






18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 331780位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
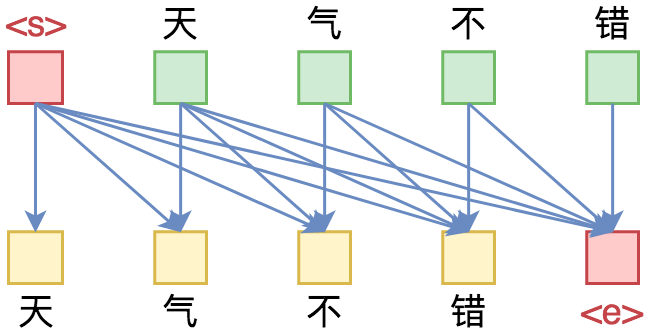
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 68972位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。
1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 239949位读者 | 引用“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。
25
Dec
写了个刷论文的辅助网站:Cool Papers
By 苏剑林 | 2023-12-25 | 95114位读者 | 引用写在开头
一直以来,笔者都有日刷Arxiv的习惯,以求尽可能跟上领域内最新成果,并告诫自己“不进则退”。之前也有不少读者问我是怎么刷Arxiv的、有什么辅助工具等,但事实上,在很长的时间里,笔者都是直接刷Arxiv官网,并且没有用任何算法过滤,都是自己一篇篇过的。这个过程很枯燥,但并非不能接受,之所以不用算法初筛,主要还是担心算法漏召,毕竟“刷”就是为了追新,一旦算法漏召就“错失先机”了。
自从Kimi Chat发布后,笔者就一直计划着写一个辅助网站结合Kimi来加速刷论文的过程。最近几个星期稍微闲了一点,于是在GPT4、Kimi的帮助下,初步写成了这个网站,并且经过几天的测试和优化后,已经逐步趋于稳定,于是正式邀请读者试用。
Cool Papers:https://papers.cool
22
Aug
【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
By 苏剑林 | 2016-08-22 | 470528位读者 | 引用关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM
18
Aug
【中文分词系列】 2. 基于切分的新词发现
By 苏剑林 | 2016-08-18 | 124773位读者 | 引用上一篇文章讲的是基于词典和AC自动机的快速分词。基于词典的分词有一个明显的优点,就是便于维护,容易适应领域。如果迁移到新的领域,那么只需要添加对应的领域新词,就可以实现较好地分词。当然,好的、适应领域的词典是否容易获得,这还得具体情况具体分析。本文要讨论的就是新词发现这一部分的内容。
这部分内容在去年的文章《新词发现的信息熵方法与实现》已经讨论过了,算法是来源于matrix67的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》。在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到$n$字词,就需要找出$1\sim n$字的切片,然后分别做计算,这对于$n$比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
13
Jan
【中文分词系列】 6. 基于全卷积网络的中文分词
By 苏剑林 | 2017-01-13 | 60214位读者 | 引用之前已经写过用LSTM来做分词的方案了,今天再来一篇用CNN的,准确来说是FCN,全卷积网络。其实这个模型的主要目的并非研究中文分词,而是练习tensorflow。从两年前就开始用Keras了,可以说对它比较熟了,也渐渐发现了它的一些不足,比如处理变长输入时不方便、加入自定义的约束比较困难等,所以干脆试试原生的tensorflow了,试了之后发现其实也不复杂。嗯,都是python,能有多复杂。本文就是练习一下如何用tensorflow处理不定长输入任务,以中文分词为例,并在最后加入了硬解码,将深度学习与词典分词结合了起来。
CNN
另外,就是关于FCN的。放到语言任务中看,(一维)卷积其实就是ngram模型,从这个角度来看其实CNN远比RNN来得自然,RNN好像就是为序列任务精心设计的,而CNN则是传统ngram模型的一个延伸。另外不管CNN和RNN都有权值共享,看上去只是为了降低运算量的一个折中选择,但事实上里边大有道理。CNN中的权值共享是平移不变性的必然结果,而不是仅仅是降低运算量的一个选择,试想一下,将一幅图像平移一点点,或者在一个句子前插入一个无意义的空格(导致后面所有字都向后平移了一位),这样应该给出一个相似甚至相同的结果,而这要求卷积必然是权值共享的,即权值不能跟位置有关系。
12
Apr
【语料】百度的中文问答数据集WebQA
By 苏剑林 | 2017-04-12 | 225148位读者 | 引用信息抽取
众所周知,百度知道上有大量的人提了大量的问题,并且得到大量的回复。然而,百度知道上的回复者貌似懒人居多,他们往往喜欢直接在网上复制粘贴一大片来作为回答内容,而且这些内容可能跟问题相关,也可能跟问题不相关,比如
https://zhidao.baidu.com/question/557785746.html
问:广州白云山海拨多高
答:广州白云山(Guangzhou Baiyun Mountain),是新 “羊城八景”之首、国家4A级景区和国家重点风景名胜区。它位于广州市的东北部,为南粤名山之一,自古就有“羊城第一秀”之称。山体相当宽阔,由30多座山峰组成,为广东最高峰九连山的支脉。面积20.98平方公里,主峰摩星岭高382米(注:最新测绘高度为372.6米——国家测绘局,2008年),峰峦重叠,溪涧纵横,登高可俯览全市,遥望珠江。每当雨后天晴或暮春时节,山间白云缭绕,蔚为奇观,白云山之名由此得来

最近评论