






18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 46100位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以$\mathcal{O}(1)$的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
29
Mar
Transformer升级之路:17、多模态位置编码的简单思考
By 苏剑林 | 2024-03-29 | 62326位读者 | 引用在这个系列的第二篇文章《Transformer升级之路:2、博采众长的旋转式位置编码》中,笔者提出了旋转位置编码(RoPE)——通过绝对位置的形式实现相对位置编码的方案。一开始RoPE是针对一维序列如文本、音频等设计的(RoPE-1D),后来在《Transformer升级之路:4、二维位置的旋转式位置编码》中我们将它推广到了二维序列(RoPE-2D),这适用于图像的ViT。然而,不管是RoPE-1D还是RoPE-2D,它们的共同特点都是单一模态,即纯文本或者纯图像输入场景,那么对于多模态如图文混合输入场景,RoPE该做如何调整呢?
笔者搜了一下,发现鲜有工作讨论这个问题,主流的做法似乎都是直接展平所有输入,然后当作一维输入来应用RoPE-1D,因此连RoPE-2D都很少见。且不说这种做法会不会成为图像分辨率进一步提高时的效果瓶颈,它终究是显得不够优雅。所以,接下来我们试图探寻两者的一个自然结合。
旋转位置
RoPE名称中的“旋转”一词,来源于旋转矩阵$\boldsymbol{\mathcal{R}}_n=\begin{pmatrix}\cos n\theta & -\sin n\theta\\ \sin n\theta & \cos n\theta\end{pmatrix}$,它满足
\begin{equation}\boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n=\boldsymbol{\mathcal{R}}_{n-m}\end{equation}
24
May
重温SSM(一):线性系统和HiPPO矩阵
By 苏剑林 | 2024-05-24 | 46564位读者 | 引用前几天,笔者看了几篇介绍SSM(State Space Model)的文章,才发现原来自己从未认真了解过SSM,于是打算认真去学习一下SSM的相关内容,顺便开了这个新坑,记录一下学习所得。
SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的S4,不算太老,而SSM最新最火的变体大概是去年的Mamba。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样RWKV、RetNet还有此前我们在《Google新作试图“复活”RNN:RNN能否再次辉煌?》介绍过的LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。
尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作《HiPPO: Recurrent Memory with Optimal Polynomial Projections》(简称HiPPO),所以本文从HiPPO开始说起。
29
May
Transformer升级之路:18、RoPE的底数选择原则
By 苏剑林 | 2024-05-29 | 144215位读者 | 引用我们知道,在RoPE中频率的计算公式为$\theta_i = b^{-2i/d}$,底数$b$默认值为10000。目前Long Context的主流做法之一是,先在$b=10000$上用短文本预训练,然后调大$b$并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的$b$再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大$b$完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大$b$了?
上周的论文《Base of RoPE Bounds Context Length》试图回答这个问题,它基于一个期望性质研究了$b$的下界,由此指出更大的训练长度本身就应该选择更大的底数,与训练策略无关。整个分析思路颇有启发性,接下来我们一起来品鉴一番。
20
Jun
重温SSM(三):HiPPO的高效计算(S4)
By 苏剑林 | 2024-06-20 | 28417位读者 | 引用前面我们用两篇文章《重温SSM(一):线性系统和HiPPO矩阵》和《重温SSM(二):HiPPO的一些遗留问题》介绍了HiPPO的思想和推导——通过正交函数基对持续更新的函数进行实时逼近,其拟合系数的动力学正好可以表示为一个线性ODE系统,并且对于特定的基底以及逼近方式,我们可以将线性系统的关键矩阵精确地算出来。此外,我们还讨论了HiPPO的离散化和相关性质等问题,这些内容奠定了后续的SSM工作的理论基础。
接下来,我们将介绍HiPPO的后续应用篇《Efficiently Modeling Long Sequences with Structured State Spaces》(简称S4),它利用HiPPO的推导结果作为序列建模的基本工具,并从新的视角探讨了高效的计算和训练方式,最后在不少长序列建模任务上验证了它的有效性,可谓SSM乃至RNN复兴的代表作之一。
基本框架
S4使用的序列建模框架,是如下的线性ODE系统:
\begin{equation}\begin{aligned}
x'(t) =&\, A x(t) + B u(t) \\
y(t) =&\, C^* x(t) + D u(t)
\end{aligned}\end{equation}
27
Jun
重温SSM(四):有理生成函数的新视角
By 苏剑林 | 2024-06-27 | 17644位读者 | 引用在前三篇文章中,我们较为详细地讨论了HiPPO和S4的大部分数学细节。那么,对于接下来的第四篇文章,大家预期我们会讨论什么工作呢?S5、Mamba乃至Mamba2?都不是。本系列文章主要关心SSM的数学基础,旨在了解SSM的同时也补充自己的数学能力。而在上一篇文章我们简单提过S5和Mamba,S5是S4的简化版,相比S4基本上没有引入新的数学技巧,而Mamba系列虽然表现优异,但它已经将$A$简化为对角矩阵,所用到的数学技巧就更少了,它更多的是体现了工程方面的能力。
这篇文章我们来学习一篇暂时还声名不显的新工作《State-Free Inference of State-Space Models: The Transfer Function Approach》(简称RFT),它提出了一个新方案,将SSM的训练、推理乃至参数化,都彻底转到了生成函数空间中,为SSM的理解和应用开辟了新的视角
基础回顾
首先我们简单回顾一下上一篇文章关于S4的探讨结果。S4基于如下线性RNN
\begin{equation}\begin{aligned}
x_{k+1} =&\, \bar{A} x_k + \bar{B} u_k \\
y_{k+1} =&\, \bar{C}^* x_{k+1} \\
\end{aligned}\label{eq:linear}\end{equation}
12
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(一)
By 苏剑林 | 2024-07-12 | 49199位读者 | 引用众所周知,LoRA是一种常见的参数高效的微调方法,我们在《梯度视角下的LoRA:简介、分析、猜测及推广》做过简单介绍。LoRA利用低秩分解来降低微调参数量,节省微调显存,同时训练好的权重可以合并到原始权重上,推理架构不需要作出改变,是一种训练和推理都比较友好的微调方案。此外,我们在《配置不同的学习率,LoRA还能再涨一点?》还讨论过LoRA的不对称性,指出给$A,B$设置不同的学习率能取得更好的效果,该结论被称为“LoRA+”。
为了进一步提升效果,研究人员还提出了不少其他LoRA变体,如AdaLoRA、rsLoRA、DoRA、PiSSA等,这些改动都有一定道理,但没有特别让人深刻的地方觉。然而,前两天的《LoRA-GA: Low-Rank Adaptation with Gradient Approximation》,却让笔者眼前一亮,仅扫了摘要就有种必然有效的感觉,仔细阅读后更觉得它是至今最精彩的LoRA改进。
究竟怎么个精彩法?LoRA-GA的实际含金量如何?我们一起来学习一下。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 24446位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
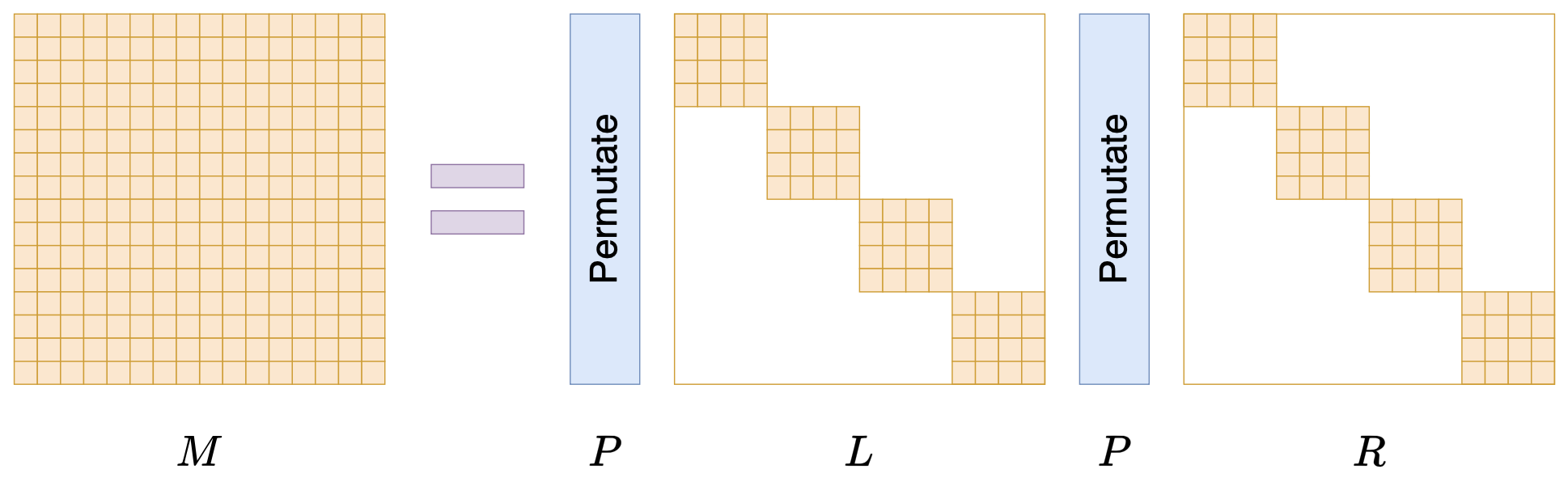
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。

最近评论