






7
Jun
通用爬虫探索(三):效果展示与代码
By 苏剑林 | 2017-06-07 | 53718位读者 | 引用
24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 91779位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。
代码
8
Aug
【备忘】谈谈dropout
By 苏剑林 | 2017-08-08 | 32905位读者 | 引用其实这只是一篇备忘...
dropout是深度学习中防止过拟合的一项有效措施,当然,就其思想而言,dropout其实也不仅仅可以用在深度学习中,还可以用在传统的机器学习方法中,只不过在深度学习的神经网络框架下,dropout显得更为自然罢了。
做了什么
dropout是怎么操作的?一般来做,对于输入的张量$x$,dropout就是将部分元素置零,然后将置零后的结果做一个尺度变换。具体来说,以Keras的Dropout(0.6)(x)为例,实际上等价于numpy做的这件事情
import numpy as np
x = np.random.random((10,100)) #模拟一个batch_size=10、维度为100的输入
def Dropout(x, drop_proba):
return x*np.random.choice(
[0,1],
x.shape,
p=[drop_proba,1-drop_proba]
)/(1.-drop_proba)
print Dropout(x, 0.6)
3
Sep
开学啦!咱们来做完形填空~(讯飞杯)
By 苏剑林 | 2017-09-03 | 200677位读者 | 引用前言
从今年开始,CCL会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第6,验证集准确率为73.55%,测试集准确率为75.77%,大家可以在这里观摩排行榜。(“广州火焰信息科技有限公司”就是文本的模型)
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文《Consensus Attention-based Neural Networks for Chinese Reading Comprehension》就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的GTX1060上可以跑到batch size为160),便于实验。
模型
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
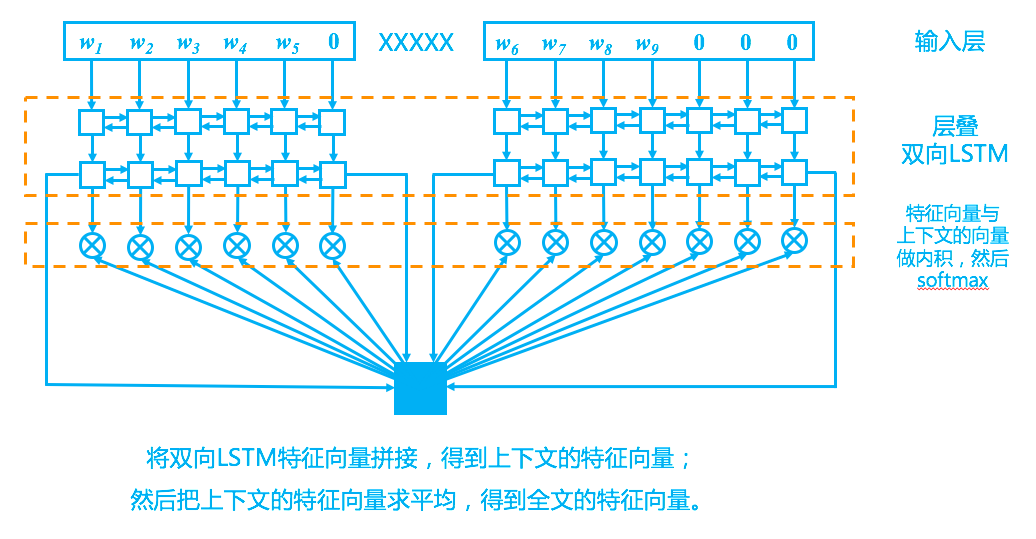
完形填空模型
3
Jul
《交换代数导引》参考答案
By 苏剑林 | 2017-07-03 | 35140位读者 | 引用这学期我们的一门课是《交换代数》,是本科抽象代数的升级版。我们用的教材是Atiyah的《Introduction to Commutative Algebra》(交换代数导引),而且根据老师的上课安排,还需要我们把部分课后习题完成并讲解...不得不说这门课上得真累啊~
习题做到后面,我干脆懒得起草稿了,直接把做的答案用LaTeX录入了,既方便排版也方便修改。在这里分享给有需要的读者~答案是用中文写的,注释比较详细,适合刚学这门课的同学~
笔者所做的部分:《交换代数导引》参考答案.pdf
当然这份答案只包括老师对我们的要求的那部分习题,下面是网上搜索到的完整的习题解答,英文版的:
网上找到的答案:Jeffrey Daniel Kasik Carlson - Exercises to Atiya.pdf
如果答案有问题,欢迎留言指出。
16
Jul
Linux下的误删大坑与简单的恢复技巧
By 苏剑林 | 2017-07-16 | 28455位读者 | 引用
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 428875位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。
16
Oct
如何划分一个跟测试集更接近的验证集?
By 苏剑林 | 2020-10-16 | 56246位读者 | 引用不管是打比赛、做实验还是搞工程,我们经常会遇到训练集与测试集分布不一致的情况。一般来说我们会从训练集中划分出来一个验证集,通过这个验证集来调整一些超参数(参考《训练集、验证集和测试集的意义》),比如控制模型的训练轮数以防止过拟合。然而,如果验证集本身跟测试集差别比较大,那么验证集上很好的模型也不代表在测试集上很好,因此如何让划分出来验证集跟测试集的分布差异更小一些,是一个值得研究的题目。
两种情况
首先,明确一下,本文所考虑的,是能给拿到测试集数据本身、但不知道测试集标签的场景。如果是那种提交模型封闭评测的场景,我们完全看不到测试集的,那就没什么办法了。为什么会出现测试集跟训练集分布不一致的现象呢?主要有两种情况。

最近评论