






6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 865420位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 122980位读者 | 引用前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
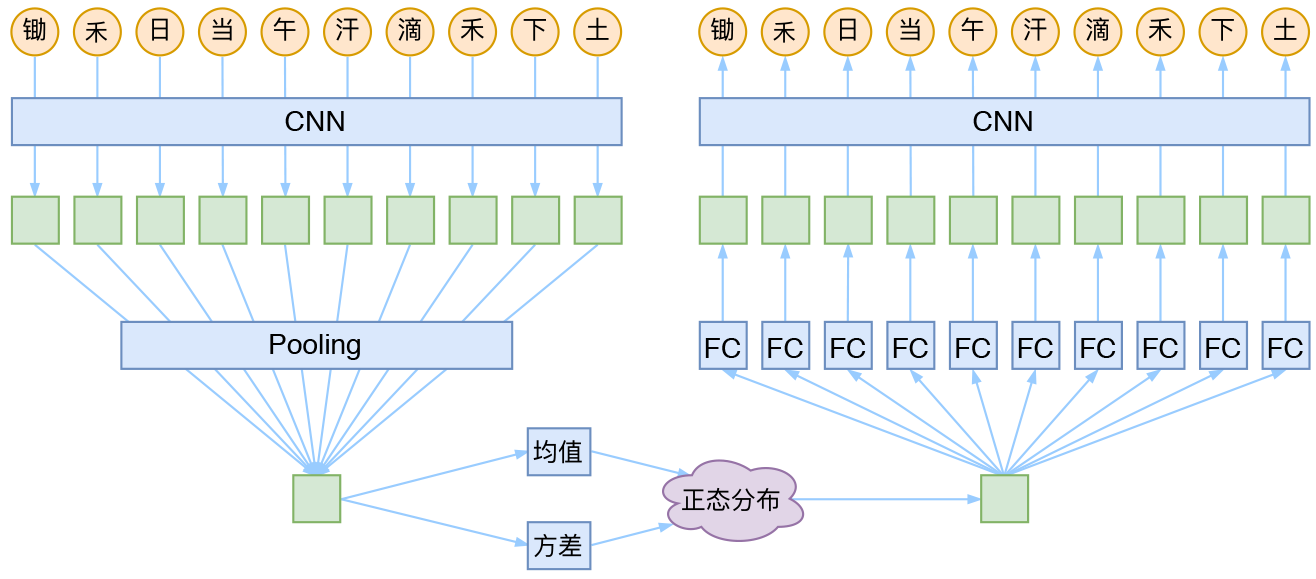
cnn + vae 诗歌生成模型
6
Aug
“让Keras更酷一些!”:精巧的层与花式的回调
By 苏剑林 | 2018-08-06 | 165987位读者 | 引用Keras伴我走来
回想起进入机器学习领域的这两三年来,Keras是一直陪伴在笔者的身边。要不是当初刚掉进这个坑时碰到了Keras这个这么易用的框架,能快速实现我的想法,我也不确定我是否能有毅力坚持下来,毕竟当初是theano、pylearn、caffe、torch等的天下,哪怕在今天它们对我来说仍然像天书一般。
后来为了拓展视野,我也去学习了一段时间的tensorflow,用纯tensorflow写过若干程序,但不管怎样,仍然无法割舍Keras。随着对Keras的了解的深入,尤其是花了一点时间研究过Keras的源码后,我发现Keras并没有大家诟病的那样“欠缺灵活性”。事实上,Keras那精巧的封装,可以让我们轻松实现很多复杂的功能。我越来越感觉,Keras像是一件非常精美的艺术品,充分体现了Keras的开发者们深厚的创作功力。
本文介绍Keras中自定义模型的一些内容,相对而言,这属于Keras进阶的内容,刚入门的朋友请暂时忽略。
层的自定义
这里介绍Keras中自定义层及其一些运用技巧,在这之中我们可以看到Keras层的精巧之处。
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 304068位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 360818位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
8
Sep
“让Keras更酷一些!”:小众的自定义优化器
By 苏剑林 | 2018-09-08 | 85251位读者 | 引用沿着之前的《“让Keras更酷一些!”:精巧的层与花式的回调》写下去~
今天我们来看一个小众需求:自定义优化器。
细想之下,不管用什么框架,自定义优化器这个需求可谓真的是小众中的小众。一般而言,对于大多数任务我们都可以无脑地直接上Adam,而调参炼丹高手一般会用SGD来调出更好的效果,换言之不管是高手新手,都很少会有自定义优化器的需求。
那这篇文章还有什么价值呢?有些场景下会有一点点作用。比如通过学习Keras中的优化器写法,你可以对梯度下降等算法有进一步的认识,你还可以顺带看到Keras的源码是多么简洁优雅。此外,有时候我们可以通过自定义优化器来实现自己的一些功能,比如给一些简单的模型(例如Word2Vec)重写优化器(直接写死梯度,而不是用自动求导),可以使得算法更快;自定义优化器还可以实现诸如“软batch”的功能。
Keras优化器
我们首先来看Keras中自带优化器的代码,位于:
https://github.com/keras-team/keras/blob/master/keras/optimizers.py
20
Dec
从动力学角度看优化算法(二):自适应学习率算法
By 苏剑林 | 2018-12-20 | 46881位读者 | 引用在《从动力学角度看优化算法(一):从SGD到动量加速》一文中,我们提出SGD优化算法跟常微分方程(ODE)的数值解法其实是对应的,由此还可以很自然地分析SGD算法的收敛性质、动量加速的原理等等内容。
在这篇文章中,我们继续沿着这个思路,去理解优化算法中的自适应学习率算法。
RMSprop
首先,我们看一个非常经典的自适应学习率优化算法:RMSprop。RMSprop虽然不是最早提出的自适应学习率的优化算法,但是它却是相当实用的一种,它是诸如Adam这样的更综合的算法的基石,通过它我们可以观察自适应学习率的优化算法是怎么做的。
算法概览
一般的梯度下降是这样的:
$$\begin{equation}\boldsymbol{\theta}_{n+1}=\boldsymbol{\theta}_{n} - \gamma \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\end{equation}$$
很明显,这里的$\gamma$是一个超参数,便是学习率,它可能需要在不同阶段做不同的调整。
而RMSprop则是
$$\begin{equation}\begin{aligned}\boldsymbol{g}_{n+1} =& \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\\
\boldsymbol{G}_{n+1}=&\lambda \boldsymbol{G}_{n} + (1 - \lambda) \boldsymbol{g}_{n+1}\otimes \boldsymbol{g}_{n+1}\\
\boldsymbol{\theta}_{n+1}=&\boldsymbol{\theta}_{n} - \frac{\tilde{\gamma}}{\sqrt{\boldsymbol{G}_{n+1} + \epsilon}}\otimes \boldsymbol{g}_{n+1}
\end{aligned}\end{equation}$$
7
Oct
深度学习中的Lipschitz约束:泛化与生成模型
By 苏剑林 | 2018-10-07 | 149028位读者 | 引用前言:去年写过一篇WGAN-GP的入门读物《互怼的艺术:从零直达WGAN-GP》,提到通过梯度惩罚来为WGAN的判别器增加Lipschitz约束(下面简称“L约束”)。前几天遐想时再次想到了WGAN,总觉得WGAN的梯度惩罚不够优雅,后来也听说WGAN在条件生成时很难搞(因为不同类的随机插值就开始乱了...),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到。主要包含在这两篇论文中:《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》和《Spectral Normalization for Generative Adversarial Networks》。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是L约束,并不只是WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为$x$,输出为$y$,模型为$f$,模型参数为$w$,记为
$$\begin{equation}y = f_w(x)\end{equation}$$
很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了$f_{w+\Delta w}(x)$后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到$f_w(x)$;二是对于输入扰动的稳定性,比如输入从$x$变成了$x+\Delta x$后,$f_w(x+\Delta x)$是否能给出相近的预测结果。读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。

最近评论