






26
Dec
“非自回归”也不差:基于MLM的阅读理解问答
By 苏剑林 | 2019-12-26 | 81570位读者 | 引用![用MLM做阅读理解的模型图示(其中[M]表示[MASK]标记)](/usr/uploads/2019/12/1024911876.png)
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 48713位读者 | 引用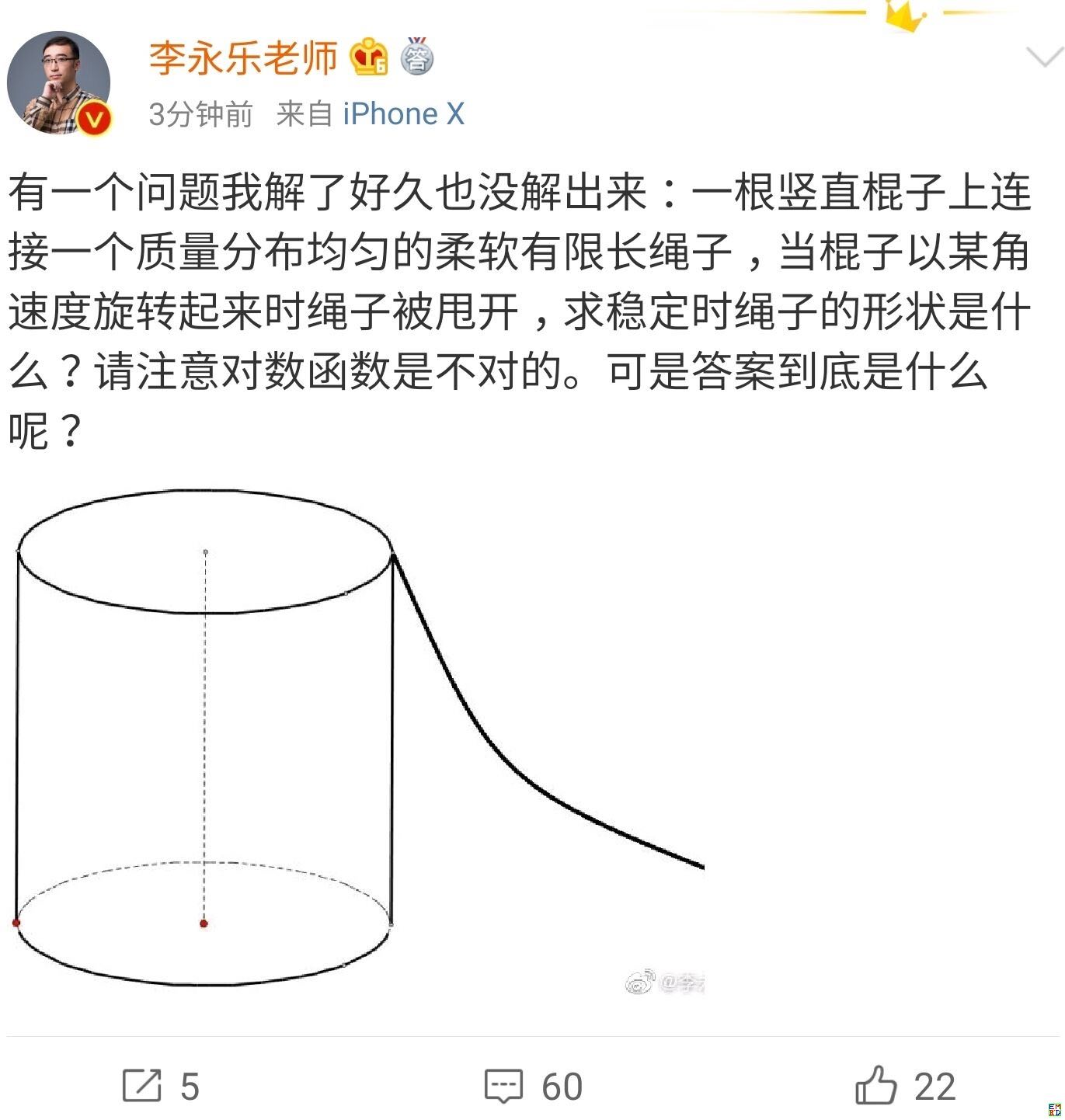
30
Jul
Keras实现两个优化器:Lookahead和LazyOptimizer
By 苏剑林 | 2019-07-30 | 45709位读者 | 引用最近用Keras实现了两个优化器,也算是有点实现技巧,遂放在一起写篇文章简介一下(如果只有一个的话我就不写了)。这两个优化器的名字都挺有意思的,一个是look ahead(往前看?),一个是lazy(偷懒?),难道是两个完全不同的优化思路么?非也非也~只能说发明者们起名字太有创意了。
Lookahead
首先登场的是Lookahead优化器,它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 321313位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
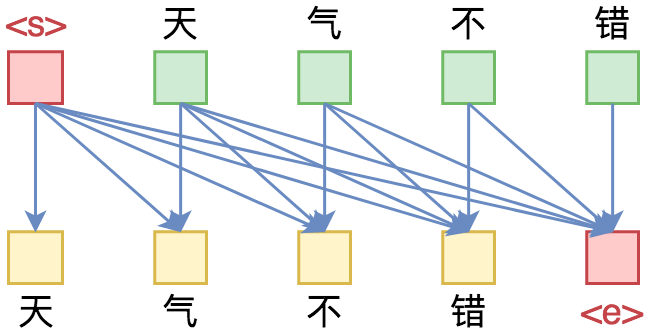
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 92124位读者 | 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 47474位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 329466位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 82979位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为

最近评论