






20
Aug
最小熵原理(六):词向量的维度应该怎么选择?
By 苏剑林 | 2020-08-20 | 98357位读者 | 引用随着NLP的发展,像Word2Vec、Glove这样的词向量模型,正逐渐地被基于Transformer的BERT等模型代替,不过经典始终是经典,词向量模型依然在不少场景发光发热,并且仍有不少值得我们去研究的地方。本文我们来关心一个词向量模型可能有的疑惑:词向量的维度大概多少才够?
先说结论,笔者给出的估算结果是
\begin{equation}n > 8.33\log N\label{eq:final}\end{equation}
更简约的话可以直接记$n > 8\log N$,其中$N$是词表大小,$n$就是词向量维度,$\log$是自然对数。当$n$超过这个阈值时,就说明模型有足够的容量容纳这$N$个词语(当然$n$越大过拟合风险也越大)。这样一来,当$N=100000$时,得到的$n$大约是96,所以对于10万个词的词向量模型来说,维度选择96就足够了;如果要容纳500万个词,那么$n$大概就是128。
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 381893位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
19
Jun
简述无偏估计和有偏估计
By 苏剑林 | 2019-06-19 | 79875位读者 | 引用对于大多数读者(包括笔者)来说,他们接触到的第一个有偏估计量,应该是方差
\begin{equation}\hat{\sigma}^2_{\text{有偏}} = \frac{1}{n}\sum_{i=1}^n \left(x_i - \hat{\mu}\right)^2,\quad \hat{\mu} = \frac{1}{n}\sum_{i=1}^n x_i\label{eq:youpianfangcha}\end{equation}
然后又了解到对应的无偏估计应该是
\begin{equation}\hat{\sigma}^2_{\text{无偏}} = \frac{1}{n-1}\sum_{i=1}^n \left(x_i - \hat{\mu}\right)^2\label{eq:wupianfangcha}\end{equation}
在很多人的眼里,公式$\eqref{eq:youpianfangcha}$才是合理的,怎么就有偏了?公式$\eqref{eq:wupianfangcha}$将$n$换成反直觉的$n-1$,反而就无偏了?
下面试图用尽量清晰的语言讨论一下无偏估计和有偏估计两个概念。
10
Oct
居然是他!奥巴马获得2009年诺贝尔和平奖!
By 苏剑林 | 2009-10-10 | 19324位读者 | 引用站长:因为10月8日就上学了,所以不能够及时上网查阅和更新文学奖和和平奖的消息。不过一直在用手机关注着,前天晚上7:00,就一直用手机关注着诺贝尔奖官方网站,最终发现德国人取得了文学奖。而昨天晚上,一个更加惊人的消息发出来了——2009年诺贝尔和平奖的得主竟然是Barack Obama!
太意外了!居然是我们熟悉的美国总统!世界各国也是这样的意外,然而,令人深思的应该是:颁布诺贝尔奖给奥巴马的主要原因,并非肯定奥巴马已经有的成就,应该是鼓励他带领美国为世界作出更大的贡献!由此观之,世界对这位美国总统的期望是十分大的!
中国网10月9日电 据路透社报道,10月9日美国总统贝拉克·奥巴马(Barack Obama )因为世界和平所做的工作,以及呼吁削减世界核武库而赢得2009年诺贝尔和平奖。

奥巴马获2009年诺贝尔和平奖
16
Oct
以自然数幂为系数的幂级数
By 苏剑林 | 2010-10-16 | 31197位读者 | 引用$\sum_{i=0}^{\infty} a_i x^i=a_0+a_1 x+a_2 x^2+a_3 x^3+...$
最近为了数学竞赛,我研究了有关数列和排列组合的相关问题。由于我讨厌为某个问题而设计专门的技巧,所以我偏爱通用的方法,哪怕过程相对麻烦。因此,我对数学归纳法(递推法)和生成函数法情有独钟。前者只需要列出问题的递归关系,而不用具体分析,最终把问题转移到解函数方程上来。后者则巧妙地把数列${a_n}$与幂级数$\sum_{i=0}^{\infty} a_i x^i$一一对应,巧妙地通过代数运算或微积分运算等得到结果。这里我们不用考虑该级数的敛散性,只需要知道它对应着哪一个“母函数”(母函数展开泰勒级数后得到了级数$\sum_{i=0}^{\infty} a_i x^i$)。显然,这两种方法的最终,都是把问题归结为代数问题。
27
Nov
《自然极值》系列——1.前言
By 苏剑林 | 2010-11-27 | 51771位读者 | 引用附:期中考过后,课程紧了,自由时间少了,因此科学空间的更新也放缓了。不过BoJone也会尽量地更新一些内容,和大家一同分享学习的乐趣。
![闭区间[a,b]上的连续函数?(x),其最大值为红色点,最小值为蓝色点](/usr/uploads/2010/11/3941873990.png)
闭区间[a,b]上的连续函数?(x),其最大值为红色点,最小值为蓝色点
上一周和这一周的时间里,BoJone将自己学习物理和极值的一些内容进行了总结和整合,写成了《自然极值》一文。因此从今天起,到十二月的大多数时间里,科学空间将和大家讲述并讨论关于“极值”的问题,希望读者会喜欢这部分内容。当然,我不是专业的研究人员,更不是经验丰富的物理和数学教师,甚至可以说是一个“乳臭未干的小子”,因此,错误在所难免,只希望同好不吝指出,更希冀能够起到我抛出的这一块“砖”能够引出美妙的“玉”。
27
Nov
《自然极值》系列——2.费马原理
By 苏剑林 | 2010-11-27 | 42415位读者 | 引用物理学的美不仅仅表现在简洁的公式上。我们还惊奇地发现,很多物理现象都是按照使某个变量达到极值的方式发生。一个典型的例子就是费马原理,它指出了光的传播路径的一个重要规律:光总是沿着所花时间最短的路径传播。这里我们将简单介绍一下费马原理。
费马原理俗称“最快到达原理”、“最小时间原理”。1657年,费马提出:
从P点到达Q点,在所有可行的路径中,光选择了所需时间最短的一条。
从P点到达Q点,在所有可行的路径中,光选择了所需时间为极值的一条。
这是一个极其奇妙的原理,也是自然界中最神奇的极值之一。作为非生物的光,居然自主地选择了最优路径,成为世界上“效率最高”的东西,这让人不得不佩服宇宙的伟大。这究竟是造物者的精心设计,还是无心之作?
10
Dec
《自然极值》系列——6.最速降线的解答
By 苏剑林 | 2010-12-10 | 61574位读者 | 引用通过上一小节的小故事,我们已经能够基本了解最速降线的内容了,它就是要我们求出满足某一极值条件的一个未知函数,由于函数是未知的,因此这类问题被称为“泛分析”。其中还谈到,伯努利利用费马原理巧妙地得出了答案,那么我们现在就再次回顾历史,追寻伯努利的答案,并且寻找进一步的应用。
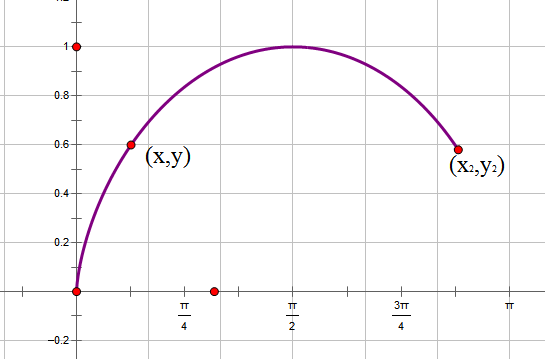
最速降线-1
为了计算方便,我们把最速降线倒过来,把初始点设置在原点。在下落过程中,重力势能转化为动能,因此,在点(x,y)处有$\frac{1}{2} mv^2=mgy\Rightarrow v=\sqrt{2gy}$,由于纯粹为了探讨曲线形状,所以我们使g=0.5,即$v=\sqrt{y}$。在点(x,y)处所走的路程为$ds=\sqrt{dy^2+dx^2}=\sqrt{\dot{y}^2+1}dx$,所以时间为$dt=\frac{ds}{v}=\frac{\sqrt{\dot{y}^2+1}dx}{\sqrt{y}}$,于是最速降线问题就是求使$t=\int_0^{x_2} \frac{\sqrt{\dot{y}^2+1}dx}{\sqrt{y}}$最小的函数。

最近评论