






24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 92079位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。
代码
6
Aug
【不可思议的Word2Vec】6. Keras版的Word2Vec
By 苏剑林 | 2017-08-06 | 139483位读者 | 引用前言
看过我之前写的TF版的Word2Vec后,Keras群里的Yin神问我有没有Keras版的。事实上在做TF版之前,我就写过Keras版的,不过没有保留,所以重写了一遍,更高效率,代码也更好看了。纯Keras代码实现Word2Vec,原理跟《【不可思议的Word2Vec】5. Tensorflow版的Word2Vec》是一样的,现在放出来,我想,会有人需要的。(比如,自己往里边加一些额外输入,然后做更好的词向量模型?)
由于Keras同时支持tensorflow、theano、cntk等多个后端,这就等价于实现了多个框架的Word2Vec了。嗯,这样想就高大上了,哈哈~
代码
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 201281位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
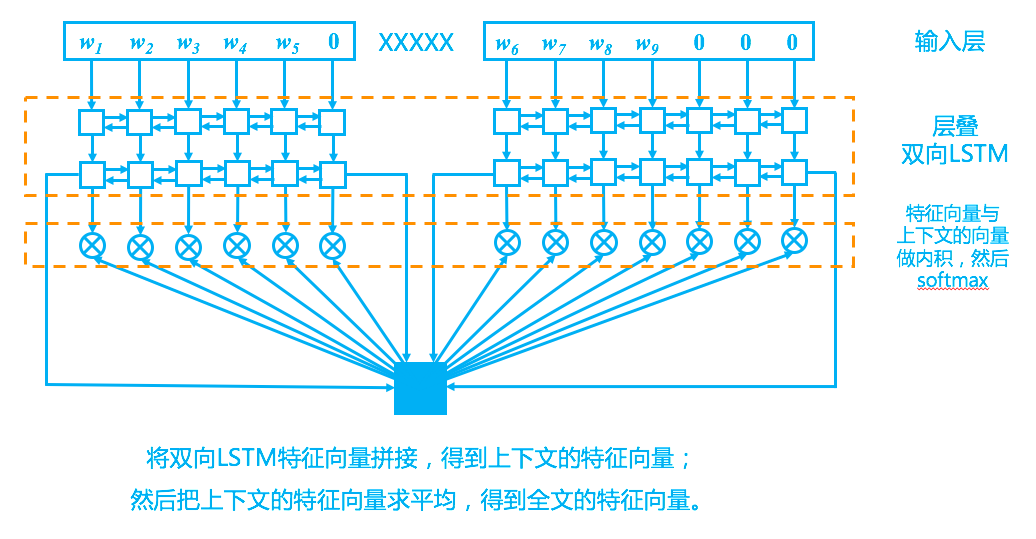
完形填空模型
16
Jul
Linux下的误删大坑与简单的恢复技巧
By 苏剑林 | 2017-07-16 | 28554位读者 | 引用
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 430256位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
13
Oct
基于fine tune的图像分类(百度分狗竞赛)
By 苏剑林 | 2017-10-13 | 28390位读者 | 引用
baidu_jingsai
前两年百度的大数据竞赛都是自然语言处理方面的,今年画风一转,变成了图像的细颗粒度分类,赛题内容就是将宠物狗归为100类中的其中一类。这个任务本身是很平凡的,做法也很常规,无外乎就是数据扩增、imagenet模型的fine tune、模型集成三个方面。笔者并不擅长于模型集成,只做了前面两个步骤,成绩也非常一般(准确率80%上下)。但感觉里边的某些代码可能对读者有帮助,遂共享一翻。下面结合着代码来讲解。
比赛官网(随时有失效的可能):http://js.baidu.com
模型
模型主要用tensorflow+keras实现。首先自然是导入各种模块
#! -*- coding:utf-8 -*-
import numpy as np
from scipy import misc
import tensorflow as tf
from keras.applications.xception import Xception,preprocess_input
from keras.layers import Input,Dense,Lambda,Embedding
from keras.layers.merge import multiply
from keras import backend as K
from keras.models import Model
from keras.optimizers import SGD
from tqdm import tqdm
import glob
np.random.seed(2017)
tf.set_random_seed(2017)
14
Oct
训练集、验证集和测试集的意义
By 苏剑林 | 2017-10-14 | 50142位读者 | 引用
19
Nov
更别致的词向量模型(一):simpler glove
By 苏剑林 | 2017-11-19 | 42078位读者 | 引用如果问我哪个是最方便、最好用的词向量模型,我觉得应该是word2vec,但如果问我哪个是最漂亮的词向量模型,我不知道,我觉得各个模型总有一些不足的地方。且不说试验效果好不好(这不过是评测指标的问题),就单看理论也没有一个模型称得上漂亮的。
本文讨论了一些大家比较关心的词向量的问题,很多结论基本上都是实验发现的,缺乏合理的解释,包括:
如果去构造一个词向量模型?
为什么用余弦值来做近义词搜索?向量的内积又是什么含义?
词向量的模长有什么特殊的含义?
为什么词向量具有词类比性质?(国王-男人+女人=女王)
得到词向量后怎么构建句向量?词向量求和作为简单的句向量的依据是什么?
这些讨论既有其针对性,也有它的一般性,有些解释也许可以直接迁移到对glove模型和skip gram模型的词向量性质的诠释中,读者可以自行尝试。
围绕着这些问题的讨论,本文提出了一个新的类似glove的词向量模型,这里称之为simpler glove,并基于斯坦福的glove源码进行修改,给出了本文的实现,具体代码在Github上。

最近评论