






7
Nov
【外微分浅谈】6. 微分几何
By 苏剑林 | 2016-11-07 | 45217位读者 | 引用终于开始谈到重点了,就是这部分内容促使我学习外微分的。用外微分可以方便地推导微分几何的一些内容,有时候还能方便计算。其主要根源在于:外微分本身在形式上是微分的推广,因此微分几何的东西能够使用外微分来描述并不出奇;然后,最重要的原因是,外微分把$dx^{\mu}$看成一组基,因此相当于在几何中引入了两组基,一组是本身的向量基(用张量的语言,就是逆变向量的基),这组基可以做对称的内积,另外一组基就是$dx^{\mu}$,这组基可以做反对称的外积。因此,当外微分引入几何时,微分几何就拥有了微分、积分、对称积、反对称积等各种“理想装备”,这就是外微分能够加速微分几何推导的主要原因。
标架的运动
前面已经得到
$$\begin{aligned}&\omega^{\mu}=h_{\alpha}^{\mu}dx^{\alpha}\\
&d\boldsymbol{r}=\hat{\boldsymbol{e}}_{\mu} \omega^{\mu}\\
&ds^2 = \eta_{\mu\nu} \omega^{\mu}\omega^{\nu}\\
&\langle \hat{\boldsymbol{e}}_{\mu}, \hat{\boldsymbol{e}}_{\nu}\rangle = \eta_{\mu\nu}\end{aligned} \tag{45} $$
16
Oct
如何划分一个跟测试集更接近的验证集?
By 苏剑林 | 2020-10-16 | 56715位读者 | 引用不管是打比赛、做实验还是搞工程,我们经常会遇到训练集与测试集分布不一致的情况。一般来说我们会从训练集中划分出来一个验证集,通过这个验证集来调整一些超参数(参考《训练集、验证集和测试集的意义》),比如控制模型的训练轮数以防止过拟合。然而,如果验证集本身跟测试集差别比较大,那么验证集上很好的模型也不代表在测试集上很好,因此如何让划分出来验证集跟测试集的分布差异更小一些,是一个值得研究的题目。
两种情况
首先,明确一下,本文所考虑的,是能给拿到测试集数据本身、但不知道测试集标签的场景。如果是那种提交模型封闭评测的场景,我们完全看不到测试集的,那就没什么办法了。为什么会出现测试集跟训练集分布不一致的现象呢?主要有两种情况。
22
Oct
分享:孟岩的《理解矩阵》一文
By 苏剑林 | 2012-10-22 | 57997位读者 | 引用
数学演算
之前已经提到我要自学相对论和量子力学。作为现代物理的两大支柱,所用的数学也是很“现代”的,不能总是用高中那套简单的模式来计算,所以线性代数是我要熟悉的一门课程之一。现在大一还没开设线性代数课程,但是我所持的观点是:“任何东西只要你需要它,你就应该去学,而且能够学会。”其实我初三暑假的时候就开始接触了线性代数,我看的那本教材,跟国内其他线性代数教材一样,采用了一种只要求记忆和计算的方式来教授,先讲从线性方程组引出行列式,再到矩阵。我那时也在背诵,知道了了行列式怎么算的,行列式可以用来解方程组,矩阵是怎么相乘的等等。但我完全不知道为什么,我甚至不懂为什么这门课程叫“线性代数”。(当然,也有可能是那时的数学水平不够)国外很多教程都讲的很好,很规范地教,但是对于国内像我这样平庸的学生又显得过于专业。我一直期待有这样的一个平衡点,可惜一直没有找到,所以只能从各种渠道摸索。
16
Oct
以自然数幂为系数的幂级数
By 苏剑林 | 2010-10-16 | 31333位读者 | 引用$\sum_{i=0}^{\infty} a_i x^i=a_0+a_1 x+a_2 x^2+a_3 x^3+...$
最近为了数学竞赛,我研究了有关数列和排列组合的相关问题。由于我讨厌为某个问题而设计专门的技巧,所以我偏爱通用的方法,哪怕过程相对麻烦。因此,我对数学归纳法(递推法)和生成函数法情有独钟。前者只需要列出问题的递归关系,而不用具体分析,最终把问题转移到解函数方程上来。后者则巧妙地把数列${a_n}$与幂级数$\sum_{i=0}^{\infty} a_i x^i$一一对应,巧妙地通过代数运算或微积分运算等得到结果。这里我们不用考虑该级数的敛散性,只需要知道它对应着哪一个“母函数”(母函数展开泰勒级数后得到了级数$\sum_{i=0}^{\infty} a_i x^i$)。显然,这两种方法的最终,都是把问题归结为代数问题。
28
Nov
《自然极值》系列——4.费马点问题
By 苏剑林 | 2010-11-28 | 86490位读者 | 引用通过上面众多的文字描述,也许你还不大了解这两个原理有何美妙之处,也或者你已经迫不及待地想去应用它们却不知思路。为了不至于让大家产生“审美疲劳”,接下来我们将试图利用这两个原理对费马点问题进行探讨,看看原理究竟是怎么发挥作用的。运用的关键在于:如何通过适当的变换将其与光学或势能联系起来。
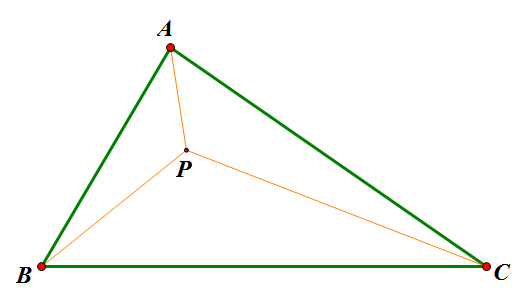
费马点问题
传统费马点问题是指在ΔABC中寻找点P,使得$AP+BP+CP$最小的问题;而广义的费马点则改成使$k_1 AP+k_2 BP+k_3 CP$最小。这是很具有现实意义的,是“在三个村庄之间建立一个中转站,如何才能使运送成为最低”之类的最优问题。我们将从光学和势能两个角度对这个问题进行探讨(也许有的读者已经阅读过了利用重力的原理来求解费马点,但是我想光学的方法依然会是你眼前一亮的。)
3
Mar
指数梯度下降 + 元学习 = 自适应学习率
By 苏剑林 | 2022-03-03 | 29526位读者 | 引用前两天刷到了Google的一篇论文《Step-size Adaptation Using Exponentiated Gradient Updates》,在其中学到了一些新的概念,所以在此记录分享一下。主要的内容有两个,一是非负优化的指数梯度下降,二是基于元学习思想的学习率调整算法,两者都颇有意思,有兴趣的读者也可以了解一下。
指数梯度下降
梯度下降大家可能听说得多了,指的是对于无约束函数$\mathcal{L}(\boldsymbol{\theta})$的最小化,我们用如下格式进行更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\end{equation}
其中$\eta$是学习率。然而很多任务并非总是无约束的,对于最简单的非负约束,我们可以改为如下格式更新:
\begin{equation}\boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t \odot \exp\left(- \eta\nabla_{\boldsymbol{\theta}}\mathcal{L}(\boldsymbol{\theta}_t)\right)\label{eq:egd}\end{equation}
这里的$\odot$是逐位对应相乘(Hadamard积)。容易看到,只要初始化的$\boldsymbol{\theta}_0$是非负的,那么在整个更新过程中$\boldsymbol{\theta}_t$都会保持非负,这就是用于非负约束优化的“指数梯度下降”。
16
Aug
微积分学习(一):极限
By 苏剑林 | 2009-08-16 | 26655位读者 | 引用本文不是微积分教程,而是发表自己学习中的一些看法,以及与同好们讨论相关问题。
拿起任何一本“微积分”教程,都可以看见那专业而严格的数学语言,因此很多人望而生畏。的确,由于牛顿和莱布尼茨创立的微积分是不严格的,因此引发了第二次数学危机。经过法国数学家柯西和德国数学家魏尔斯特拉斯的努力,使得微积分有了前所未有的严密化,克服了第二次数学危机。加之后来的第三次数学危机,数学就更加严密了。
但是对于初学者,严密化的微积分令人十分费解。因此,我们不妨按照微积分的创立顺序,即“不严密——严密”的顺序来学习。这样不仅能够让我们更高效率地学习,而且增加学习数学的兴趣。
1
Oct


最近评论