






6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 67351位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
25
Dec
从loss的硬截断、软化到focal loss
By 苏剑林 | 2017-12-25 | 190785位读者 | 引用前言
今天在QQ群里的讨论中看到了focal loss,经搜索它是Kaiming大神团队在他们的论文《Focal Loss for Dense Object Detection》提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。本质上讲,focal loss就是一个解决分类问题中类别不平衡、分类难度差异的一个loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:
《如何评价kaiming的Focal Loss for Dense Object Detection?》
看到这个loss,开始感觉很神奇,感觉大有用途。因为在NLP中,也存在大量的类别不平衡的任务。最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好loss。
接着我再仔细对比了一下,我发现这个loss跟我昨晚构思的一个loss具有异曲同工之理!这就促使我写这篇博文了。我将从我自己的思考角度出发,来分析这个问题,最后得到focal loss,也给出我昨晚得到的类似的loss。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 79923位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
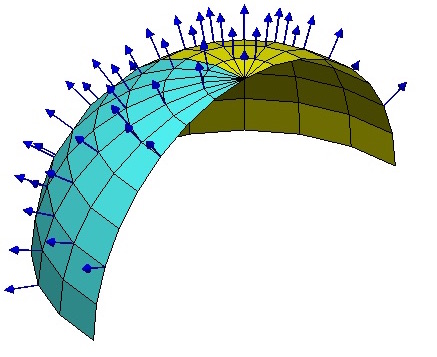
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
30
Mar
文本情感分类(四):更好的损失函数
By 苏剑林 | 2017-03-30 | 121136位读者 | 引用文本情感分类其实就是一个二分类问题,事实上,对于分类模型,都会存在这样一个毛病:优化目标跟考核指标不一致。通常来说,对于分类(包括多分类),我们都会采用交叉熵作为损失函数,它的来源就是最大似然估计(参考《梯度下降和EM算法:系出同源,一脉相承》)。但是,我们最后的评估目标,并非要看交叉熵有多小,而是看模型的准确率。一般来说,交叉熵很小,准确率也会很高,但这个关系并非必然的。
要平均,不一定要拔尖
一个更通俗的例子是:一个数学老师,在努力提高同学们的平均分,但期末考核的指标却是及格率(60分及格)。假如平均分是100分(也就意味着所有同学都考到了100分),那么自然及格率是100%,这是最理想的。但现实不一定这么美好,平均分越高,只要平均分还没有达到100,那么及格率却不一定越高,比如两个人分别考40和90,那么平均分就是65,及格率只有50%;如果两个人的成绩都是60,平均分就是60,及格率却有100%。这也就是说,平均分可以作为一个目标,但这个目标并不直接跟考核目标挂钩。
那么,为了提升最后的考核目标,这个老师应该怎么做呢?很显然,首先看看所有学生中,哪些同学已经及格了,及格的同学先不管他们,而针对不及格的同学进行补课加强,这样一来,原则上来说有很多不及格的同学都能考上60分了,也有可能一些本来及格的同学考不够60分了,但这个过程可以迭代,最终使得大家都在60分以上,当然,最终的平均分不一定很高,但没办法,谁叫考核目标是及格率呢?
27
May
【不可思议的Word2Vec】5. Tensorflow版的Word2Vec
By 苏剑林 | 2017-05-27 | 108562位读者 | 引用本文封装了一个比较完整的Word2Vec,其模型部分使用tensorflow实现。本文的目的并非只是再造一次Word2Vec这个轮子,而是通过这个例子来熟悉tensorflow的写法,并且测试笔者设计的一种新的softmax loss的效果,为后面研究语言模型的工作做准备。
不同的地方
Word2Vec的基本的数学原理,请移步到《【不可思议的Word2Vec】 1.数学原理》一文查看。本文的主要模型还是CBOW或者Skip-Gram,但在loss设计上有所不同。本文还是使用了完整的softmax结构,而不是huffmax softmax或者负采样方案,但是在训练softmax时,使用了基于随机负采样的交叉熵作为loss。这种loss与已有的nce_loss和sampled_softmax_loss都不一样,这里姑且命名为random softmax loss。
另外,在softmax结构中,一般是$\text{softmax}(Wx+b)$这样的形式,考虑到$W$矩阵的形状事实上跟词向量矩阵的形状是一样的,因此本文考虑了softmax层与词向量层共享权重的模型(这时候直接让$b$为0),这种模型等效于原有的Word2Vec的负采样方案,也类似于glove词向量的词共现矩阵分解,但由于使用了交叉熵损失,理论上收敛更快,而且训练结果依然具有softmax的预测概率意义(相比之下,已有的Word2Vec负样本模型训练完之后,最后模型的输出值是没有意义的,只有词向量是有意义的。)。同时,由于共享了参数,因此词向量的更新更为充分,读者不妨多多测试这种方案。
8
Jun
互怼的艺术:从零直达WGAN-GP
By 苏剑林 | 2017-06-08 | 283309位读者 | 引用前言
GAN,全称Generative Adversarial Nets,中文名是生成对抗式网络。对于GAN来说,最通俗的解释就是“伪造者-鉴别者”的解释,如艺术画的伪造者和鉴别者。一开始伪造者和鉴别者的水平都不高,但是鉴别者还是比较容易鉴别出伪造者伪造出来的艺术画。但随着伪造者对伪造技术的学习后,其伪造的艺术画会让鉴别者识别错误;或者随着鉴别者对鉴别技术的学习后,能够很简单的鉴别出伪造者伪造的艺术画。这是一个双方不断学习技术,以达到最高的伪造和鉴别水平的过程。 然而,稍微深入了解的读者就会发现,跟现实中的造假者不同,造假者会与时俱进地使用新材料新技术来造假,而GAN最神奇而又让人困惑的地方是它能够将随机噪声映射为我们所希望的正样本,有噪声就有正样本,这不是无本生意吗,多划算~
另一个情况是,自从WGAN提出以来,基本上GAN的主流研究都已经变成了WGAN上去了,但WGAN的形式事实上已经跟“伪造者-鉴别者”差得比较远了。而且WGAN虽然最后的形式并不复杂,但是推导过程却用到了诸多复杂的数学,使得我无心研读原始论文。这迫使我要找从一条简明直观的线索来理解GAN。幸好,经过一段时间的思考,有点收获。
14
Oct
训练集、验证集和测试集的意义
By 苏剑林 | 2017-10-14 | 49783位读者 | 引用
26
Oct
浅谈神经网络中激活函数的设计
By 苏剑林 | 2017-10-26 | 45854位读者 | 引用激活函数是神经网络中非线性的来源,因为如果去掉这些函数,那么整个网络就只剩下线性运算,线性运算的复合还是线性运算的,最终的效果只相当于单层的线性模型。
那么,常见的激活函数有哪些呢?或者说,激活函数的选择有哪些指导原则呢?是不是任意的非线性函数都可以做激活函数呢?
这里探究的激活函数是中间层的激活函数,而不是输出的激活函数。最后的输出一般会有特定的激活函数,不能随意改变,比如二分类一般用sigmoid函数激活,多分类一般用softmax激活,等等;相比之下,中间层的激活函数选择余地更大一些。
浮点误差都行!
理论上来说,只要是非线性函数,都有做激活函数的可能性,一个很有说服力的例子是,最近OpenAI成功地利用了浮点误差来做激活函数,其中的细节,请阅读OpenAI的博客:
https://blog.openai.com/nonlinear-computation-in-linear-networks/
或者阅读机器之心的介绍:
https://mp.weixin.qq.com/s/PBRzS4Ol_Zst35XKrEpxdw

最近评论