






26
Feb
有限Vs无限:无穷电荷板的场|平行板电容
By 苏剑林 | 2011-02-26 | 50500位读者 | 引用
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 204351位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
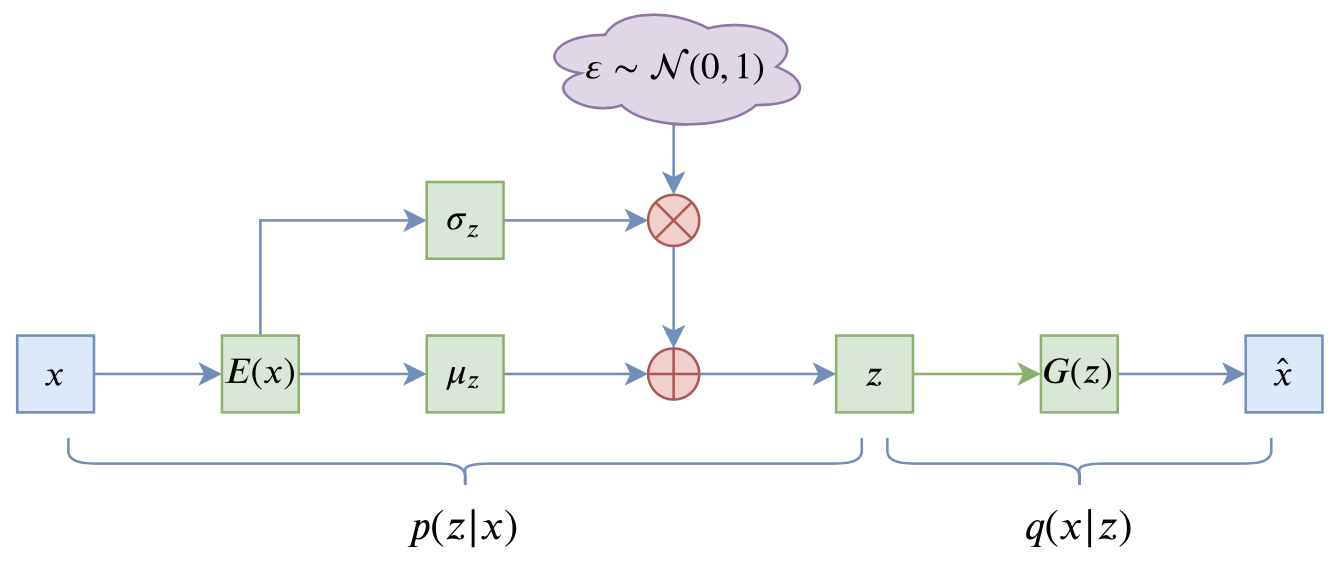
VAE训练流程图示
7
Jan
基于遗忘假设的平滑公式
By 苏剑林 | 2017-01-07 | 21586位读者 | 引用统计是通过大量样本来估计真实分布的过程,通常与统计相伴出现的一个词是“平滑”,即对统计结果打折扣的处理过程。平滑的思想来源于:如果样本空间非常大,那么统计的结果是稀疏的,这样由于各种偶然因素的存在,导致了小的统计结果不可靠,如频数为1的结果可能只是偶然的结果,其频率并不一定近似于$1/N$,频数为0的不一定就不会出现。这样我们就需要对统计结果进行平滑,使得结论更为可靠。
平滑的方法有很多,这里介绍一种基于遗忘假设的平滑公式。假设的任务为:我们要从一批语料中,统计每个字的字频。我们模仿人脑遗忘的过程,假设这个字出现一次,我们脑里的记忆量就增加1,但是如果一个周期内(先不管这个周期多大),这个字都没有出现,那么脑里的记忆量就变为原来的$\beta$比例。假设字是周期性出现的,那么记忆量$A_n$就满足如下递推公式
$$A_{n+1} = \beta A_n + 1$$
14
Oct
训练集、验证集和测试集的意义
By 苏剑林 | 2017-10-14 | 51056位读者 | 引用
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 85528位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 89337位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 84043位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 131199位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。

“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。

最近评论