






26
May
胡闹的胜利:将算子引入级数求和
By 苏剑林 | 2015-05-26 | 23636位读者 | 引用在文章《有趣的求极限题:随心所欲的放缩》中,读者“最近倒了”提出了一个新颖的解法,然而这位读者写得并非特别清晰,更重要的是里边的某些技巧似乎是笔者以前没有见过的,于是自行分析了一番,给出了以下解释。
胡闹的结果
假如我们要求级数和
$$\sum_{k=0}^n \binom{n}{k}\frac{A_k}{n^k}$$
这里$A_0=1$。一般而言,我们用下标来标注不同的数,如上式的$A_k,\,k=0,1,2,\dots$,可是有的人偏不喜欢,他们更喜欢用上标来表示数列中的各项,他们把上面的级数写成
$$\sum_{k=0}^n \binom{n}{k}\frac{A^k}{n^k}$$
可能读者就会反对了:这不是胡闹吗,这不是让它跟分母的n的k次幂混淆了吗?可是那人干脆更胡闹一些,把级数写成
$$\sum_{k=0}^n \binom{n}{k}\frac{A^k}{n^k}=\left(1+\frac{A}{n}\right)^n$$
看清楚了吧?他干脆把$A$当作一个数来处理了!太胡闹了,$A$是个什么东西?估计这样的孩子要被老师赶出课堂的了。
可是换个角度想想,似乎未尝不可。
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 67954位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
10
Jun
【翻译】巨型望远镜:要继续,就得有牺牲!
By 苏剑林 | 2015-06-10 | 27333位读者 | 引用
2007年末公布的30米望远镜效果图
文章来自:新科学家,这是一篇关于30米望远镜(Thirty Meter Telescope,TMT)的新闻,起因是望远镜的制造遭到当地人的不满,当然背后的原因是很深远的,难以说清楚。更多有关TMT的新闻,可以阅读:http://www.ctmt.org/
夏威夷的巨型望远镜:要继续,就得有牺牲!
四分之一必须离开!在停止了两个月之后,夏威夷的巨型30米望远镜(Thirty Meter Telescope,TMT)重新回归到建设进程——但要牺牲其他望远镜。
由于夏威夷当地居民的抗议声越来越大,早在四月望远镜的建设工作就被迫暂停。与该望远镜相比,目前世界上所有的望远镜都相形见绌——它让能够让天文学家们凝视可见的宇宙的边缘。它位于许多夏威夷人认为是“神圣之地”的死火山莫纳克亚山,因此被夏威夷人认为是一种侮辱——尤其是在山顶已经有十多个望远镜了。
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 223538位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
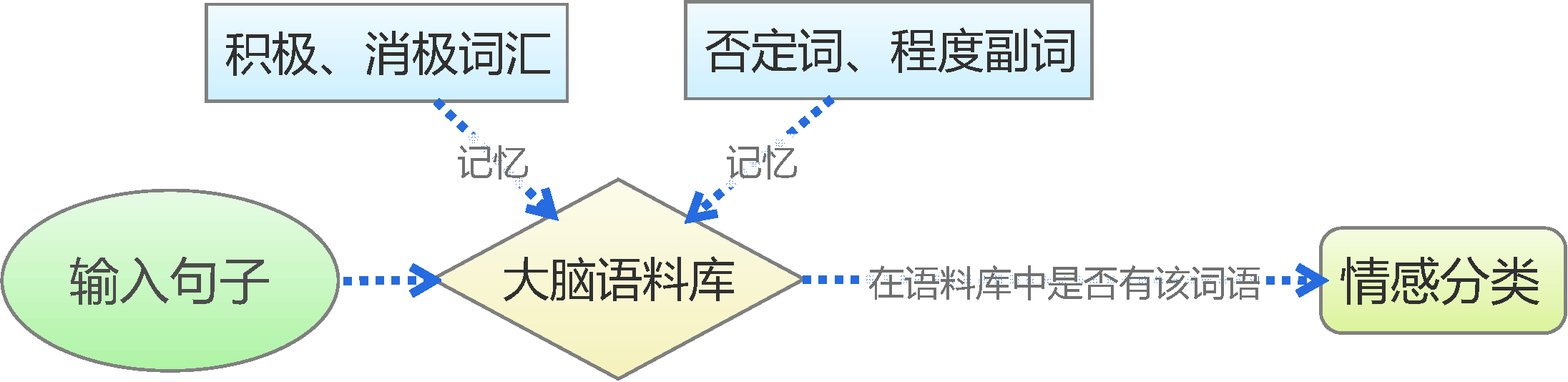
人的最简单的判断思维
2
Jul
用Pandas实现高效的Apriori算法
By 苏剑林 | 2015-07-02 | 141365位读者 | 引用最近在做数据挖掘相关的工作,阅读到了Apriori算法。平时由于没有涉及到相关领域,因此对Apriori算法并不了解,而如今工作上遇到了,就不得不认真学习一下了。Apriori算法是一个寻找关联规则的算法,也就是从一大批数据中找到可能的逻辑,比如“条件A+条件B”很有可能推出“条件C”(A+B-->C),这就是一个关联规则。具体来讲,比如客户买了A商品后,往往会买B商品(反之,买了B商品不一定会买A商品),或者更复杂的,买了A、B两种商品的客户,很有可能会再买C商品(反之也不一定)。有了这些信息,我们就可以把一些商品组合销售,以获得更高的收益。而寻求关联规则的算法,就是关联分析算法。
啤酒与尿布

啤酒与尿布
关联算法的案例中,最为人老生常谈的应该是“啤酒与尿布”了。“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,超市管理人员发现“啤酒与尿布两件看上去毫无关系的商品会经常出现在同一个购物篮中”。经过分析,原来在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。因此,沃尔玛尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品。事实是效果相当不错!
4
Aug
文本情感分类(二):深度学习模型
By 苏剑林 | 2015-08-04 | 603884位读者 | 引用
13
Aug
exp(1/2 t^2+xt)级数展开的图解技术
By 苏剑林 | 2015-08-13 | 31065位读者 | 引用本文要研究的是关于$t$的函数
$$\exp\left(\frac{1}{2}t^2+xt\right)$$
在$t=0$处的泰勒展开式。显然,它并不困难,手算或者软件都可以做出来,答案是:
$$1+x t+\frac{1}{2} \left(x^2+1\right) t^2+\frac{1}{6}\left(x^3+3 x\right) t^3 +\frac{1}{24} \left(x^4+6 x^2+3\right) t^4 + \dots$$
不过,本文将会给出笔者构造的该级数的一个图解方法。通过这个图解方法比较比较直观而方便地手算出展开式的前面一些项。后面我们再来谈谈这种图解技术的起源以及进一步的应用。
级数的图解方法:说明
首先,很明显要写出这个级数,关键是写出展开式的每一项,也就是要求出
$$f_k (x) = \left.\frac{d^k}{dt^k}\exp\left(\frac{1}{2}t^2+xt\right)\right|_{t=0}$$
$f_k (x)$是一个关于$x$的$k$次整系数多项式,$k$是展开式的阶,也是求导的阶数。
这里,我们用一个“点”表示一个$x$,用“两点之间的一条直线”表示“相乘”,那么,$x^2$就可以表示成

x^2项
5
Oct


最近评论