说“每个大于4的偶数至少可以分拆成两个奇素数之和”,用上面的术语来说,就是每个偶数的“哥德巴赫分拆数”大于或等于1。可是经过实际验算发现,偶数越大,它的哥德巴赫分拆数越大,两者整体上是呈正相关关系的,比如$G_2 (100)=12,G_2 (1000)=56,G_2 (10000)=254$......所以,从强弱程度上来讲,这和“少于n的素数至少有一个”是差不多的(当然,难度有天壤之别)。
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 228120位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
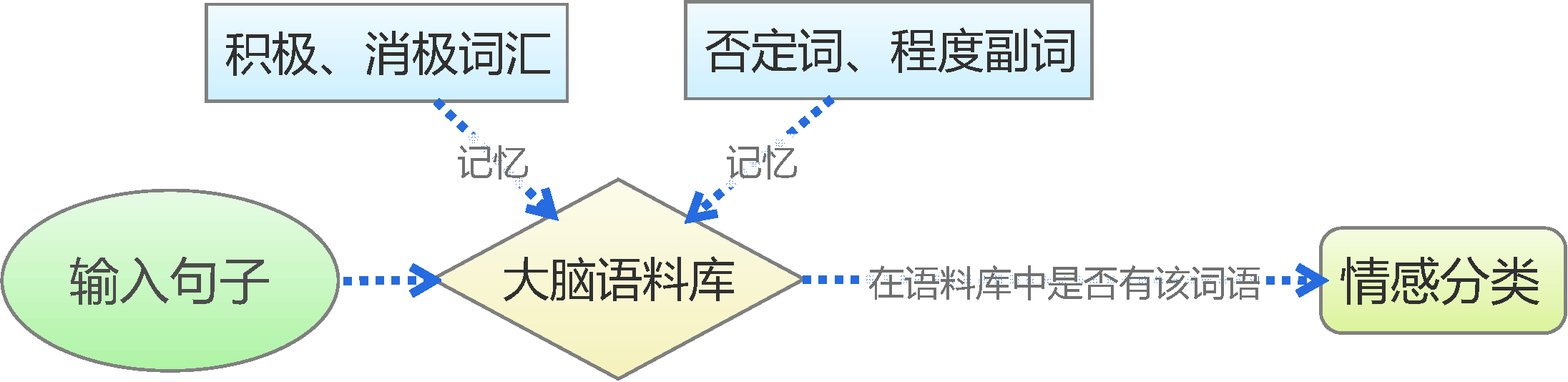
人的最简单的判断思维
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 414565位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
7
Apr
【不可思议的Word2Vec】 3.提取关键词
By 苏剑林 | 2017-04-07 | 200955位读者 | 引用本文主要是给出了关键词的一种新的定义,并且基于Word2Vec给出了一个实现方案。这种关键词的定义是自然的、合理的,Word2Vec只是一个简化版的实现方案,可以基于同样的定义,换用其他的模型来实现。
说到提取关键词,一般会想到TF-IDF和TextRank,大家是否想过,Word2Vec还可以用来提取关键词?而且,用Word2Vec提取关键词,已经初步含有了语义上的理解,而不仅仅是简单的统计了,而且还是无监督的!
什么是关键词?
诚然,TF-IDF和TextRank是两种提取关键词的很经典的算法,它们都有一定的合理性,但问题是,如果从来没看过这两个算法的读者,会感觉简直是异想天开的结果,估计很难能够从零把它们构造出来。也就是说,这两种算法虽然看上去简单,但并不容易想到。试想一下,没有学过信息相关理论的同学,估计怎么也难以理解为什么IDF要取一个对数?为什么不是其他函数?又有多少读者会破天荒地想到,用PageRank的思路,去判断一个词的重要性?
说到底,问题就在于:提取关键词和文本摘要,看上去都是一个很自然的任务,有谁真正思考过,关键词的定义是什么?这里不是要你去查汉语词典,获得一大堆文字的定义,而是问你数学上的定义。关键词在数学上的合理定义应该是什么?或者说,我们获取关键词的目的是什么?

最近评论