






13
Jun
“噪声对比估计”杂谈:曲径通幽之妙
By 苏剑林 | 2018-06-13 | 174167位读者 | 引用说到噪声对比估计,或者“负采样”,大家可能立马就想到了Word2Vec。事实上,它的含义远不止于此,噪音对比估计(NCE, Noise Contrastive Estimation)是一个迂回但却异常精美的技巧,它使得我们在没法直接完成归一化因子(也叫配分函数)的计算时,就能够去估算出概率分布的参数。本文就让我们来欣赏一下NCE的曲径通幽般的美妙。
注:由于出发点不同,本文所介绍的“噪声对比估计”实际上更偏向于所谓的“负采样”技巧,但两者本质上是一样的,在此不作区分。
问题起源
问题的根源是难分难舍的指数概率分布~
指数族分布
在很多问题中都会出现指数族分布,即对于某个变量$\boldsymbol{x}$的概率$p(\boldsymbol{x})$,我们将其写成
$$p(\boldsymbol{x}) = \frac{e^{G(\boldsymbol{x})}}{Z}\tag{1}$$
其中$G(\boldsymbol{x})$是$\boldsymbol{x}$的某个“能量”函数,而$Z=\sum_{\boldsymbol{x}} e^{G(\boldsymbol{x})}$则是归一化常数,也叫配分函数。这种分布也称为“玻尔兹曼分布”。
29
Jul
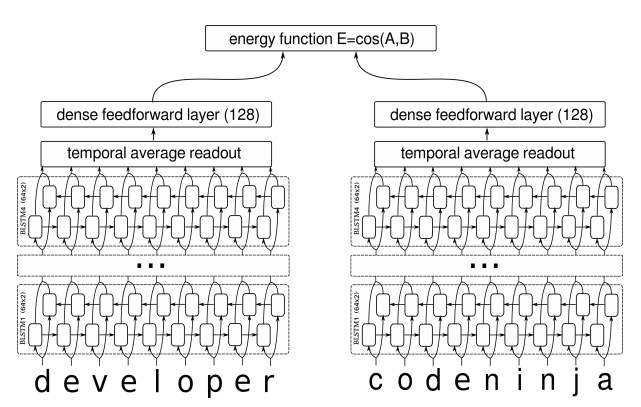
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 331967位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
18
Jul
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
By 苏剑林 | 2018-07-18 | 343985位读者 | 引用前言:我小学开始就喜欢纯数学,后来也喜欢上物理,还学习过一段时间的理论物理,直到本科毕业时,我才慢慢进入机器学习领域。所以,哪怕在机器学习领域中,我的研究习惯还保留着数学和物理的风格:企图从最少的原理出发,理解、推导尽可能多的东西。这篇文章是我这个理念的结果之一,试图以变分推断作为出发点,来统一地理解深度学习中的各种模型,尤其是各种让人眼花缭乱的GAN。本文已经挂到arxiv上,需要读英文原稿的可以移步到《Variational Inference: A Unified Framework of Generative Models and Some Revelations》。
下面是文章的介绍。其实,中文版的信息可能还比英文版要稍微丰富一些,原谅我这蹩脚的英语...
摘要:本文从一种新的视角阐述了变分推断,并证明了EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。其中,论文也表明了标准的GAN的优化目标是不完备的,这可以解释为什么GAN的训练需要谨慎地选择各个超参数。最后,文中给出了一个可以改善这种不完备性的正则项,实验表明该正则项能增强GAN训练的稳定性。
近年来,深度生成模型,尤其是GAN,取得了巨大的成功。现在我们已经可以找到数十个乃至上百个GAN的变种。然而,其中的大部分都是凭着经验改进的,鲜有比较完备的理论指导。
本文的目标是通过变分推断来给这些生成模型建立一个统一的框架。首先,本文先介绍了变分推断的一个新形式,这个新形式其实在博客以前的文章中就已经介绍过,它可以让我们在几行字之内导出变分自编码器(VAE)和EM算法。然后,利用这个新形式,我们能直接导出GAN,并且发现标准GAN的loss实则是不完备的,缺少了一个正则项。如果没有这个正则项,我们就需要谨慎地调整超参数,才能使得模型收敛。
1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 362095位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 272988位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 72941位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。
22
Oct
RSGAN:对抗模型中的“图灵测试”思想
By 苏剑林 | 2018-10-22 | 126210位读者 | 引用这两天无意间发现一个非常有意义的工作,称为“相对GAN”,简称RSGAN,来自文章《The relativistic discriminator: a key element missing from standard GAN》,据说该文章还得到了GAN创始人Goodfellow的点赞。这篇文章提出了用相对的判别器来取代标准GAN原有的判别器,使得生成器的收敛更为迅速,训练更为稳定。
可惜的是,这篇文章仅仅从训练和实验角度对结果进行了论述,并没有进行更深入的分析,以至于不少人觉得这只是GAN训练的一个trick。但是在笔者来看,RSGAN具有更为深刻的含义,甚至可以看成它已经开创了一个新的GAN流派。所以,笔者决定对RSGAN模型及其背后的内涵做一个基本的介绍。不过需要指出的是,除了结果一样之外,本文的介绍过程跟原论文相比几乎没有重合之处。
“图灵测试”思想
SGAN
SGAN就是标准的GAN(Standard GAN)。就算没有做过GAN研究的读者,相信也从各种渠道了解到GAN的大概原理:“造假者”不断地进行造假,试图愚弄“鉴别者”;“鉴别者”不断提高鉴别技术,以分辨出真品和赝品。两者相互竞争,共同进步,直到“鉴别者”无法分辨出真、赝品了,“造假者”就功成身退了。
在建模时,通过交替训练实现这个过程:固定生成器,训练一个判别器(二分类模型),将真实样本输出1,将伪造样本输出0;然后固定判别器,训练生成器让伪造样本尽可能输出1,后面这一步不需要真实样本参与。
问题所在
然而,这个建模过程似乎对判别器的要求过于苛刻了,因为判别器是孤立运作的:训练生成器时,真实样本没有参与,所以判别器必须把关于真实样本的所有属性记住,这样才能指导生成器生成更真实的样本。
20
Nov
不用L约束又不会梯度消失的GAN,了解一下?
By 苏剑林 | 2018-11-20 | 169626位读者 | 引用不知道从什么时候开始,我发现我也掉到了GAN的大坑里边了,唉,争取早日能跳出来...
这篇博客介绍的是我最近提交到arxiv的一个关于GAN的新框架,里边主要介绍了一种对概率散度的新理解,并且基于这种理解推导出了一个新的GAN。整篇文章比较偏理论,对这个GAN的相关性质都做了完整的论证,自认为是一个理论完备的结果。
文章链接:https://papers.cool/arxiv/1811.07296
先摆结论:
1、论文提供了一种分析和构造概率散度的直接思路,从而简化了构建新GAN框架的过程。
2、推导出了一个称为GAN-QP的GAN框架$\eqref{eq:gan-gp-gd}$,这个GAN不需要像WGAN那样的L约束,又不会有SGAN的梯度消失问题,实验表明它至少有不逊色于、甚至优于WGAN的表现。

GAN-QP效果图
论文的实验最大做到了512x512的人脸生成(CelebA HQ),充分表明了模型的有效性(效果不算完美,但是模型特别简单)。有兴趣的朋友,欢迎继续阅读下去。

最近评论