






9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 62537位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计$x$的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本$x_1,x_2,\cdots,x_N\sim \tilde{p}(x)$的情况下,用一个待定的概率密度簇$q_{\theta}(x)$去拟合这批样本,拟合的目标一般是最小化负对数似然:
\begin{equation}\mathbb{E}_{x\sim \tilde{p}(x)}[-\log q_{\theta}(x)] = -\frac{1}{N}\sum_{i=1}^N \log q_{\theta}(x_i)\label{eq:mle}\end{equation}
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 65613位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
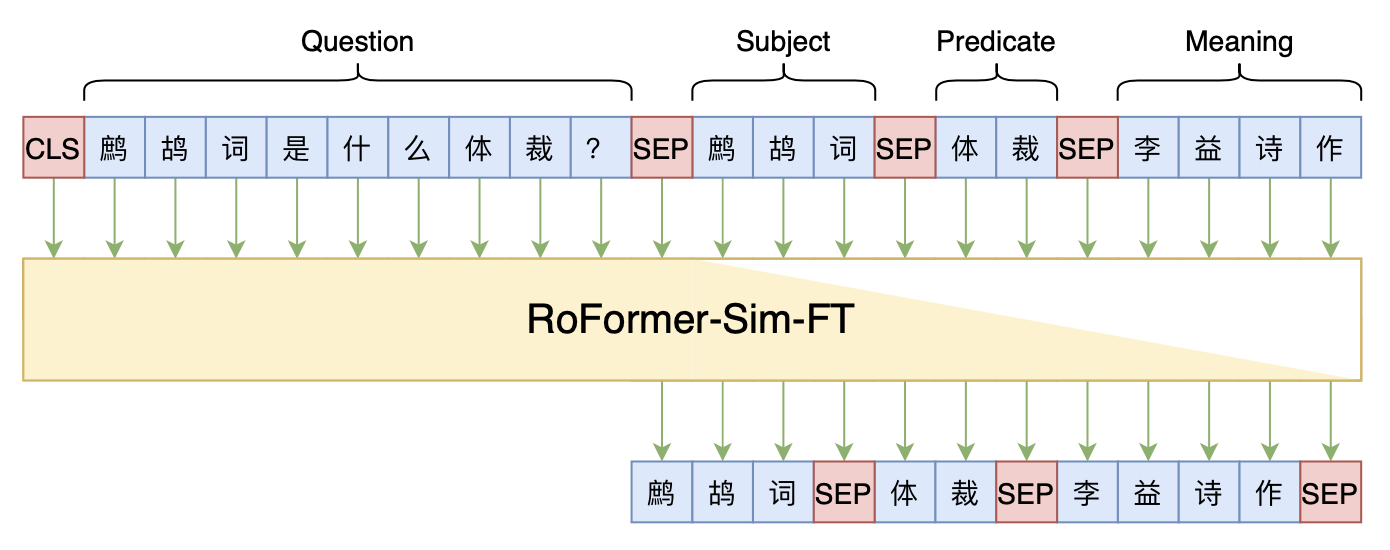
本文baseline模型示意图
25
Jan
Efficient GlobalPointer:少点参数,多点效果
By 苏剑林 | 2022-01-25 | 120435位读者 | 引用在《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》中,我们提出了名为“GlobalPointer”的token-pair识别模块,当它用于NER时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比CRF更快的速度和不逊色于CRF的效果。换言之,就目前的实验结果来看,至少在NER场景,我们可以放心地将CRF替换为GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出GlobalPointer的一个改进版——Efficient GlobalPointer,它主要针对原GlobalPointer参数利用率不高的问题进行改进,明显降低了GlobalPointer的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的Efficient GlobalPointer反而还取得更好的效果。
大量的参数
这里简单回顾一下GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》。简单来说,GlobalPointer是基于内积的token-pair识别模块,它可以用于NER场景,因为对于NER来说我们只需要把每一类实体的“(首, 尾)”这样的token-pair识别出来就行了。
11
Mar
门控注意力单元(GAU)还需要Warmup吗?
By 苏剑林 | 2022-03-11 | 44262位读者 | 引用在文章《训练1000层的Transformer究竟有什么困难?》发布之后,很快就有读者问到如果将其用到《FLASH:可能是近来最有意思的高效Transformer设计》中的“门控注意力单元(GAU)”,那结果是怎样的?跟标准Transformer的结果有何不同?本文就来讨论这个问题。
先说结论
事实上,GAU是非常容易训练的模型,哪怕我们不加调整地直接使用“Post Norm + Xavier初始化”,也能轻松训练个几十层的GAU,并且还不用Warmup。所以关于标准Transformer的很多训练技巧,到了GAU这里可能就无用武之地了...
为什么GAU能做到这些?很简单,因为在默认设置之下,理论上$\text{GAU}(\boldsymbol{x}_l)$相比$\boldsymbol{x}_l$几乎小了两个数量级,所以
\begin{equation}\boldsymbol{x}_{l+1} = \text{LN}(\boldsymbol{x}_l + \text{GAU}(\boldsymbol{x}_l))\approx \boldsymbol{x}_l\end{equation}
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 75034位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
18
May
当BERT-whitening引入超参数:总有一款适合你
By 苏剑林 | 2022-05-18 | 39078位读者 | 引用在《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者提出了BERT-whitening,验证了一个线性变换就能媲美当时的SOTA方法BERT-flow。此外,BERT-whitening还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
为了弥补这个不足,本文提出往BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上whitening后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。
方法概要
目前BERT-whitening的流程是:
\begin{equation}\begin{aligned}
\tilde{\boldsymbol{x}}_i =&\, (\boldsymbol{x}_i - \boldsymbol{\mu})\boldsymbol{U}\boldsymbol{\Lambda}^{-1/2} \\
\boldsymbol{\mu} =&\, \frac{1}{N}\sum\limits_{i=1}^N \boldsymbol{x}_i \\
\boldsymbol{\Sigma} =&\, \frac{1}{N}\sum\limits_{i=1}^N (\boldsymbol{x}_i - \boldsymbol{\mu})^{\top}(\boldsymbol{x}_i - \boldsymbol{\mu}) = \boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{\top} \,\,(\text{SVD分解})
\end{aligned}\end{equation}
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 137964位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
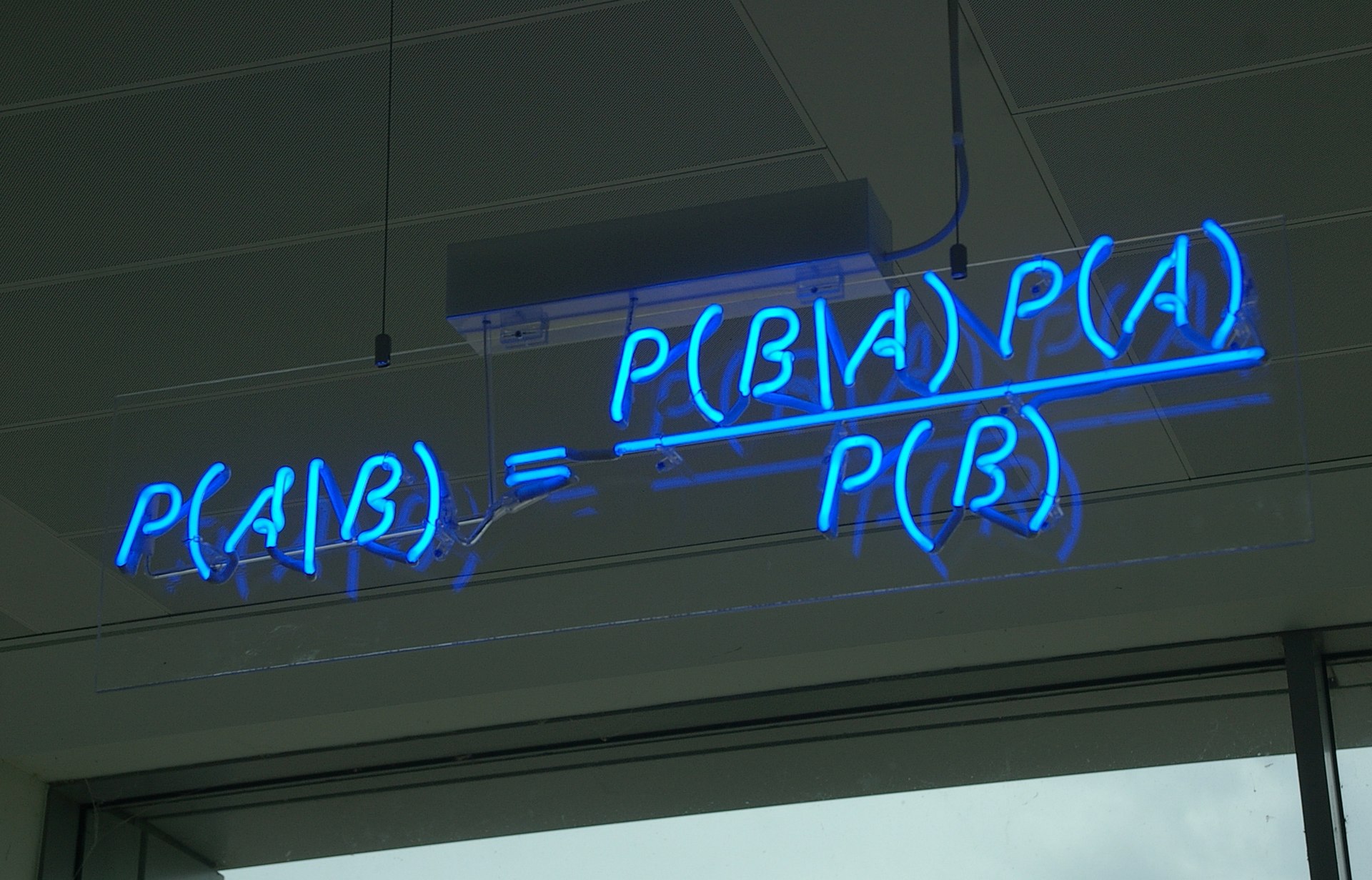
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 38620位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。

最近评论