






12
Sep
数学竞赛广东预赛|组成三角形的概率
By 苏剑林 | 2011-09-12 | 56042位读者 | 引用九月三日BoJone和九个同学到云浮参加了今年广东省的数学竞赛预赛,那一起出发、玩笑、作战、吃饭的情景依然历历在目,让我久久不能忘怀。是呀,能够并肩作战的感觉真好!九日数学成绩出来了,遗憾的是今年政策改变了,我被告知整个市只有三个名额能够参加复赛,于是新兴只有我一个人进入了复赛(另外两个据说是罗定的,我们三个并列第一)。有点无语,我想,大概是要把那些为了功利而参赛的人都给刷下去吧...
今年广东的预赛题前所未有的简单,不论是和全国其他地方相比还是和上一年的题目相比,都简单了不少,但我还是做得不大理想,据我估计,120分的卷子我顶多能够拿个68分,所以BoJone的基本技能实在不容乐观。从云浮考试回来后,和同行的同学讨论试题,得出了一些很有趣的结果,那过程可谓其乐无穷呀!下面是倒数第二题预赛题的几个绝妙解法,供大家欣赏。解法由我和伍泽麒(人称“兔子、神兔”,人如其名,天资聪颖,性格可爱)完成。
题目:
在一条线段中随意选取两个点,把这条线段截成三段,求这三段线段能够组成一个三角形的概率。
3
Jul
求多边形外角和的绝妙方法!
By 苏剑林 | 2012-07-03 | 44052位读者 | 引用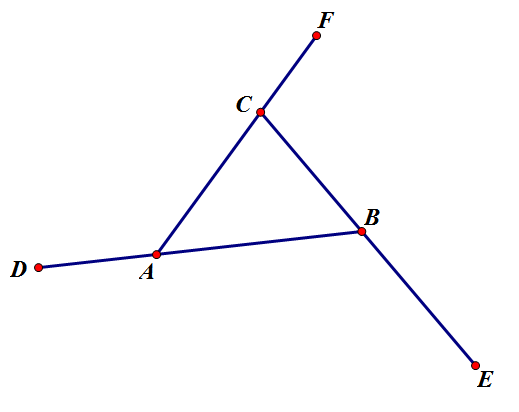
20
Jul
“未解之谜”:为何不讲中点矩形法则?
By 苏剑林 | 2012-07-20 | 52667位读者 | 引用前言
在之前的一些文章中,我们已经指出过现行教材的一些毛病。比如主次不当(最明显的是那些一上来就讲线性方程组的线性代数教程)、缺乏直观性、缺少引导性等,我想其中最主要的原因可能是过于随大流了,别人怎么编我们也跟着怎么编,缺乏自己的观点和逻辑,因此导致一些常见的毛病就一直流传了下来。也许正因如此,就导致了有那么一种奇怪的现象——明明有一种计算量少的、精确度高一些的方法,教科书几乎从未提及;另外一种计算量稍大、精确度稍低的方法,但每一本同类教科书都讲述了它。不能不说这是一个“未解之谜”......
本文要讲的就是这样的两种方法,它们分别是用来求定积分近似值的“中点矩形法则”和“梯形法则”。对于后者我想绝大多数学习过微积分的朋友都会有印象,它就是那个几乎出现在了所有微积分教材的方法;而前者我相信不少读者都未曾听闻,但让人意外的是,它的计算量稍低,精确度却稍高。本文就简单介绍这两种方法,并且比较它们的精度。而本文的独特之处在于,证明过程沿用了《复分析:可视化方法》的思路,使用几何方法漂亮地估计误差!
我们的目标是在难以精确计算的情况下,通过一定的方法求出$\int_a^b f(x)dx$的近似值,这些方法基本上都是利用了积分即面积的思想。
两种不同的方法
5
Jan
不确定性原理的矩阵形式
By 苏剑林 | 2014-01-05 | 40352位读者 | 引用作为量子理论的一个重要定理,不确定性原理总是伴随着物理意义出现的,但是从数学的角度来讲,把不确定性原理的数学形式抽象出来,有助于我们发现更多领域的“不确定性原理”。
本文中,我们将谈及不确定性原理的n维矩阵形式。首先需要解释给大家的是,不确定性原理其实是关于“两个厄密算符与一个单位向量之间的一条不等式”。在量子力学中,厄密算符对应着无穷维的厄密矩阵;而所谓厄密矩阵,就是一个矩阵同时取共轭和转置之后,等于它自身。但是本文讨论一个更简单的情况,那就是n维实矩阵,n维实矩阵中的厄密矩阵就是我们所说的实对称矩阵了。
设$\boldsymbol{x}$是一个$n$维单位向量,即$|\boldsymbol{x}|=1$,而$\boldsymbol{A}$和$\boldsymbol{B}$是n阶实对称矩阵。在量子力学中,$\boldsymbol{x}$就是波函数,但是在这里,它只不过是一个单位实向量;并记$\boldsymbol{I}$是$n$阶单位阵。
考虑
$$\bar{A}=\boldsymbol{x}^{T}\boldsymbol{A}\boldsymbol{x},\bar{B}=\boldsymbol{x}^{T}\boldsymbol{B}\boldsymbol{x}$$
从这些记号可以看出,这些量对应着可观测量的期望值。当然,如果不懂量子力学,可以只看上面的矩阵形式。
20
Feb
熵的形象来源与熵的妙用
By 苏剑林 | 2016-02-20 | 30498位读者 | 引用在拙作《“熵”不起:从熵、最大熵原理到最大熵模型(一)》中,笔者从比较“专业”的角度引出了熵,并对熵做了诠释。当然,熵作为不确定性的度量,应该具有更通俗、更形象的来源,本文就是试图补充这一部分,并由此给出一些妙用。
熵的形象来源
我们考虑由0-9这十个数字组成的自然数,如果要求小于10000的话,那么很自然有10000个,如果我们说“某个小于10000的自然数”,那么0~9999都有可能出现,那么10000便是这件事的不确定性的一个度量。类似地,考虑$n$个不同元素(可重复使用)组成的长度为$m$的序列,那么这个序列有$n^m$种情况,这时$n^m$也是这件事情的不确定性的度量。
$n^m$是指数形式的,数字可能异常地大,因此我们取了对数,得到$m\log n$,这也可以作为不确定性的度量,它跟我们原来熵的定义是一致的。因为
$$m\log n=-\sum_{i=1}^{n^m} \frac{1}{n^m}\log \frac{1}{n^m}$$
读者可能会疑惑,$n^m$和$m\log n$都算是不确定性的度量,那么究竟是什么原因决定了我们用$m\log n$而不是用$n^m$呢?答案是可加性。取对数后的度量具有可加性,方便我们运算。当然,可加性只是便利的要求,并不是必然的。如果使用$n^m$形式,那么就相应地具有可乘性。
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 198319位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
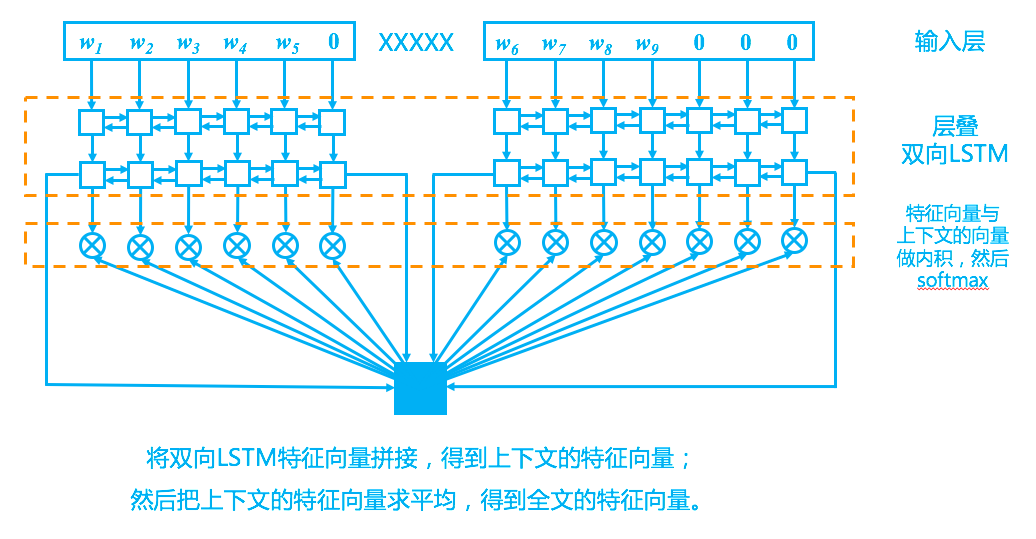
完形填空模型
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 48036位读者 | 引用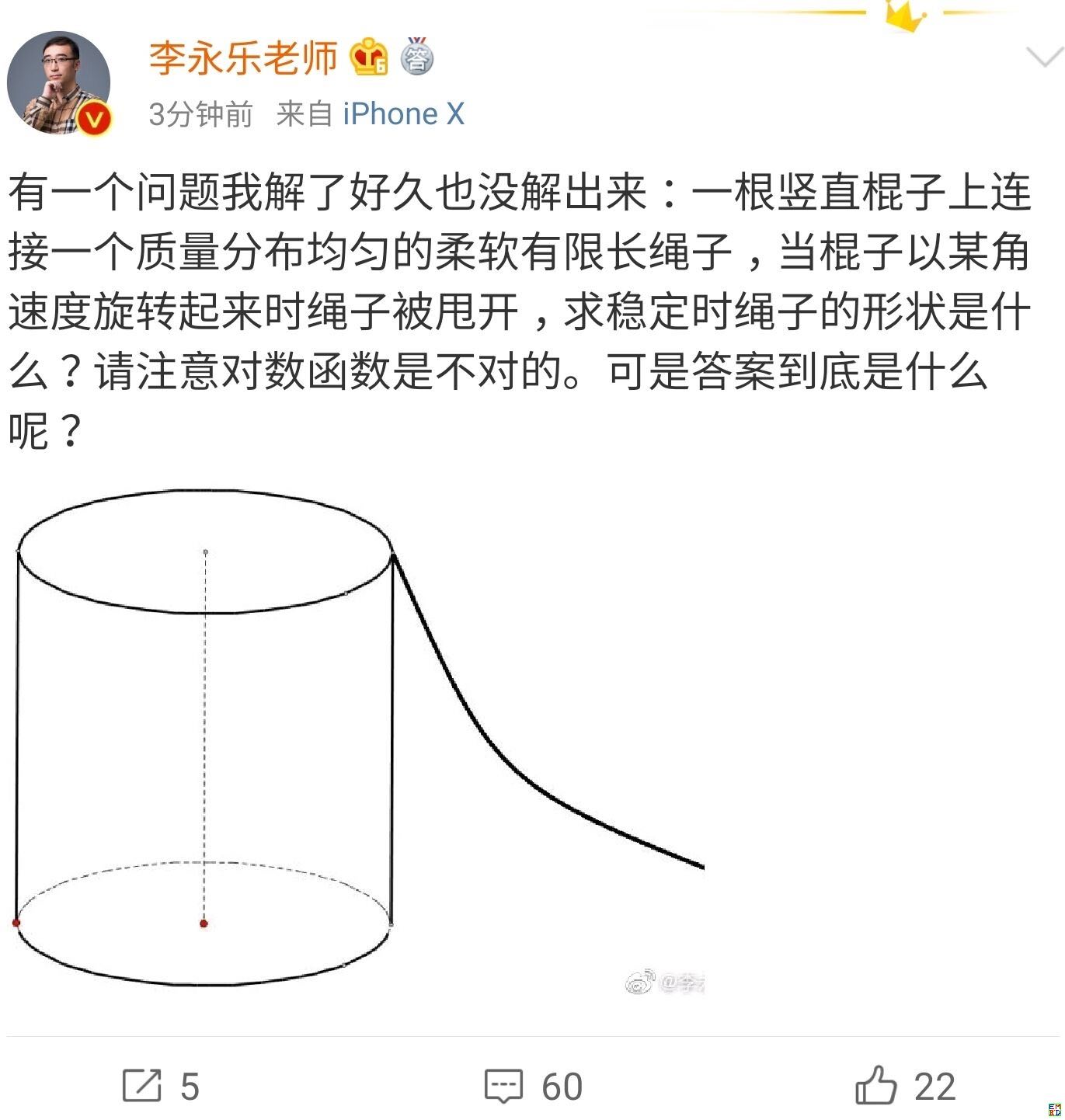
25
Oct


最近评论