






26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 228329位读者 | 引用今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 299162位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
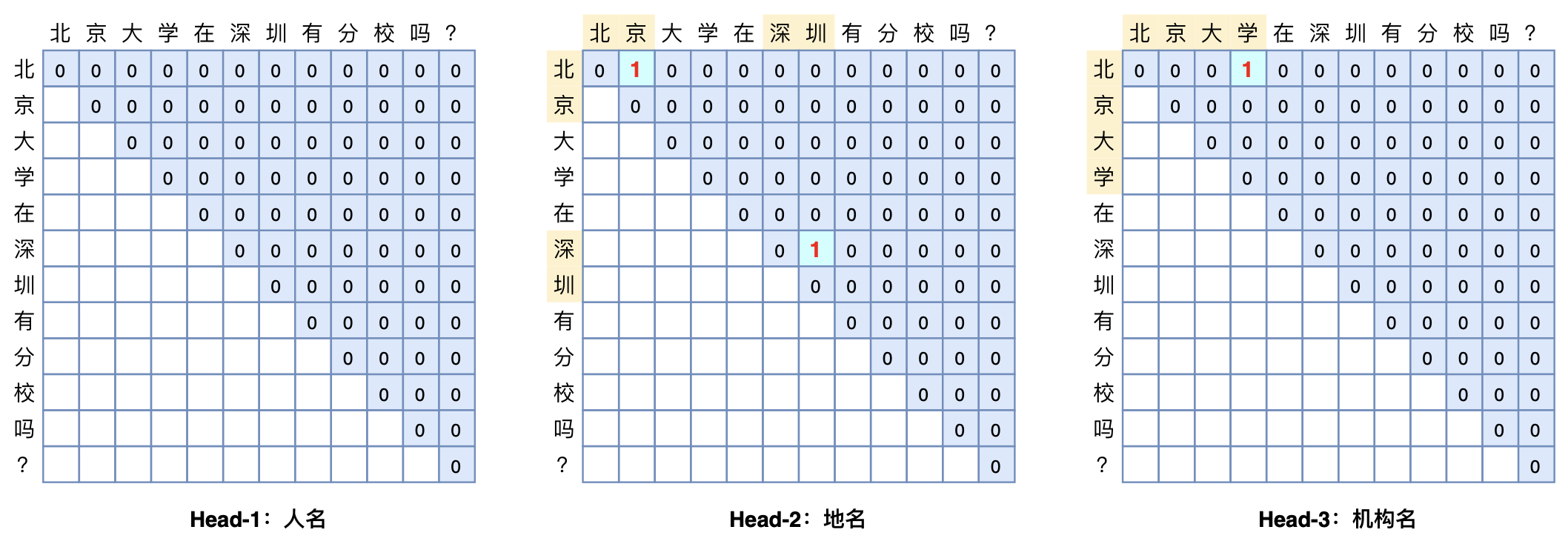
GlobalPointer多头识别嵌套实体示意图
10
May
Transformer升级之路:4、二维位置的旋转式位置编码
By 苏剑林 | 2021-05-10 | 98960位读者 | 引用在之前的文章《Transformer升级之路:2、博采众长的旋转式位置编码》中我们提出了旋转式位置编码RoPE以及对应的Transformer模型RoFormer。由于笔者主要研究的领域还是NLP,所以本来这个事情对于笔者来说已经完了。但是最近一段时间,Transformer模型在视觉领域也大火,各种Vision Transformer(ViT)层出不穷,于是就有了问题:二维情形的RoPE应该是怎样的呢?
咋看上去,这个似乎应该只是一维情形的简单推广,但其中涉及到的推导和理解却远比我们想象中复杂,本文就对此做一个分析,从而深化我们对RoPE的理解。
二维RoPE
什么是二维位置?对应的二维RoPE又是怎样的?它的难度在哪里?在这一节中,我们先简单介绍二维位置,然后直接给出二维RoPE的结果和推导思路,在随后的几节中,我们再详细给出推导过程。
17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 131869位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
\begin{equation}\mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \Big[\mathbb{E}_{z\sim p(z|x)}\big[-\log q(x|z)\big]+KL\big(p(z|x)\big\Vert q(z)\big)\Big]
\end{equation}
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 59447位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 56439位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
17
Jun
对比学习可以使用梯度累积吗?
By 苏剑林 | 2021-06-17 | 58269位读者 | 引用在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们介绍过“梯度累积”,它是在有限显存下实现大batch_size效果的一种技巧。一般来说,梯度累积适用的是loss是独立同分布的场景,换言之每个样本单独计算loss,然后总loss是所有单个loss的平均或求和。然而,并不是所有任务都满足这个条件的,比如最近比较热门的对比学习,每个样本的loss还跟其他样本有关。
那么,在对比学习场景,我们还可以使用梯度累积来达到大batch_size的效果吗?本文就来分析这个问题。
简介
一般情况下,对比学习的loss可以写为
\begin{equation}\mathcal{L}=-\sum_{i,j=1}^b t_{i,j}\log p_{i,j} = -\sum_{i,j=1}^b t_{i,j}\log \frac{e^{s_{i,j}}}{\sum\limits_j e^{s_{i,j}}}=-\sum_{i,j=1}^b t_{i,j}s_{i,j} + \sum_{i=1}^b \log\sum_{j=1}^b e^{s_{i,j}}\label{eq:loss}\end{equation}
这里的$b$是batch_size;$t_{i,j}$是事先给定的标签,满足$t_{i,j}=t_{j,i}$,它是一个one hot矩阵,每一列只有一个1,其余都为0;而$s_{i,j}$是样本$i$和样本$j$的相似度,满足$s_{i,j}=s_{j,i}$,一般情况下还有个温度参数,这里假设温度参数已经整合到$s_{i,j}$中,从而简化记号。模型参数存在于$s_{i,j}$中,假设为$\theta$。
29
Jun

最近评论