






12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 152370位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
29
Nov
轻便的深度学习分词系统:NNCWS v0.1
By 苏剑林 | 2016-11-29 | 21979位读者 | 引用好吧,我也做了一回标题党...其实本文的分词系统是一个三层的神经网络模型,因此只是“浅度学习”,写深度学习是显得更有吸引力。NNCWS的意思是Neutral Network based Chinese Segment System,基于神经网络的中文分词系统,Python写的,目前完全公开,读者可以试用。
闲话多说
这个程序有什么特色?几乎没有!本文就是用神经网络结合字向量实现了一个ngrams形式(程序中使用了7-grams)的分词系统,没有像《【中文分词系列】 4. 基于双向LSTM的seq2seq字标注》那样使用了高端的模型,也没有像《【中文分词系列】 5. 基于语言模型的无监督分词》那样可以无监督训练,这里纯粹是一个有监督的简单模型,训练语料是2014年人民日报标注语料。
11
Mar
【中文分词系列】 8. 更好的新词发现算法
By 苏剑林 | 2017-03-11 | 230785位读者 | 引用如果依次阅读该系列文章的读者,就会发现这个系列共提供了两种从0到1的无监督分词方案,第一种就是《【中文分词系列】 2. 基于切分的新词发现》,利用相邻字凝固度(互信息)来做构建词库(有了词库,就可以用词典法分词);另外一种是《【中文分词系列】 5. 基于语言模型的无监督分词》,后者基本上可以说是提供了一种完整的独立于其它文献的无监督分词方法。
但总的来看,总感觉前面一种很快很爽,却又显得粗糙;后面一种很好很强大,却又显得太过复杂(viterbi是瓶颈之一)。有没有可能在两者之间折中一下?这就导致了本文的结果,达到了速度与效果的平衡。至于为什么说“更好”?因为笔者研究词库构建也有一段时间了,以往构建的词库总不能让人(让自己)满意,生成的词库一眼看上去,都能够扫到不少不合理的地方,真的要用得需要经过较多的人工筛选。而这一次,一次性生成的词库,一眼扫过去,不合理的地方少了很多,如果不细看,可能就发现不了了。
分词的目的
3
Apr
【不可思议的Word2Vec】 2.训练好的模型
By 苏剑林 | 2017-04-03 | 437068位读者 | 引用由于后面几篇要讲解Word2Vec怎么用,因此笔者先训练好了一个Word2Vec模型。为了节约读者的时间,并且保证读者可以复现后面的结果,笔者决定把这个训练好的模型分享出来,用Gensim训练的。单纯的词向量并不大,但第一篇已经说了,我们要用到完整的Word2Vec模型,因此我将完整的模型分享出来了,包含四个文件,所以文件相对大一些。
提醒读者的是,如果你想获取完整的Word2Vec模型,又不想改源代码,那么Python的Gensim库应该是你唯一的选择,据我所知,其他版本的Word2Vec最后都是只提供词向量给我们,没有完整的模型。
对于做知识挖掘来说,显然用知识库语料(如百科语料)训练的Word2Vec效果会更好。但百科语料我还在爬取中,爬完了我再训练一个模型,到时再分享。
模型概况
这个模型的大概情况如下:
$$\begin{array}{c|c}
\hline
\text{训练语料} & \text{微信公众号的文章,多领域,属于中文平衡语料}\\
\hline
\text{语料数量} & \text{800万篇,总词数达到650亿}\\
\hline
\text{模型词数} & \text{共352196词,基本是中文词,包含常见英文词}\\
\hline
\text{模型结构} & \text{Skip-Gram + Huffman Softmax}\\
\hline
\text{向量维度} & \text{256维}\\
\hline
\text{分词工具} & \text{结巴分词,加入了有50万词条的词典,关闭了新词发现}\\
\hline
\text{训练工具} & \text{Gensim的Word2Vec,服务器训练了7天}\\
\hline
\text{其他情况} & \text{窗口大小为10,最小词频是64,迭代了10次}\\
\hline
\end{array}$$
10
Dec
BiGAN-QP:简单清晰的编码&生成模型
By 苏剑林 | 2018-12-10 | 66440位读者 | 引用前不久笔者通过直接在对偶空间中分析的思路,提出了一个称为GAN-QP的对抗模型框架,它的特点是可以从理论上证明既不会梯度消失,又不需要L约束,使得生成模型的搭建和训练都得到简化。
GAN-QP是一个对抗框架,所以理论上原来所有的GAN任务都可以往上面试试。前面《不用L约束又不会梯度消失的GAN,了解一下?》一文中我们只尝试了标准的随机生成任务,而这篇文章中我们尝试既有生成器、又有编码器的情况:BiGAN-QP。
BiGAN与BiGAN-QP
注意这是BiGAN,不是前段时间很火的BigGAN,BiGAN是双向GAN(Bidirectional GAN),提出于《Adversarial feature learning》一文,同期还有一篇非常相似的文章叫做《Adversarially Learned Inference》,提出了叫做ALI的模型,跟BiGAN差不多。总的来说,它们都是往普通的GAN模型中加入了编码器,使得模型既能够具有普通GAN的随机生成功能,又具有编码器的功能,可以用来提取有效的特征。把GAN-QP这种对抗模式用到BiGAN中,就得到了BiGAN-QP。
话不多说,先来上效果图(左边是原图,右边是重构):

BiGAN-QP重构效果图
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 116541位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
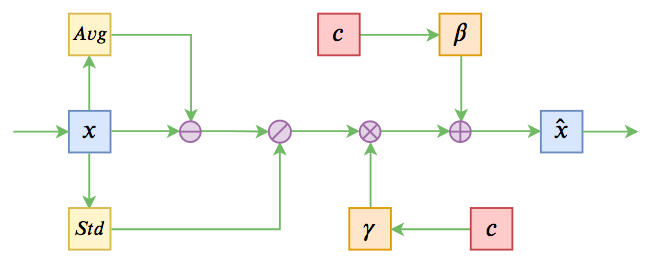
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 412878位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 87024位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
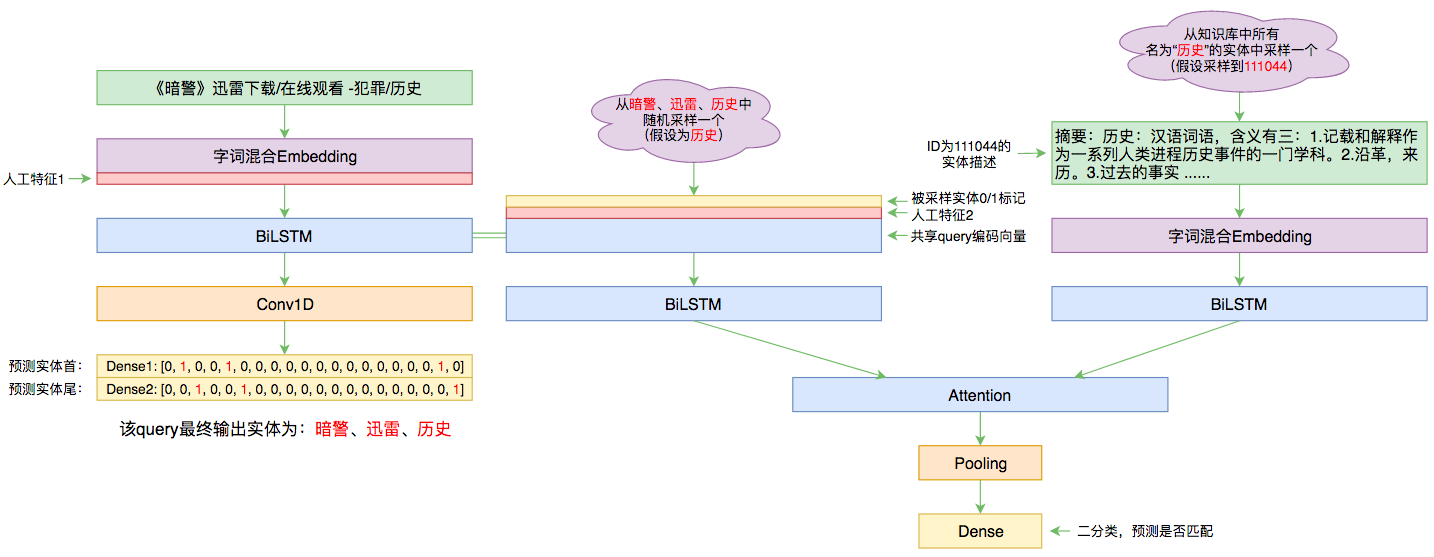
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。

最近评论