






29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 71506位读者 | 引用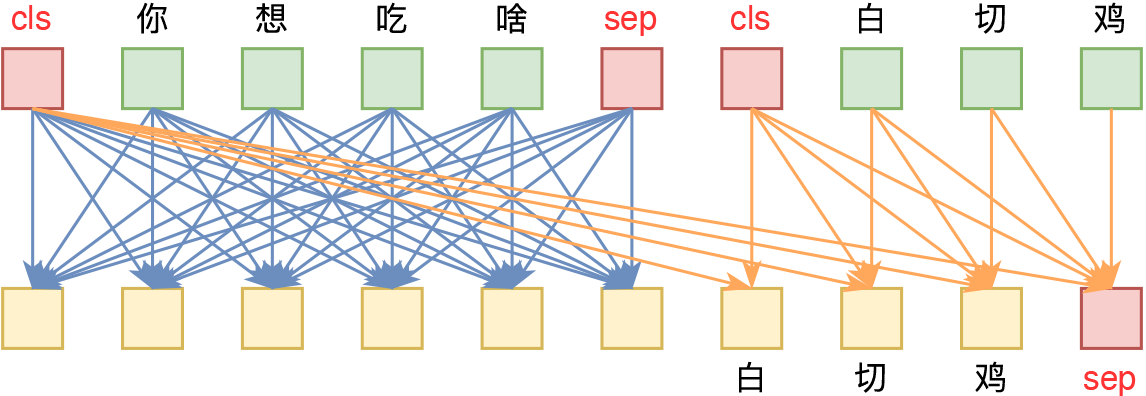
9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 60705位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计$x$的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本$x_1,x_2,\cdots,x_N\sim \tilde{p}(x)$的情况下,用一个待定的概率密度簇$q_{\theta}(x)$去拟合这批样本,拟合的目标一般是最小化负对数似然:
\begin{equation}\mathbb{E}_{x\sim \tilde{p}(x)}[-\log q_{\theta}(x)] = -\frac{1}{N}\sum_{i=1}^N \log q_{\theta}(x_i)\label{eq:mle}\end{equation}
3
Mar
指数梯度下降 + 元学习 = 自适应学习率
By 苏剑林 | 2022-03-03 | 29522位读者 | 引用前两天刷到了Google的一篇论文《Step-size Adaptation Using Exponentiated Gradient Updates》,在其中学到了一些新的概念,所以在此记录分享一下。主要的内容有两个,一是非负优化的指数梯度下降,二是基于元学习思想的学习率调整算法,两者都颇有意思,有兴趣的读者也可以了解一下。
指数梯度下降
梯度下降大家可能听说得多了,指的是对于无约束函数$\mathcal{L}(\boldsymbol{\theta})$的最小化,我们用如下格式进行更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\end{equation}
其中$\eta$是学习率。然而很多任务并非总是无约束的,对于最简单的非负约束,我们可以改为如下格式更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t \odot \exp\left(- \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\right)\label{eq:egd}\end{equation}
这里的$\odot$是逐位对应相乘(Hadamard积)。容易看到,只要初始化的$\boldsymbol{\theta}_0$是非负的,那么在整个更新过程中$\boldsymbol{\theta}_t$都会保持非负,这就是用于非负约束优化的“指数梯度下降”。
10
May
logsumexp运算的几个不等式
By 苏剑林 | 2022-05-10 | 22138位读者 | 引用$\text{logsumexp}$是机器学习经常遇到的运算,尤其是交叉熵的相关实现和推导中都会经常出现,同时它还是$\max$的光滑近似(参考《寻求一个光滑的最大值函数》)。设$x=(x_1,x_2,\cdots,x_n)$,$\text{logsumexp}$定义为
\begin{equation}\text{logsumexp}(x)=\log\sum_{i=1}^n e^{x_i}\end{equation}
本文来介绍$\text{logsumexp}$的几个在理论推导中可能用得到的不等式。
基本界
记$x_{\max} = \max(x_1,x_2,\cdots,x_n)$,那么显然有
\begin{equation}e^{x_{\max}} < \sum_{i=1}^n e^{x_i} \leq \sum_{i=1}^n e^{x_{\max}} = ne^{x_{\max}}\end{equation}
各端取对数即得
\begin{equation}x_{\max} < \text{logsumexp}(x) \leq x_{\max} + \log n\end{equation}
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 133019位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
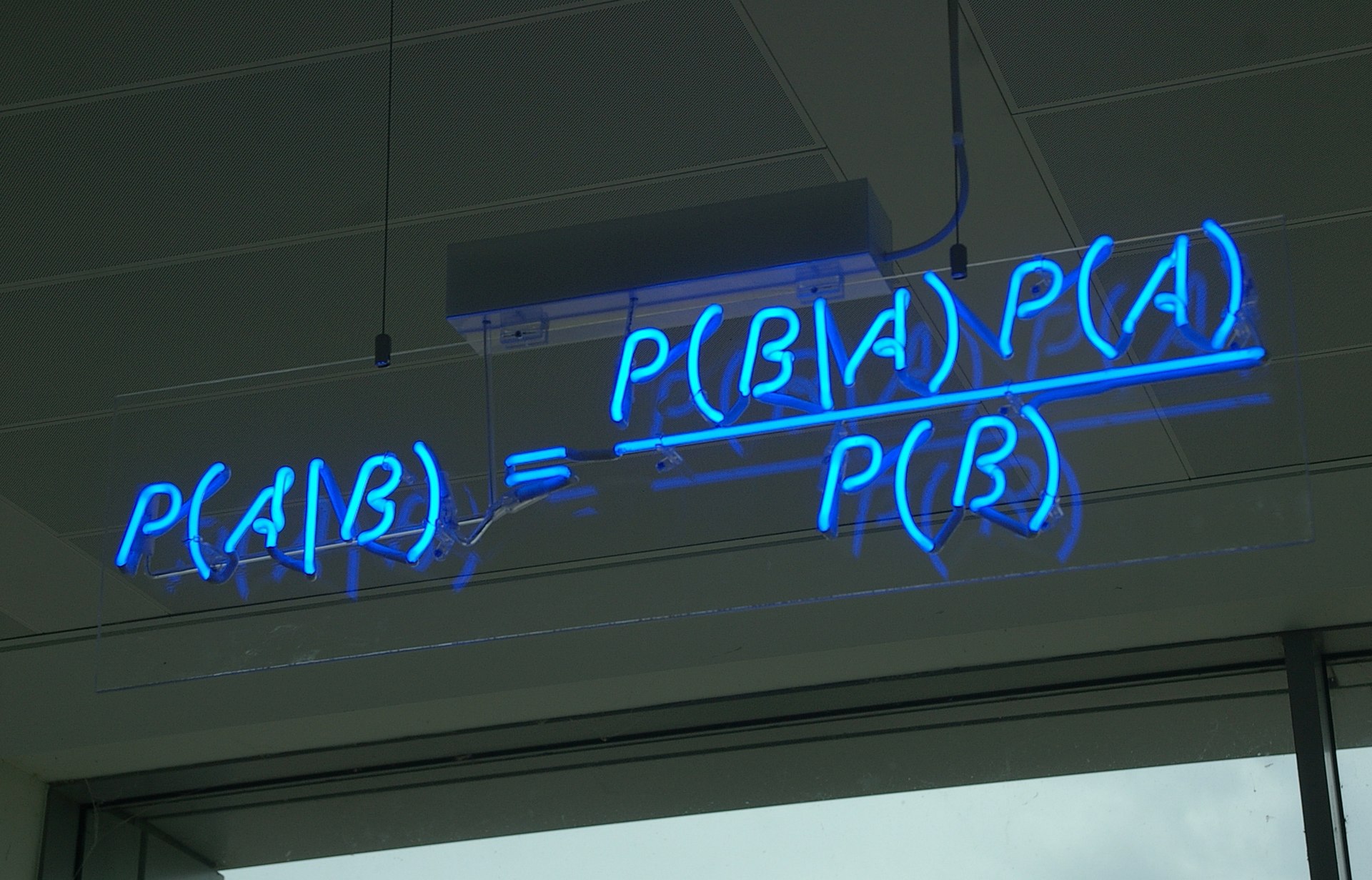
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
5
Dec
智能家居之小爱同学控制极米投影仪的简单方案
By 苏剑林 | 2022-12-05 | 32527位读者 | 引用前段时间买了一个极米投影仪,开始折腾才发现极米跟小米基本没啥关系,它根本无法跟小爱同学互动。在众多名字带“米”的品牌中,极米是为数不多的无法接入米家生态的品牌,想必有不少用户开始都会被极米这个名字误导,关键是极米投影仪还在小米商城上有得卖(捂脸)。
买都买了,还过了七天无理由,退是退不成了,只能试着折腾一下,看看能不能强行互动。
现有方案
首先网上搜了一下,网友给出的参考方案大体上有几种,一种是用“米家智能插座 + 上电自动开机”来控制开关机(事实上主要的联动就是开关机了),一种是接入Home Assistant后通过ADB控制,还有一种是修改遥控器,给遥控器加入红外模块,继而用小爱同学的红外遥控功能。
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 36017位读者 | 引用
11
Feb
测试函数法推导连续性方程和Fokker-Planck方程
By 苏剑林 | 2023-02-11 | 31600位读者 | 引用在文章《生成扩散模型漫谈(六):一般框架之ODE篇》中,我们推导了SDE的Fokker-Planck方程;而在《生成扩散模型漫谈(十二):“硬刚”扩散ODE》中,我们单独推导了ODE的连续性方程。它们都是描述随机变量沿着SDE/ODE演化的分布变化方程,连续性方程是Fokker-Planck方程的特例。在推导Fokker-Planck方程时,我们将泰勒展开硬套到了狄拉克函数上,虽然结果是对的,但未免有点不伦不类;在推导连续性方程时,我们结合了雅可比行列式和泰勒展开,方法本身比较常规,但没法用来推广到Fokker-Planck方程。
这篇文章我们介绍“测试函数法”,它是推导连续性方程和Fokker-Planck方程的标准方法之一,其分析过程比较正规,并且适用场景也比较广。

最近评论